A journey of a thousand miles begins with a single step.
Today, we release Miles, an enterprise-grade reinforcement learning framework designed for large-scale MoE training and production workloads.
Miles is built on slime, a lightweight RL framework that has quietly powered many of today's post-training pipelines and large model MoE training (such as GLM-4.6). While slime validated the effectiveness of lightweight design, Miles takes the next step: providing the reliability, scalability, and control required for real enterprise deployment.
GitHub: radixark/miles.
Why Choose Miles?
Every journey of progress starts with a precise step—slime is just that. As a highly lightweight and customizable RL framework, slime quickly gained popularity in the community and was battle-tested in GLM-4.6's large-scale MoE training. slime follows several elegant design principles:
Out-of-the-Box Performance
Provides native structured support for the complete optimization stack of SGLang and Megatron, keeping pace with rapid developments in inference and training frameworks.
Modular Design
Core components—Algorithm, Data, Rollout, and Eval—are fully decoupled. New agent types, reward functions, or sampling strategies can be integrated with minimal code modifications.
Built for Researchers
Every abstraction layer is readable and modifiable. Algorithm researchers can adjust importance sampling, rollout logic, or loss dynamics without diving into low-level code. We also provide pure inference and pure training debug modes for quick diagnostics.
Community-Driven
slime originated from real-world feedback from the LMSYS and SGLang communities, embodying the results of open collaboration between research and engineering.
New Feature Highlights
Building on slime's foundation, Miles is optimized for new hardware (like GB300), large-scale MoE RL, and production-grade stability. Recent additions (most upstream contributed back to slime) include:
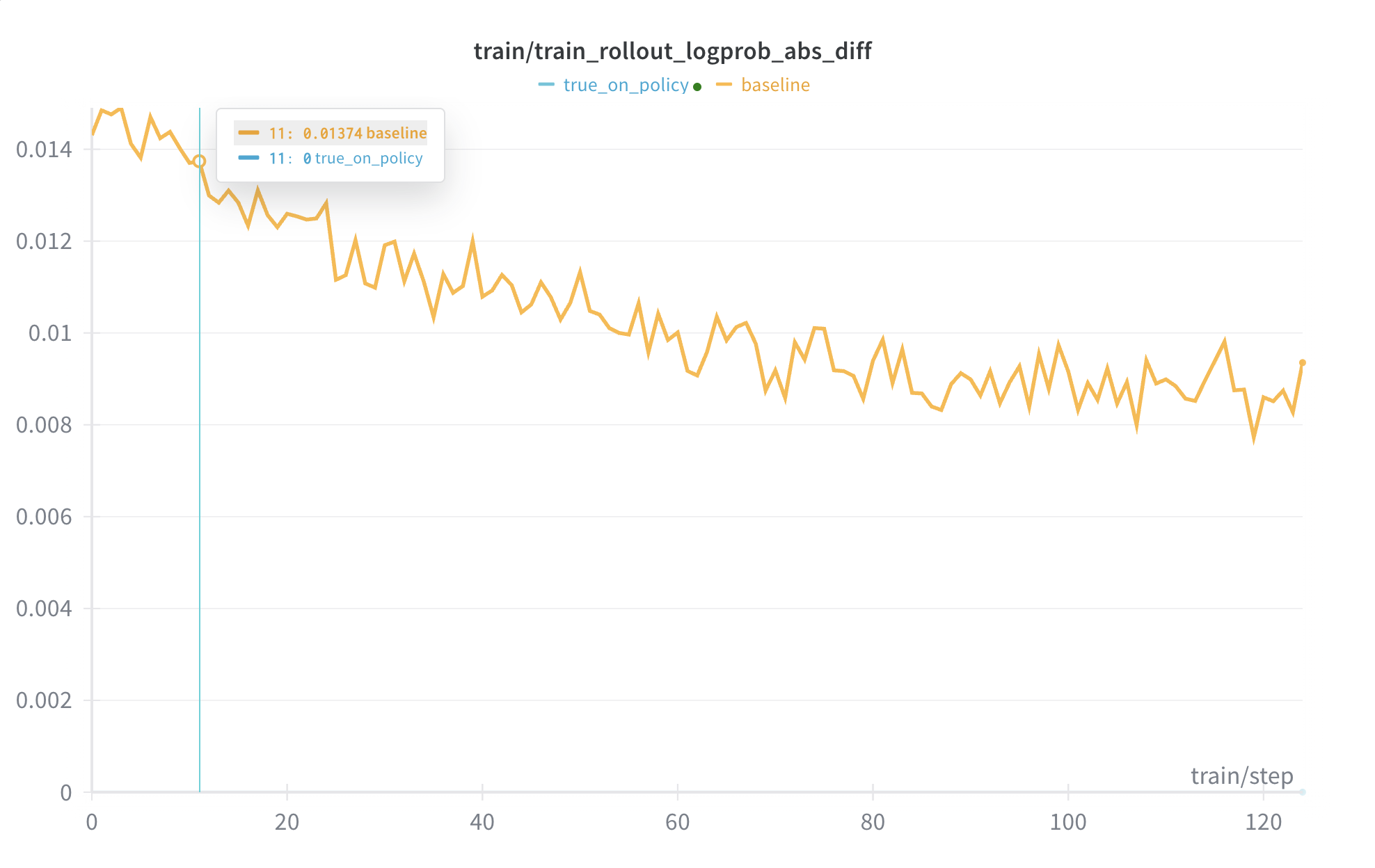
True On-Policy Support
Going beyond deterministic inference (bit-identical results), we now achieve true on-policy through infrastructure: true_on_policy example.
- Eliminates discrepancies between training and inference, making KL divergence exactly 0.
- Employs Flash Attention 3, DeepGEMM, batch invariant kernels from Thinking Machines Lab, and
torch.compile, aligning numerical operations between training and inference.
Memory Optimization
To maximize performance and avoid OOM errors, we've made multiple improvements:
- Added error propagation to prevent benign OOM crashes.
- Implemented memory headroom, fixing NCCL-related OOM.
- Fixed FSDP excessive memory usage.
- Support for move-based and partial offloading, and host peak memory savings.
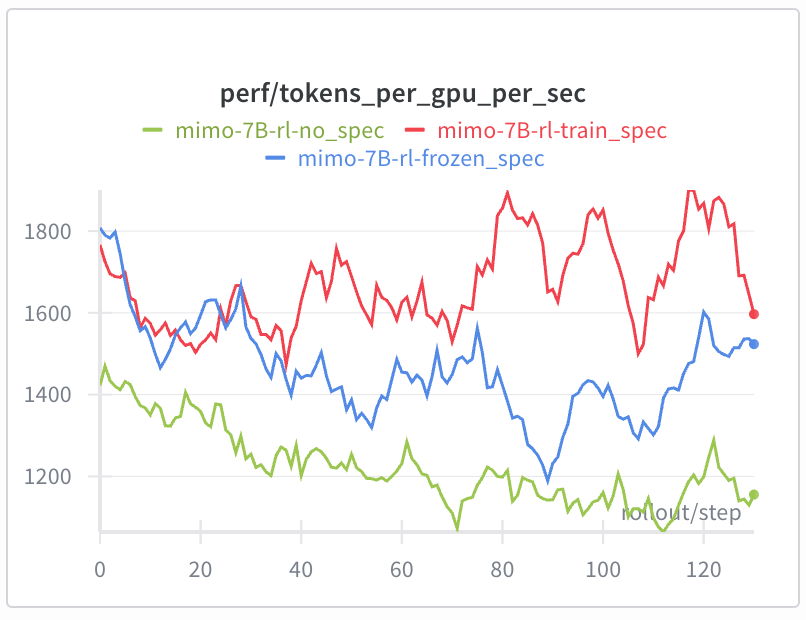
Speculative Decoding with Online Draft Model Training
Frozen draft models in RL deviate from target model policies, reducing acceptance length and acceleration ratio. We now perform online SFT training of draft models throughout: spec documentation.
- Achieves 25%+ rollout acceleration compared to frozen MTP, especially in later training stages.
- Supports MTP sequence packing+CP, loss masking edge case handling, LM head/embedding gradient isolation, and Megatron↔SGLang weight synchronization.
Other Improvements
We enhanced the FSDP training backend, support independent rollout subsystem deployment, and added more debugging tools (metrics, post-hoc analyzers, better profiling). Also includes Lean formal mathematics examples with SFT/RL scripts.
Future Roadmap
We are committed to enterprise-grade RL training support. Upcoming developments:
- Large-scale MoE RL examples for new hardware (like GB300).
- Multimodal training support.
- Rollout acceleration: compatible with SGLang spec v2, advanced speculative decoding (like EAGLE3, multi-spec layers).
- Balanced resource allocation between training and serving in large-scale asynchronous training.
- Resilience support for GPU failures.
Acknowledgments
Miles would not exist without slime's authors and the broader SGLang RL community. We invite researchers, startups, and teams to explore both slime and Miles—choose what suits you—to jointly build efficient and reliable reinforcement learning. Community feedback drives us forward, and we are actively iterating on Miles to build production-ready training environments.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接