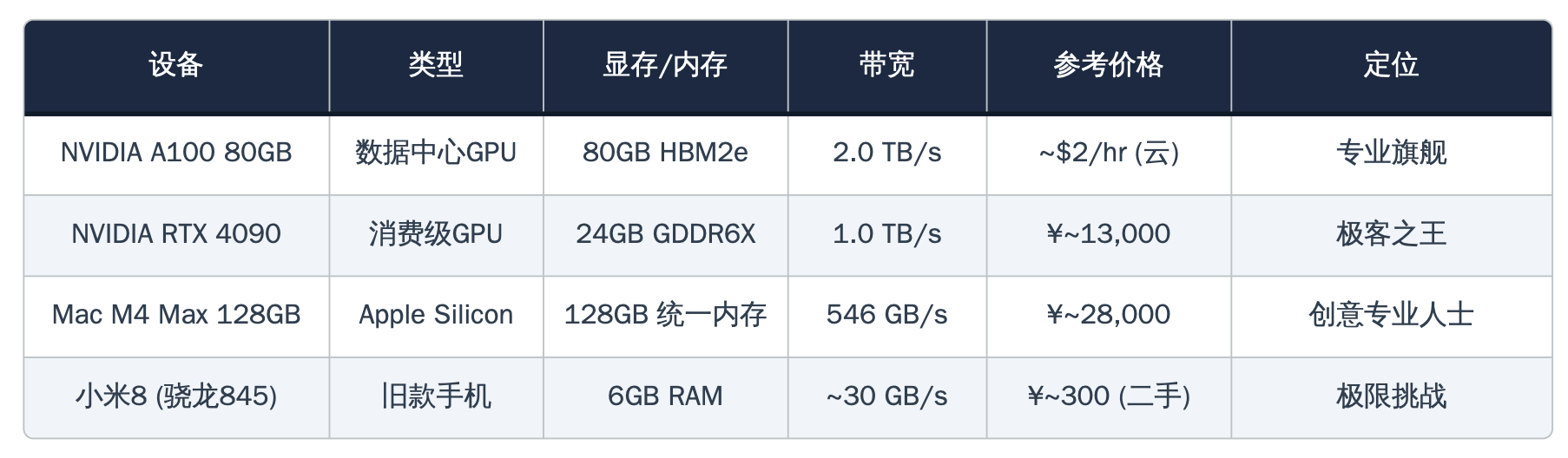
北京时间2026年2月13日讯 —— 当大多数人还在争论AI算力是否只属于科技巨头时,一份来自赢政研究院的独立评测报告,用四台跨越七年技术代差的设备,给出了一个令行业侧目的答案。
这份名为《赢政指数·2026 Q1硬件天梯图》的报告,将NVIDIA A100 80GB(数据中心级旗舰,云端租赁价每小时2美元)、NVIDIA RTX 4090(消费级显卡之王,国内售价约13,000元)、Apple Mac M4 Max 128GB(售价约28,000元)以及一部2018年发布、二手价仅300元的小米8,同时拉上了DeepSeek本地推理的擂台。
这不是一次常规评测。这是一次关于"AI到底离普通人有多远"的极限测试。
4090:一万块买到的"云服务体验"
报告中最核心的结论,属于RTX 4090。
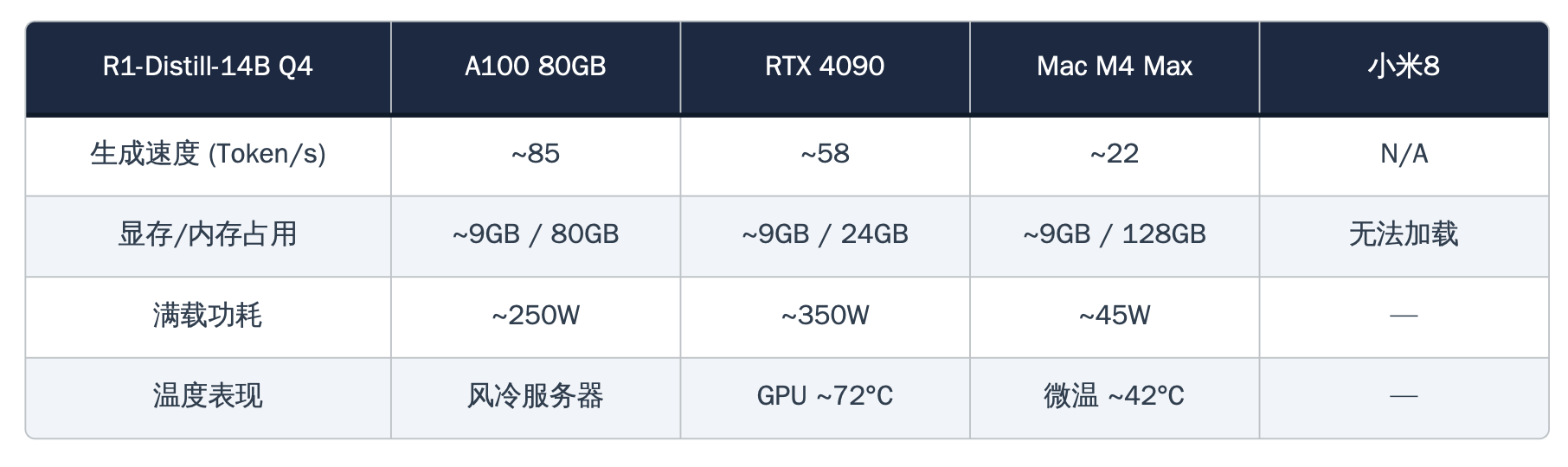
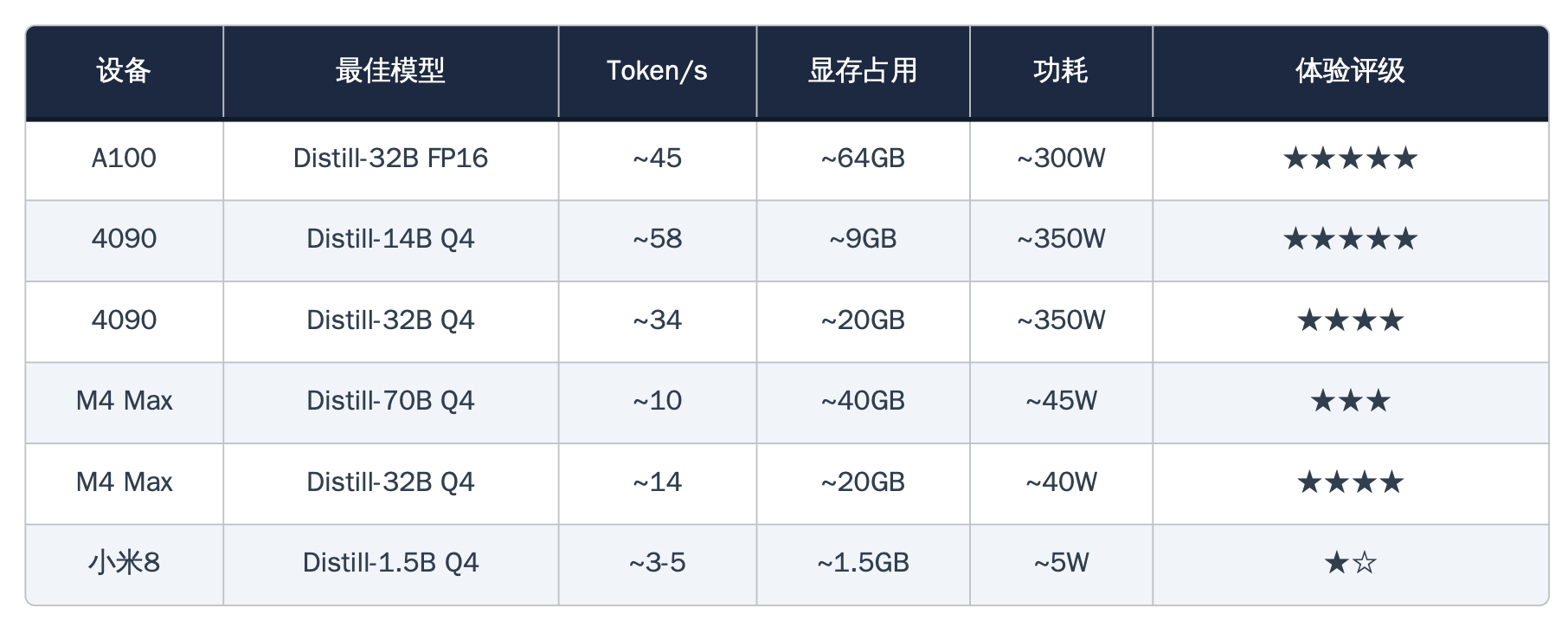
在运行DeepSeek-R1蒸馏版14B参数模型时,这张消费级显卡跑出了每秒58个Token的生成速度——这个数字意味着什么?它比绝大多数人的阅读速度还快。即便切换到更大的32B参数模型,4090依然稳定在每秒34个Token,相当于企业级H100约75%的性能表现,而成本仅为后者的五分之一。
赢政研究院在报告中毫不犹豫地将"穷人的法拉利"称号授予了RTX 4090,理由简洁有力:花一万多元,你就能在自己家里拥有一台数据完全私有、无需持续付费、体验媲美云端的AI工作站。
M4 Max:你以为它是笔记本,其实它在跑700亿参数
如果说4090赢在性价比,苹果M4 Max则赢在了一个所有人都低估的维度——容量。
得益于Apple Silicon的统一内存架构,配备128GB内存的M4 Max成功加载并运行了DeepSeek-R1蒸馏版70B参数模型。这是一件单张RTX 4090在物理上根本做不到的事情——24GB显存连模型都装不下,而M4 Max的128GB统一内存让CPU和GPU共享同一片巨大的内存池,轻松容纳了40GB的模型权重。
更令人印象深刻的是能效表现。整机功耗仅40至45瓦,大约是4090满载功耗的八分之一,而每瓦特产出的Token数量达到了4090的近七倍。报告将其称为"沉默的极客"——外表看起来只是一台普通的苹果笔记本,内里却在悄无声息地运行着700亿参数的大语言模型。
小米8:300元的"行为艺术"
然而,整份报告中最令人意外的篇章,属于那部小米8。
这部搭载骁龙845处理器、仅有6GB运行内存的2018年产手机,通过Termux终端模拟器和Ollama推理框架,成功加载了DeepSeek-R1蒸馏版1.5B参数模型,并以每秒3到5个Token的速度输出文本——刚好处于人类可阅读的边缘。
代价是显而易见的。持续推理不到两分钟,机身温度便飙升至45度以上,局部热点逼近50度。处理器开始热降频,生成速度从每秒5个Token一路滑落到2至3个。报告中特别附上了一条加粗的警告:"请勿在充电时或覆盖物下进行测试,除非你想亲身体验'AI发烧友'的字面含义。"
赢政研究院将这项测试定性为"行为艺术"——它证明了一种可能性,即一部售价仅300元的旧手机确实可以在完全离线的状态下运行AI推理,但这距离实用仍有相当距离。1.5B参数的极小模型能做简单问答和代码补全,复杂推理和长文本生成则力不从心。
A100:毫无悬念的天花板
作为对照组出现的NVIDIA A100 80GB,在绝对性能上毫无悬念地占据了榜首。凭借80GB HBM2e显存和高达每秒2TB的内存带宽,它可以全精度加载32B参数模型而无需任何量化压缩。在双卡配置下运行70B模型时,吐出速度稳定在每秒约19个Token,GPU利用率维持在88%左右。
但报告对它的评语耐人寻味:"这是一辆照字面意义的法拉利——好,但太贵。"单卡购置成本在一万至一万五千美元之间,云端租赁每小时2美元,对个人用户而言几乎没有可行性。
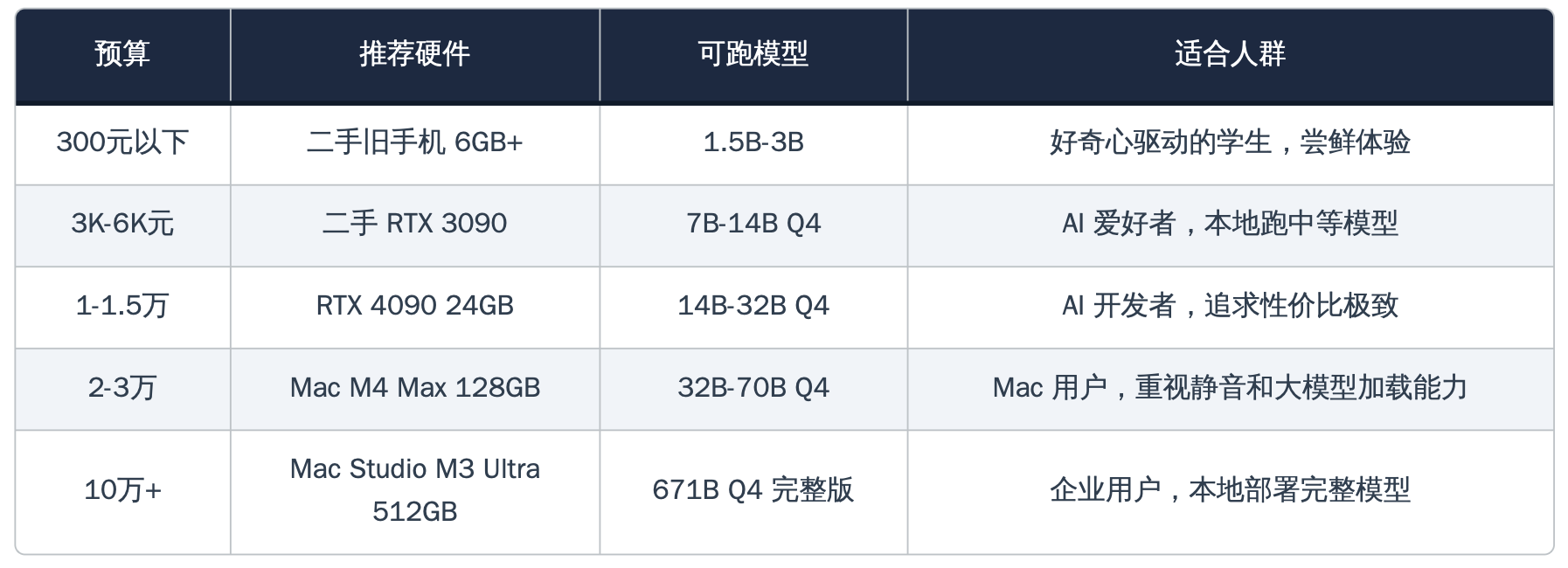
一张表,四个世界
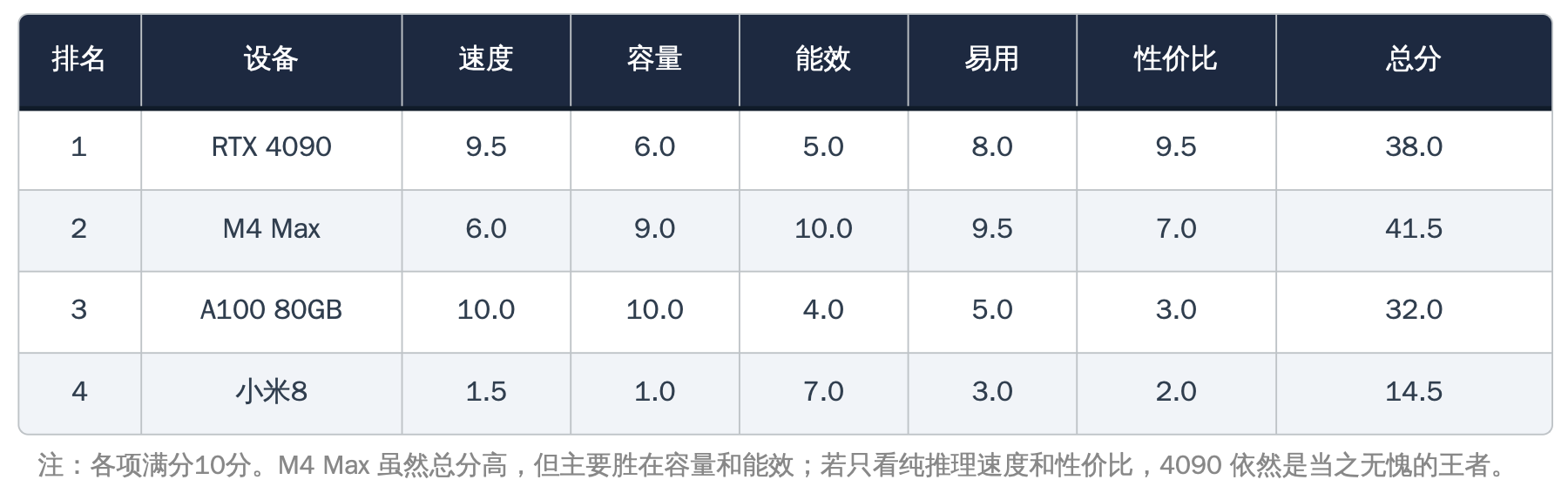
报告最终发布的"赢政综合排行榜",以速度、容量、能效、易用性和性价比五个维度进行十分制评分。RTX 4090以38分夺得性价比综合冠军,M4 Max以41.5分在总分上实际最高(主要胜在容量和能效),A100以32分位列第三,小米8以14.5分垫底——但拿到了一个特别设立的"最佳勇气奖"。
报告在结语中写道:
"我们正在进入一个AI民主化的时代。不论你的预算是300元还是3万元,都能找到属于自己的法拉利。区别只在于,有的是真正的F40,有的是比例模型——但它们都能让你感受到速度与激情。"
这或许是2026年开年以来,关于AI算力平权最有力的一份注脚。
赢政研究院(Winzheng Research Lab)是一家专注于AI基准测试、模型安全与硬件优化的独立研究机构,秉持100%独立与客观的评测立场。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接