TL;DR
Mixture-of-Experts (MoE) 模型依赖 Expert Parallelism (EP) 在多 GPU 上扩展推理。SGLang 中的 DeepEP 和 EPLB 已在 EP 下提供高性能服务,但由于 token 路由不均匀,各 rank 负载仍可能失衡。
本文介绍 SGLang 中两种调度时负载均衡特性:
- Waterfill:针对 DeepEP 的轻量级共享专家负载均衡方法,将共享专家分发到负载较低的 rank。在两节点 Hopper GPU 上,DeepSeek-V3/R1 类工作负载下总吞吐提升 +1.48% 至 +4.66%;DeepSeek V4 峰值从 49,253 tok/s 提升至 51,677 tok/s(+4.92%)。
- LPLB:基于线性规划的冗余专家副本负载均衡器,解决每层分发优化问题。在相同硬件上,吞吐提升 +0.84% 至 +7.34%。
相关 PR 已合并至 SGLang。
引言
DeepSeek-V3/R1 等大型 MoE 模型通过稀疏专家激活提升容量。EP 将专家分布到不同 GPU,token 被路由到对应 rank,但路由器无法生成完全均衡的流量,导致部分 rank 成为瓶颈。静态 EPLB 虽可优化长期放置,仍无法消除单批次内的残余不均。Waterfill 和 LPLB 在调度时刻进行动态平衡。
DeepEP MoE 推理中的负载失衡
DeepEP 提供优化的 token dispatch 与 combine 内核。典型 DeepSeek 风格 MoE 层中,每个 token 路由到多个 routed expert,部分模型还包含 applied 于所有 token 的 shared expert。静态放置无法完全消除运行时不均,Waterfill 与 LPLB 针对此问题提出解决方案。
Waterfill:共享专家的轻量级负载均衡
Waterfill 将共享专家视为可调度槽位,根据各 rank 当前 routed 负载动态选择目标 rank,优先填充负载较低的 rank,从而缩短最慢 MoE 层路径。
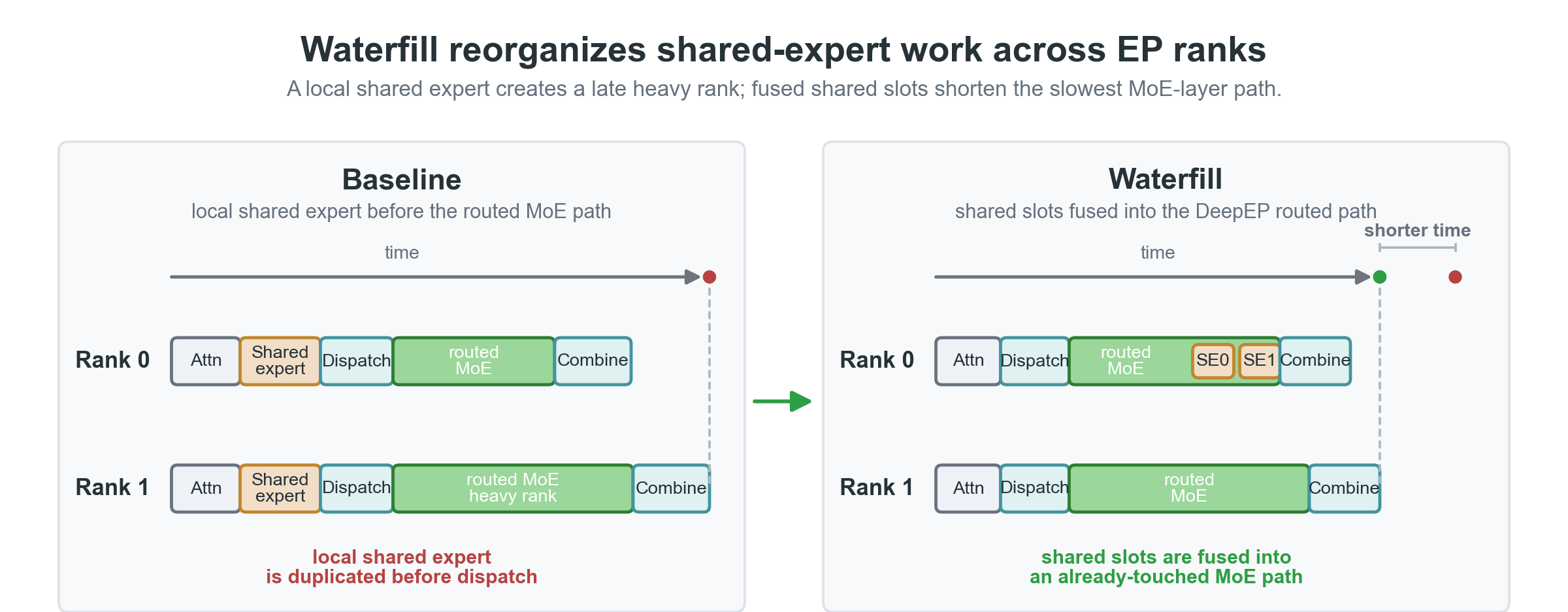
图 1. Waterfill 在不改变 routed expert 选择的前提下,将共享专家工作从过载 rank 转移至较轻 rank。
共享专家融合机制
通过将共享专家融合进 DeepEP MoE 布局,Waterfill 得以利用同一 dispatch 流程实现负载感知分发。
LPLB:基于线性规划的冗余专家副本负载均衡
EPLB 默认将热点专家 token 均匀分配给物理副本,但实时流量常与离线校准分布不符。LPLB 针对每层冗余副本求解线性规划最优分配。
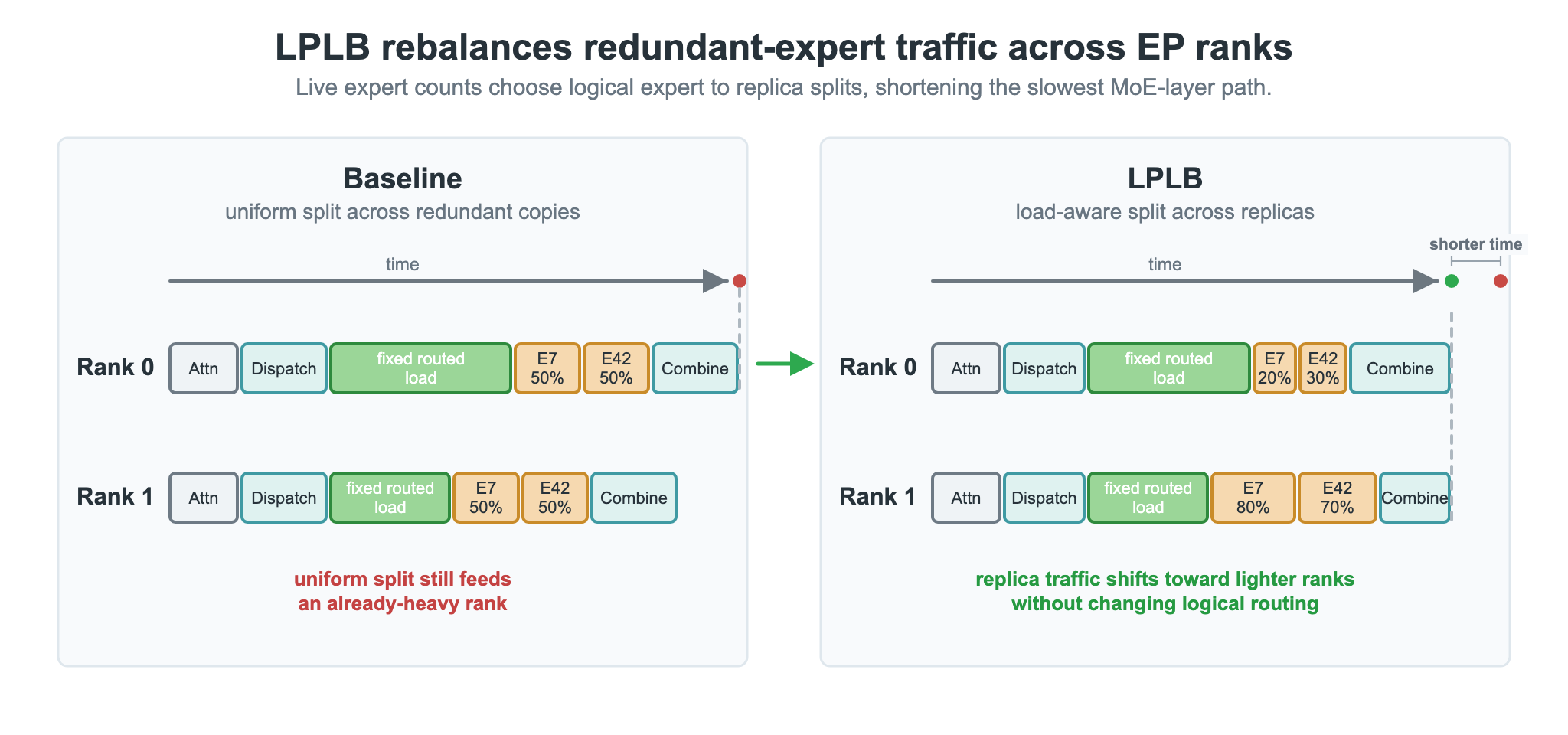
图 2. LPLB 对冗余专家副本进行负载感知分发。
实验结果
在两节点 Hopper GPU 上,Waterfill 与 LPLB 在 MMLU、GPQA、GSM8K 等基准上均带来明显吞吐提升。
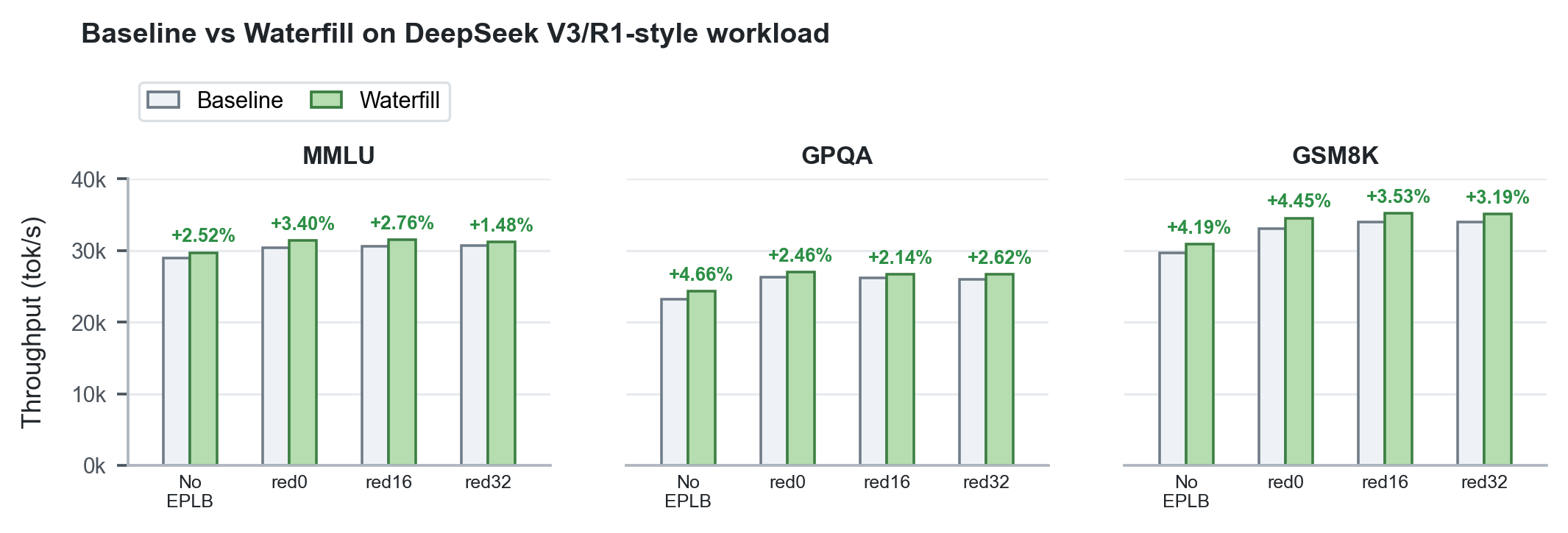
图 3. Waterfill 在 DeepSeek V3/R1 类工作负载上的吞吐表现。
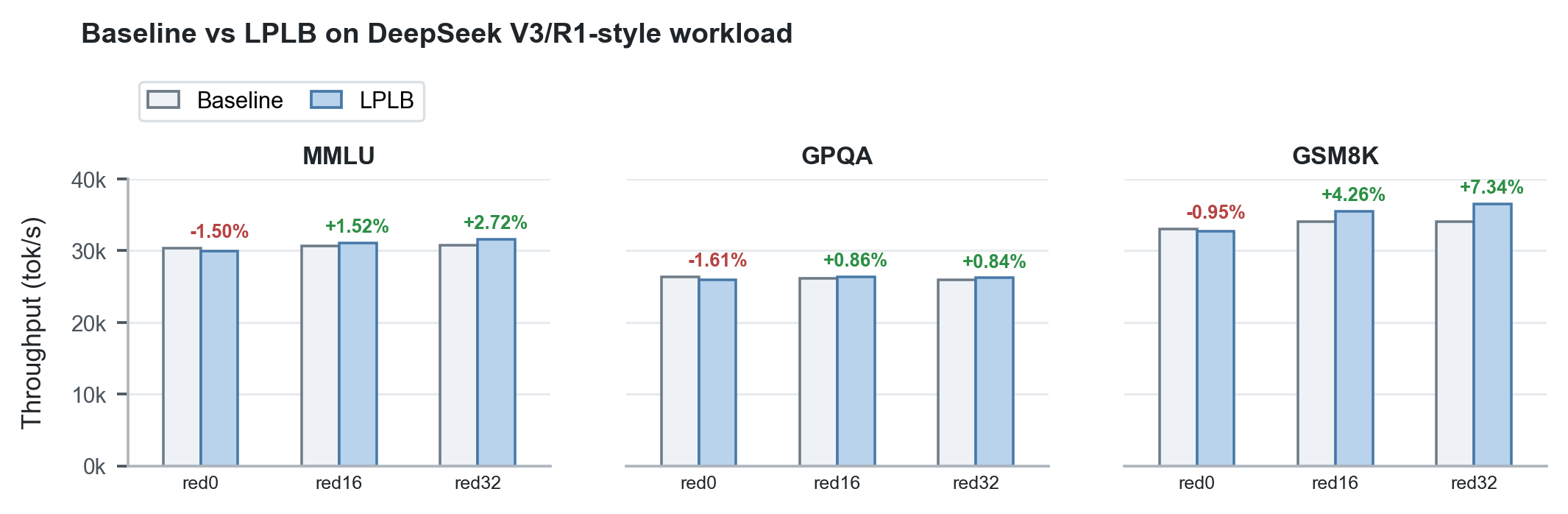
图 4. LPLB 在 DeepSeek V3/R1 类工作负载上的吞吐表现。
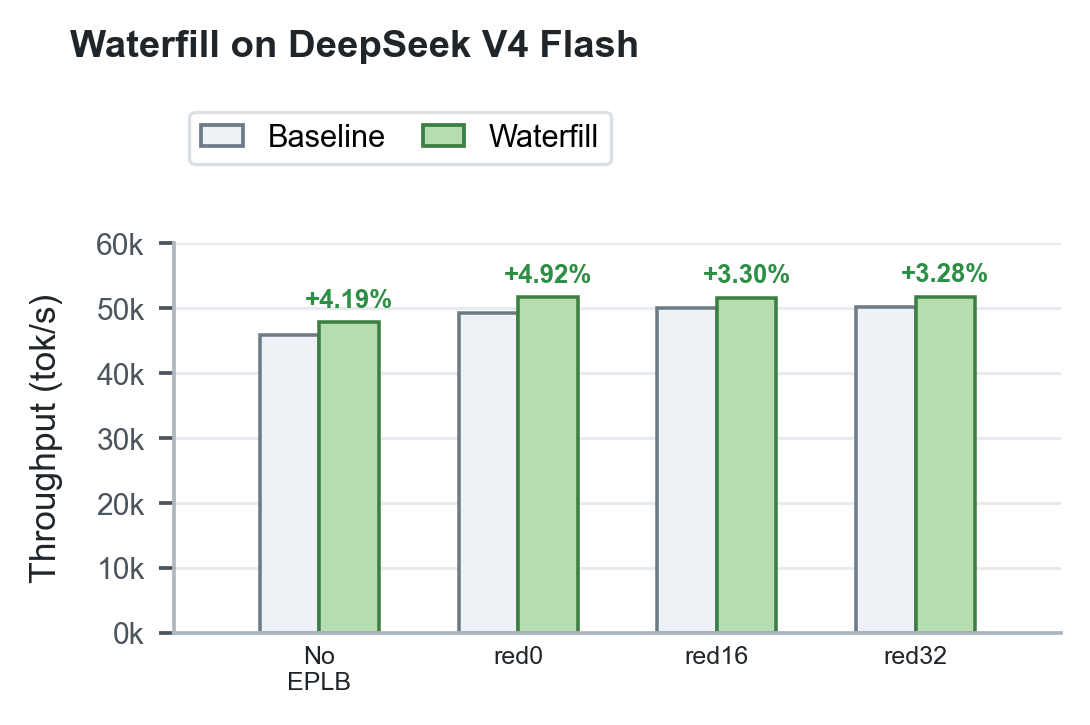
图 5. Waterfill 在 DeepSeek V4 Flash 上的吞吐表现。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接