
Novita AI 基于 SGLang 为 GLM4-MoE 模型开发了一套经过生产验证的高影响力优化方案。我们提出端到端性能优化策略,覆盖从内核执行效率到跨节点数据传输调度的整个推理流程。通过集成 Shared Experts Fusion 与 Suffix Decoding,在代理编码工作负载下实现了关键指标的大幅提升。
核心生产优化实现
1. Shared Experts Fusion
该优化源于 Deepseek 模型相关工作。GLM4.7 将所有输入 token 通过共享专家,同时每个 token 还会被路由到 top-k 专家,最终加权聚合输出。通过将共享专家合并到路由 MoE 结构中(从 161 个专家中选 top 9),在 TP8 FP8 配置下显著提升 SM 利用率并减少内存 I/O 开销。
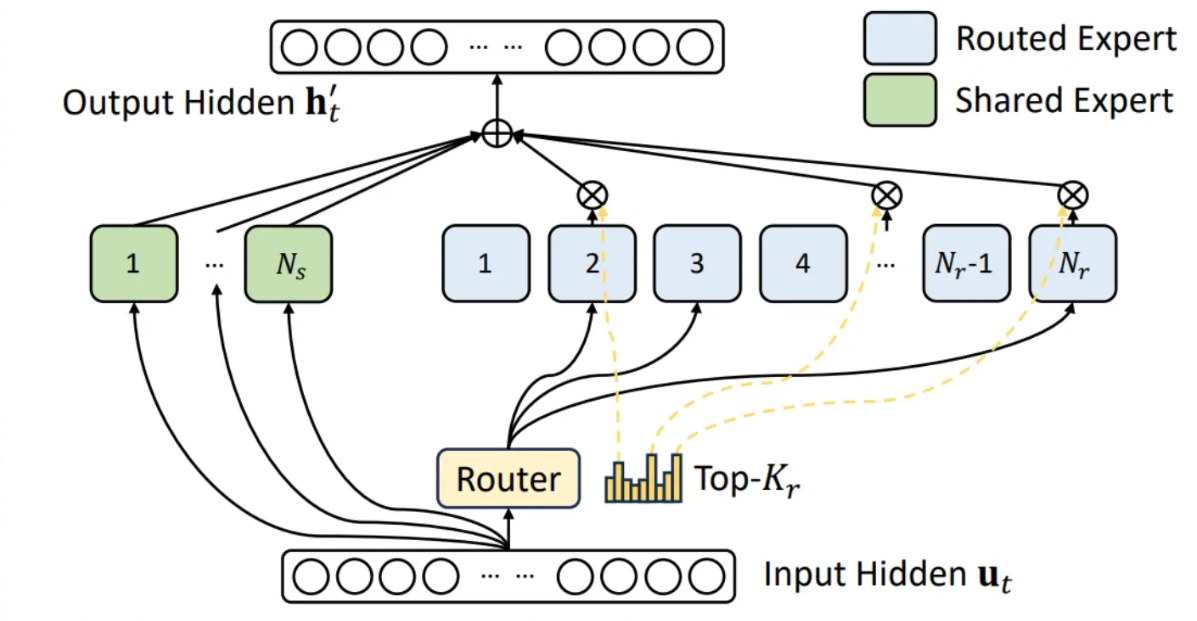
该优化可带来最高 23.7% TTFT 和 20.8% ITL 提升。
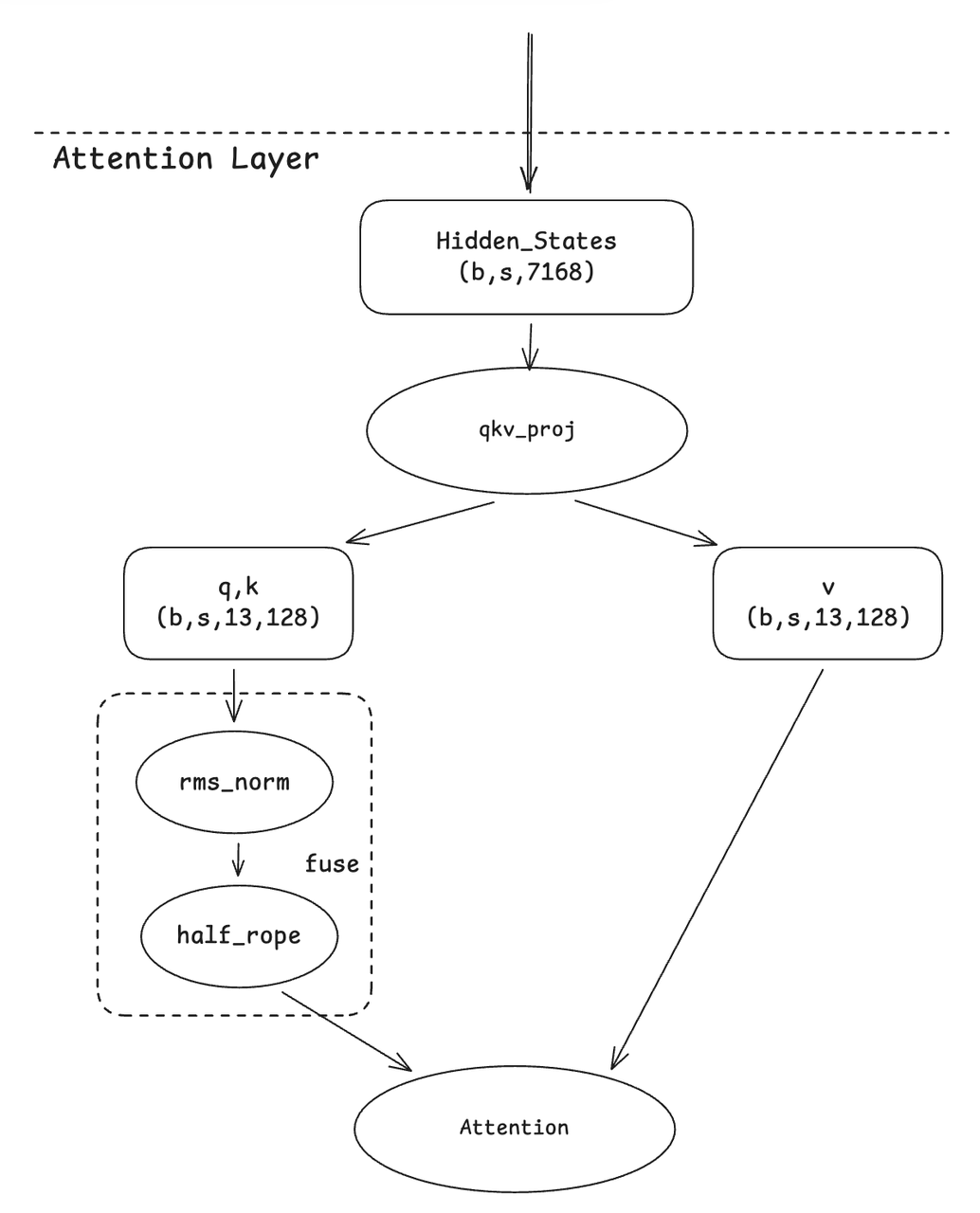
2. Qknorm Fusion
基于 Qwen-MoE 优化思路,将 head-wise 计算的算子融合为单一内核,适配 GLM4-MoE 仅对 head 内一半维度进行旋转的特性。
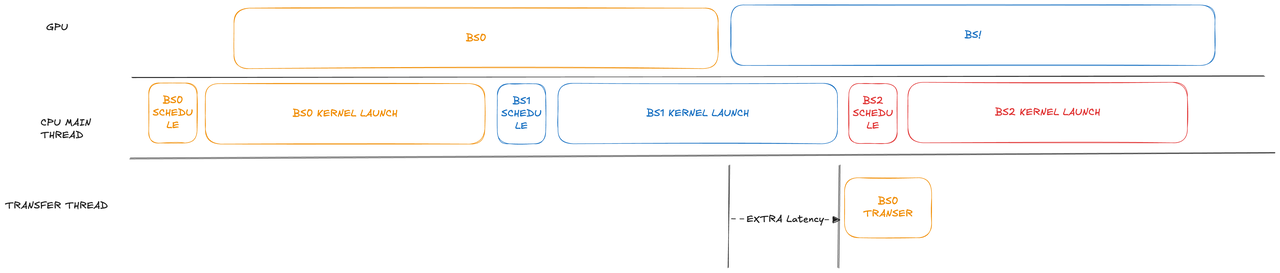
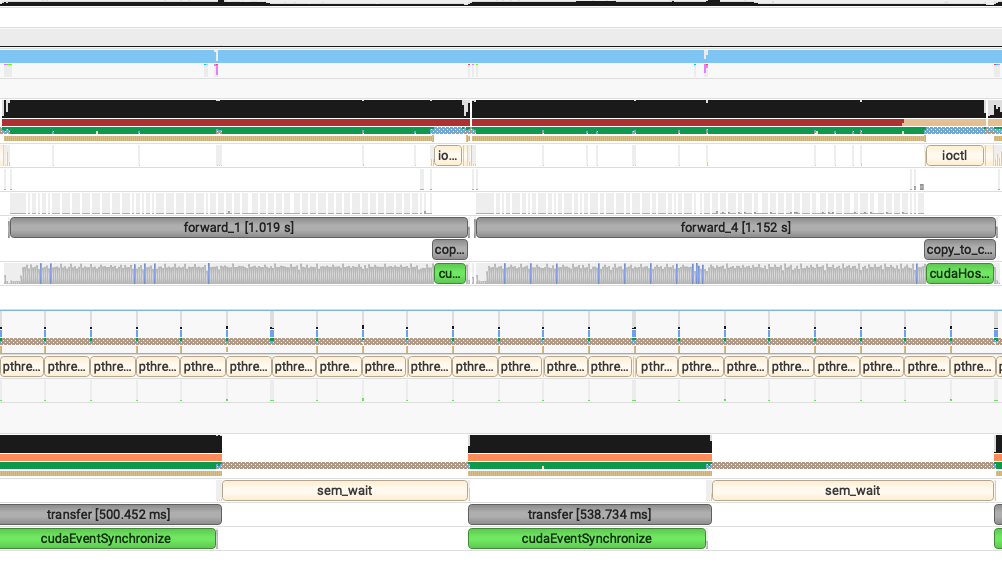
3. Async Transfer
在 PD 分离重叠调度场景下,提前调度数据传输并置于独立线程,避免主线程阻塞。针对 92 层模型,可在重负载下节省高达 1 秒 TTFT。
生产基准测试结果
测试配置:输入长度 4096,输出长度 1000,请求率 14 req/s,模型 GLM-4.7 FP8 (TP8)。
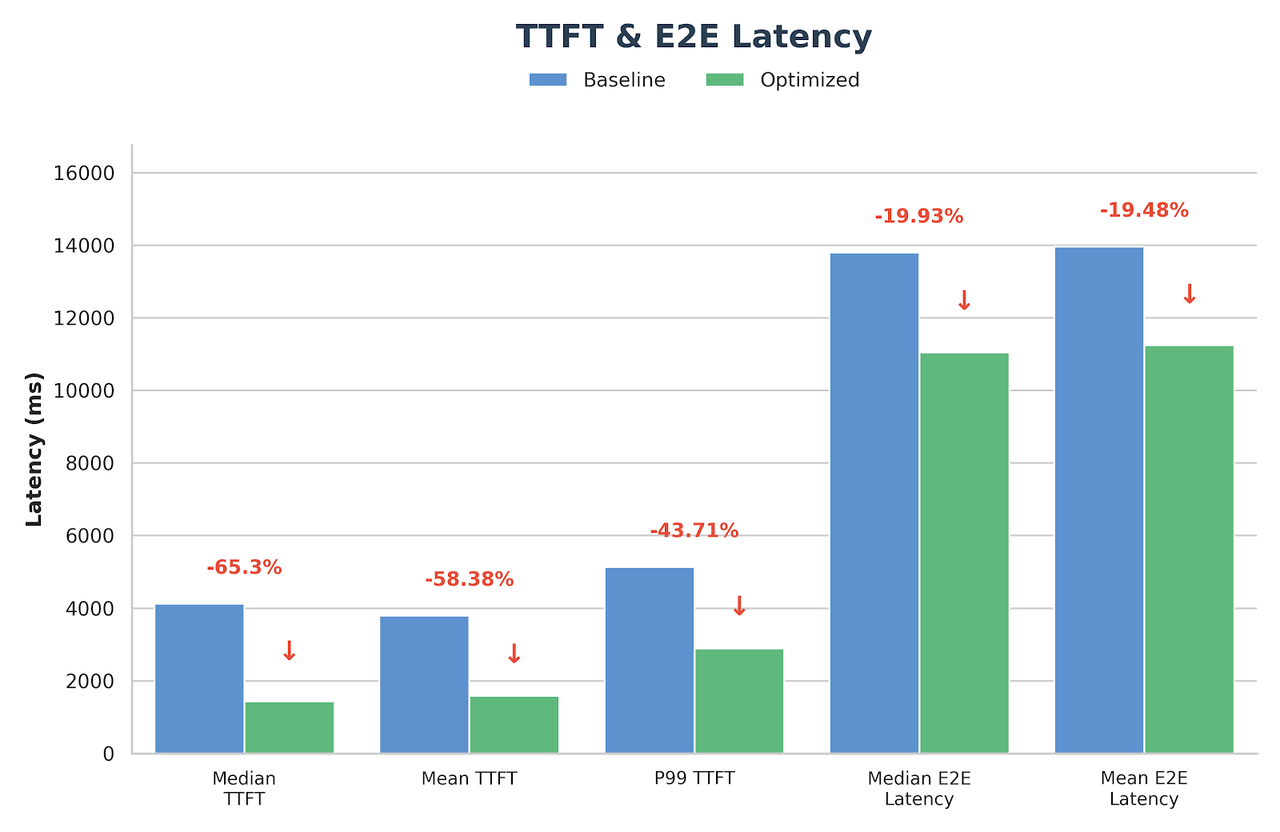
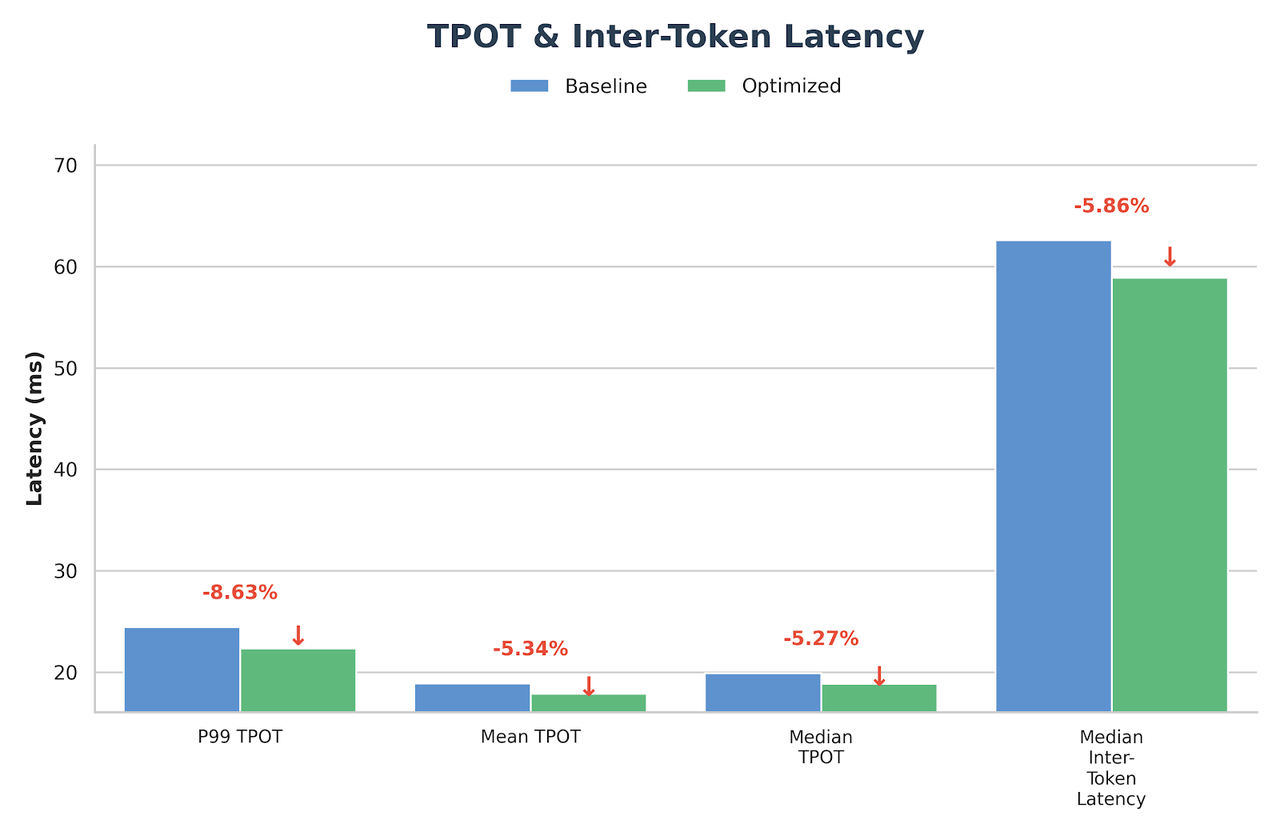
Suffix Decoding
在代理编码场景中,Suffix Decoding 无需额外模型权重,利用历史输出模式进行推测解码,进一步降低 TPOT 22%(从 25.13ms 降至 19.63ms)。
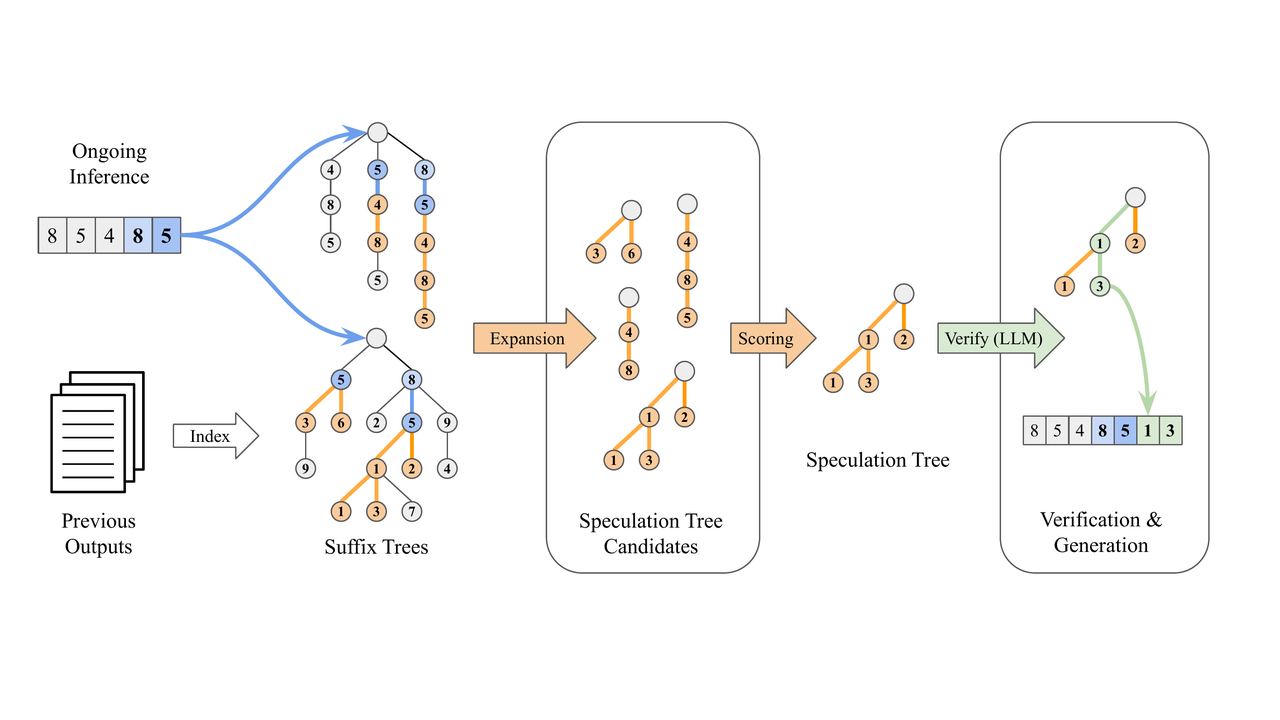
总结
这些优化已部署于 Novita AI 生产推理服务,多数组件已合并至 SGLang 上游仓库。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接