MLCommons 今日宣布 MLPerf Training v6.0 基准测试套件最新结果。本轮新增的两项基准及大量提交,凸显 AI 生态的快速变革。
“这是社区令人振奋的时刻,”MLPerf Training 工作组联合主席 Shriya Rishab 表示,“我们看到 AI 模型训练最佳实践趋于收敛,同时底层框架和系统的技术多样性也在增加。”
新增基准强调稀疏计算
MLPerf Training 基准通过完整系统测试,覆盖模型、软件与硬件。v6.0 新增 DeepSeek V3 和 GPT-OSS 20B 两项基准,均采用 Mixture-of-Experts(MoE)架构,体现行业向稀疏计算的转变。
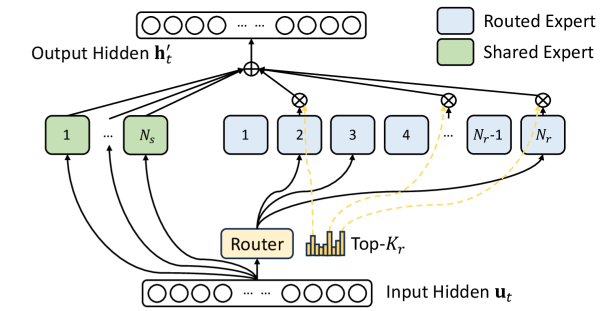
DeepSeek V3 拥有 6710 亿总参数,每 token 激活 370 亿参数,是目前套件中规模最大的基准。GPT-OSS 20B 则规模更小,总参数 210 亿,每 token 激活 36 亿,适合单 8-GPU 节点测试。
提交系统多样性创新高
v6.0 共收到 95 个独特系统,涉及 13 种硬件加速器、19 种主机处理器,60% 为多节点系统。云端系统数量较 v5.1 翻倍以上。
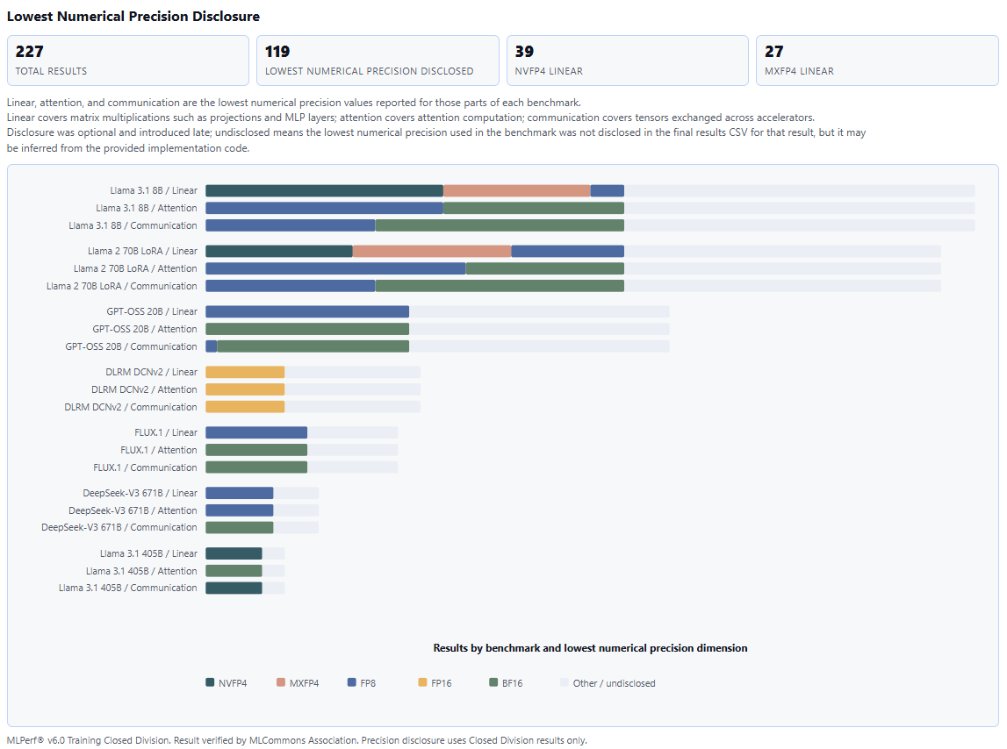
提交者使用了多种 FP4 精度方案,凸显行业在低精度训练上的探索。MLPerf 的准确率门槛要求帮助业界清晰对比不同实现的性能差异。
24 家机构参与 生态持续壮大
本次结果来自 AMD、NVIDIA、Google、Azure 等 24 家机构,其中 Inventec、Netweb Technologies India LTD、TTA 和 Vultr 为首次提交者。MLCommons 欢迎更多组织加入工作组,共同完善基准。
完整结果可访问 MLCommons 官网查看。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接