SGLang 与 Miles 团队宣布对 NVIDIA Nemotron 3 Ultra 实现 Day-0 支持,助力长时程自主代理系统从短交互转向持久化工作流。
代理 AI 系统正从简短提示-响应模式转向需要规划、工具调用、结果检验、错误恢复并跨长任务持续工作的持久化流程。这些代理需要强大的推理能力、快速推理、长上下文理解以及可靠的工具使用能力。

Nemotron 3 Ultra 核心特性
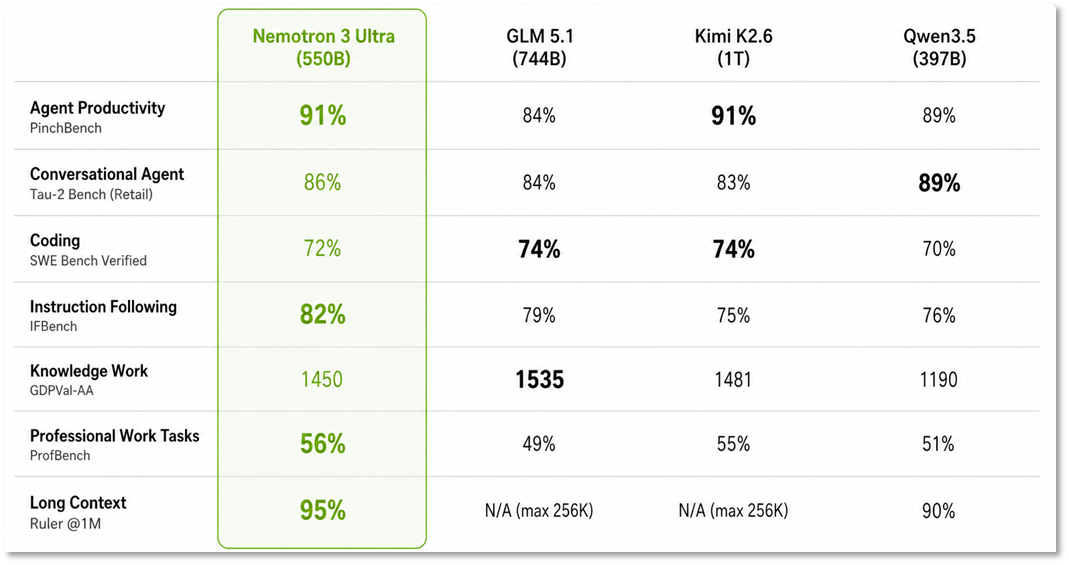
Nemotron 3 Ultra 是 Nemotron 家族中的开放前沿推理模型,专为长时程自主代理优化,适用于编码、深度研究、企业工作流和 EDA 等场景。
- 架构:混合 Transformer-Mamba 的 MoE 架构,总参数 550B,激活参数 55B,上下文长度达 1M token。
- 效率:支持 NVFP4 与 BF16 高吞吐推理,NVFP4 检查点可在 Blackwell GPU 上运行。
- 训练:采用多环境强化学习后训练,强化代理行为。
- 部署:开放权重、数据与配方,支持多 GPU 配置。
快速开始与部署
用户可通过 SGLang Docker 容器快速部署,推荐使用官方 cookbook 或 NVIDIA Brev launchable。
启动服务命令支持 8x B200 配置,并可通过 OpenAI 兼容客户端调用,获取 reasoning_content 与生成结果。
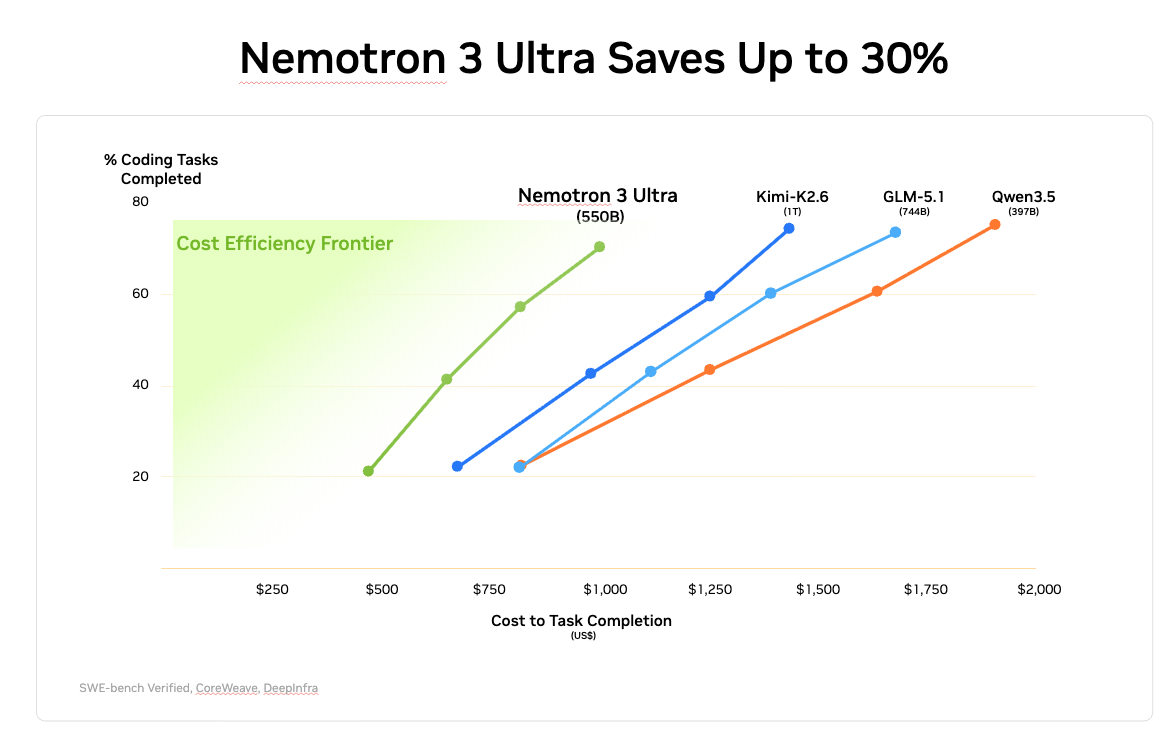
专为长时程代理工作负载设计
Nemotron 3 Ultra 集成主要代理框架,支持 GRPO RL 训练。关键创新包括:
- 针对代理 harness 的后训练
- Hybrid Mamba-Transformer 架构
- Latent MoE 与 Multi-Token Prediction
- NVFP4 精度跨架构兼容
在代理生产力、指令遵循和长上下文任务上领先开源模型,成本最高可节省 30%。
Miles 强化学习支持
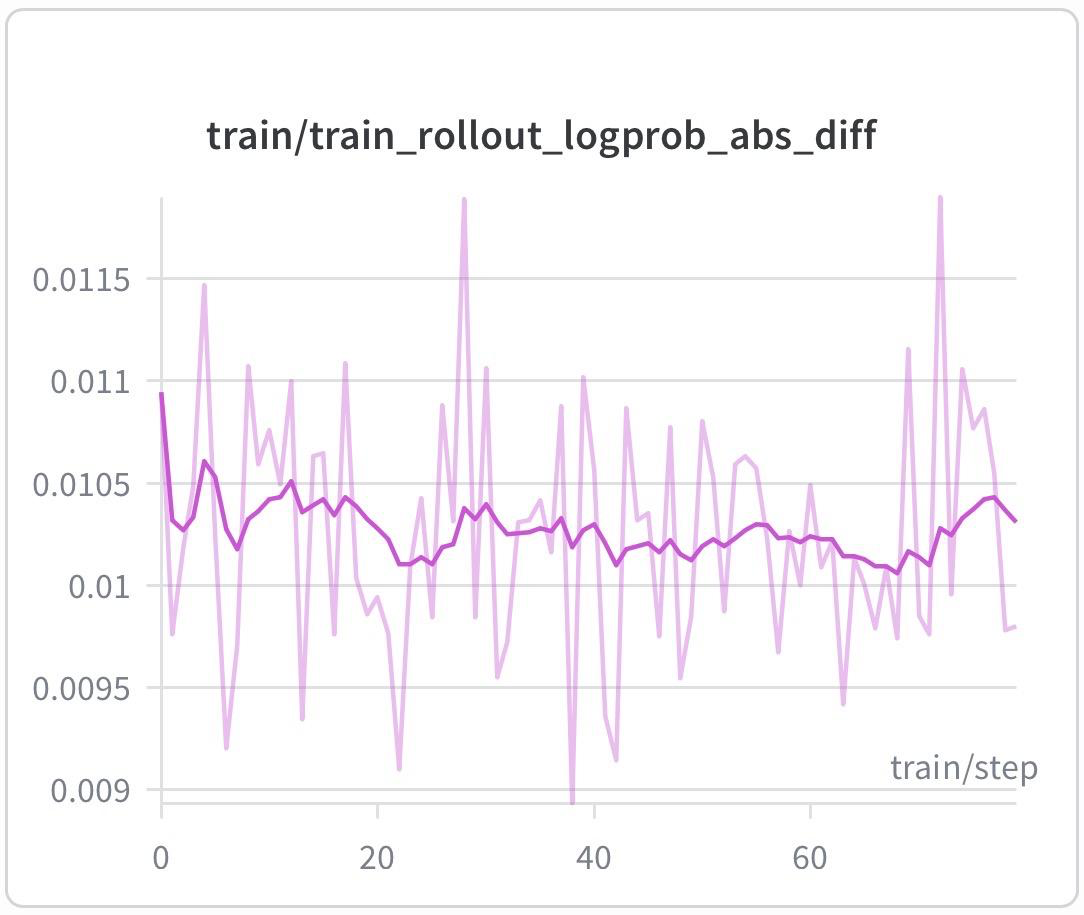
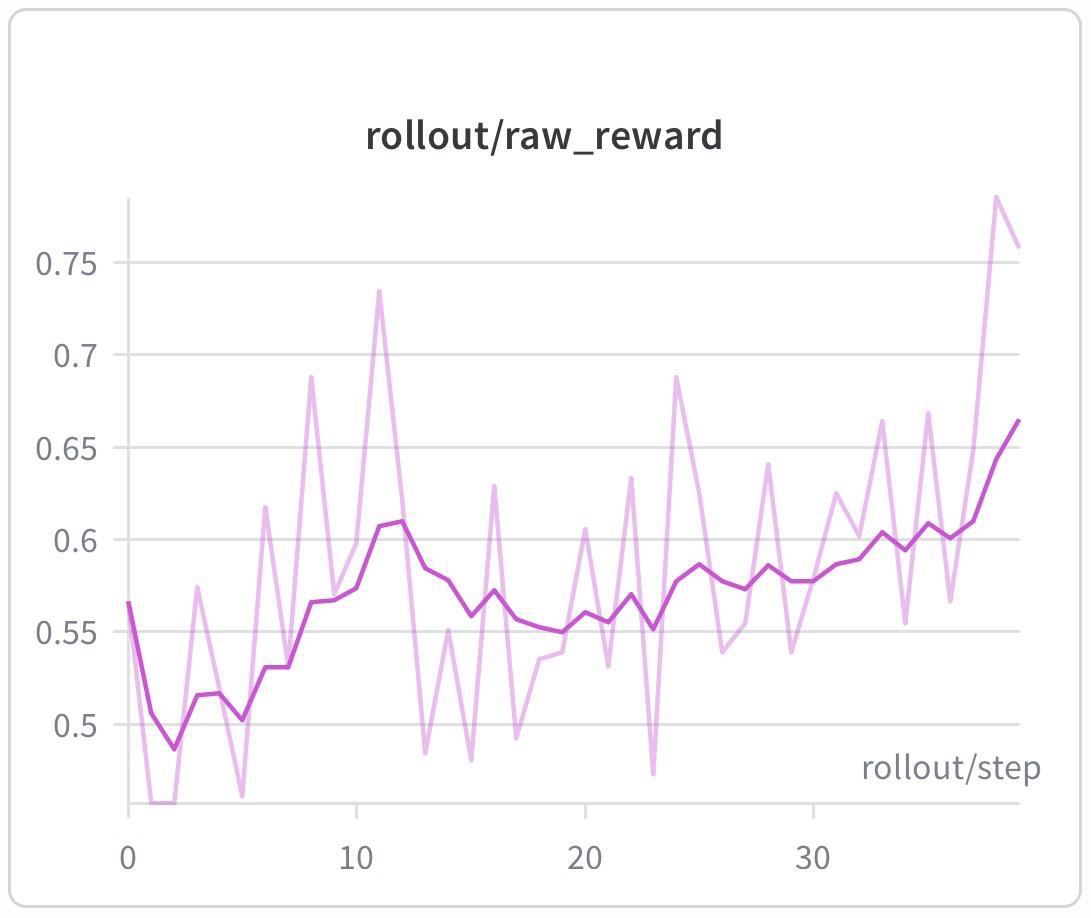
Miles 框架已在 128 张 H200 GPU 上验证 GRPO RL 训练,支持 TP/PP/EP/DP 并行策略与 DP attention,训练与 rollout log-prob 差异保持在 0.01 左右,证明 pipeline 高度 on-policy。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接