DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles
The SGLang and Miles TeamApril 25, 2026We are thrilled to announce Day-0 support for DeepSeek-V4 across both inference and RL training. SGLang and Miles form the first open-source stack to serve and train DeepSeek-V4 on launch day — with systems purpose-built for its hybrid sparse-attention architecture, manifold-constrained hyper-connections (mHC), and FP4 expert weights.

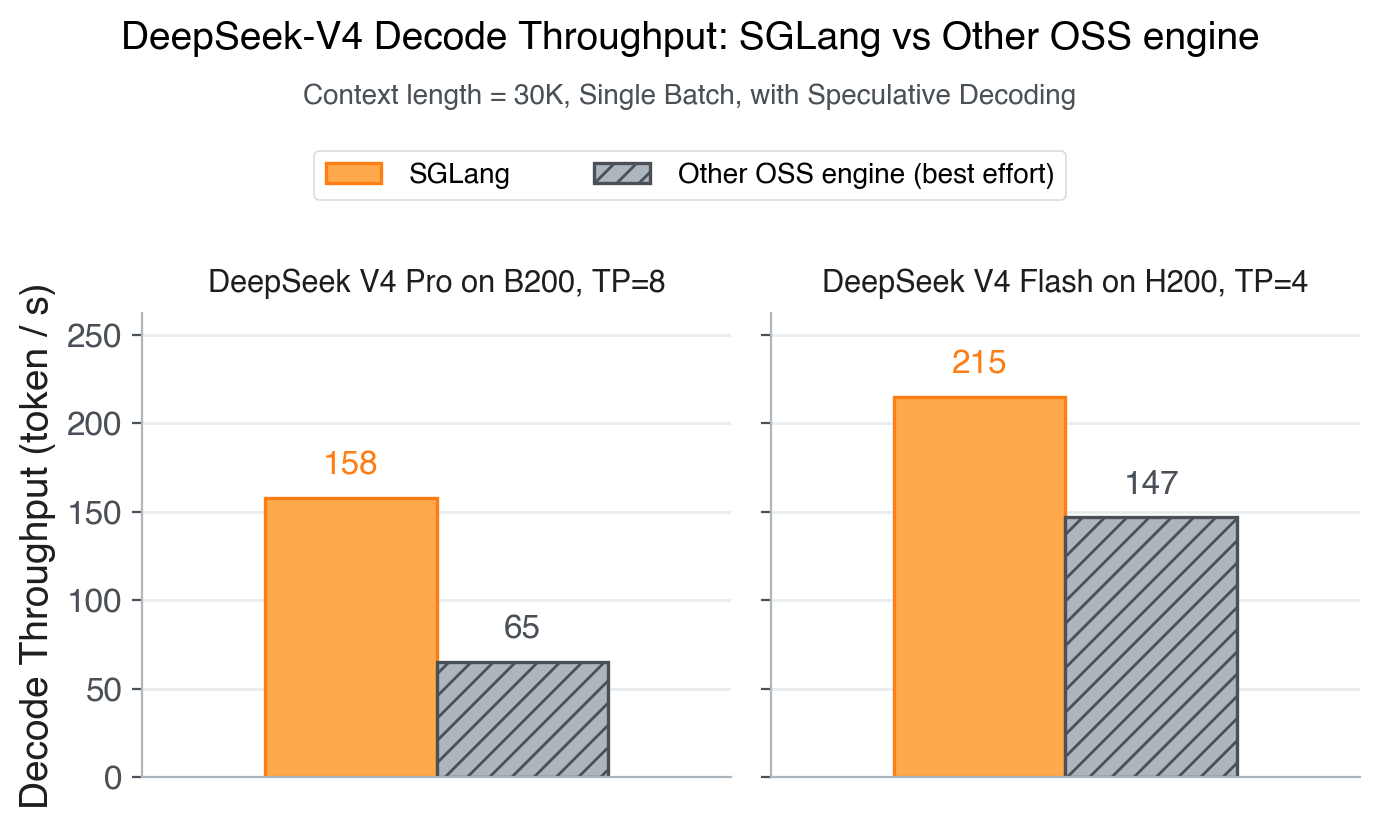
Figure 1. Decode throughput of SGLang vs the other OSS engine on a 30K-token prompt truncated from "Dream of the Red Chamber". We tried the best-effort spec configuration for each engine based on its official recipe. See benchmark notes for details.
TL;DR
SGLang and Miles ship Day-0 inference and RL for DeepSeek-V4 (1.6T Pro, 284B Flash).
- Inference (caching & attention): ShadowRadix prefix cache, HiSparse CPU-extended KV, MTP speculative decoding with in-graph metadata, Flash Compressor, Lightning TopK, hierarchical multi-stream overlap.
- Inference (kernels & deployment): fast kernel integrations (FlashMLA, FlashInfer TRTLLM-Gen MoE, DeepGEMM Mega MoE, TileLang mHC), DP/TP/CP attention, EP MoE on DeepEP, PD disaggregation.
- RL training: full parallelism (DP/TP/SP/EP/PP/CP), tilelang attention, enhanced stability, FP8 training.
- Hardware: Hopper, Blackwell, Grace Blackwell, AMD, NPU.
Launch Commands: SGLang Cookbook
Model Key Features & New Capabilities
DeepSeek-V4 (1.6T Pro, 284B Flash) extends its predecessor DeepSeek-V3.2 along three axes:
- Hybrid sparse-attention: each layer mixes sliding window attention with one of two compression mechanisms (4:1 top-k or 128:1 dense), keeping the 1M-token context window tractable.
- mHC (Manifold-Constrained Hyper-Connections): a generalization of standard residual connections that improves gradient flow and representation quality.
- FP4 expert weights: native FP4 MoE experts for efficient serving on the latest Blackwell hardware.
Designs, Features and Performance Optimizations
ShadowRadix: Native Prefix Caching for Hybrid Attention
Every layer of DeepSeek-V4 combines SWA (sliding window attention over the last 128 raw tokens) with either C4 (top-512 sparse over 4:1-compressed KV) or C128 (dense over 128:1-compressed KV). Also, for maintaining the inflight compressing KV slots, each compression layer has a state pool that stores the in-progress compression state. This complex mechanism breaks traditional prefix caching assumption: three heterogeneous KV pools and two compression-state pools must stay coherent across prefill, decode, and speculative decoding. The following figure shows the per-layer hybrid attention scope for an N = 1024 example.

To solve this coherence problem, we introduce ShadowRadix -- a native prefix caching mechanism for hybrid attentions.
One core idea. A radix tree indexes virtual full-token slots -- a unified coordinate system shared by all layers. From each slot, we project shadows (per-pool index mappings) into the physical pools (SWA / C4 / C128). Compression-state ring buffers sit in their own pool, but a second-level arithmetic shadow maps each ring slot from the SWA page index -- logically nested inside SWA, physically independent. This lets lifetimes decouple: tombstoning frees a node's SWA slots once the sliding window moves past it, while its C4/C128 shadows stay alive and shareable. So a 10k-token request keeps only 128 SWA tokens plus its full C4/C128 compressed KV -- and that compressed KV is what other prefix-matching requests reuse.
 Figure 2. ShadowRadix storage layout.
Figure 2. ShadowRadix storage layout.
Because shadows are just per-pool projections of the same source, each pool can manage its own lifetime independently. We exploit this with a two-counter lock per node -- full_lock_ref covers the source (and therefore its C4/C128 shadows), while swa_lock_ref only tracks whether the node still falls inside someone's sliding window. When the SWA counter hits zero we drop the node's SWA slots, but the node stays in the tree and its compressed shadows keep serving prefix matches. Matching stays SWA-safe by requiring 128 consecutive live tokens from the match point before extending into the window.
The nested ring shadows inherit this for free: since a ring slot's address is swa_page * ring_size + pos % ring_size, releasing an SWA page automatically invalidates the rings sitting inside it -- without any extra tracking, and ring sizes are picked so MTP rollback can't race a wrap.
Speculative decoding works without any change to this design. The one issue is that draft tokens are written into the ring before verification decides which ones to accept, so a rejected-then-retried step can wrap around and overwrite slots that still belong to the live window. Doubling the ring sizes under spec (C4: 8 -> 16, C128: 128 -> 256) leaves enough headroom that any in-flight speculative write lands outside the active window, so EAGLE works out of the box.
Speculative Decoding
DeepSeek-V4 ships a single-layer MTP head -- a separately trained DSv4 decoder layer that runs SWA-only attention (no compressor, no indexer), with the previous-step hidden state (h_proj) and the next-token embedding (e_proj) combined as its input. We support it Day-0; the real systems work sits one level below. Hybrid attention metadata is heavy, and preparing it eagerly on the scheduler stream becomes the launch bottleneck under speculative decoding -- so we fuse that preparation into the CUDA graph for both draft and verify passes.
Two optimizations drive the speedup:
- In-graph metadata preparation. Hybrid attention's per-pass metadata is heavy -- SWA page indices, shadow-mapped pool slots, compressor/indexer plans, per-pool write locations -- but it's all index arithmetic over page tables and lengths, which fits device kernels cleanly. So each captured graph only needs the raw batch state as per-replay input (active requests, current lengths, new-KV destinations), copied into fixed buffers; captured kernels rebuild the rest inside the graph, and Python never touches the per-pass path during replay. This collapses the per-step launch overhead that would otherwise dominate speculative decoding.
- Overlap scheduling. CPU-side work (result processing, batch preparation, deallocation) runs in parallel with GPU execution.

Figure 2. Hybrid sparse attention combined with ShadowRadix and in-graph spec metadata keeps SGLang decode throughput essentially flat from 4K to 900K -- close to the model's full 1M context window. The drop is under 10% on both B200 (199 -> 180 token/s) and H200 (266 -> 240 token/s).
HiSparse: Turbocharging Sparse Attention with Hierarchical Memory
Recently introduced, HiSparse is a technique that offloads inactive KV cache to CPU memory, enabling larger batch sizes and higher throughput for sparse attention. HiSparse fits naturally with C4 layers: each step the indexer top-k touches only a small fraction of compressed positions, so most C4 KV is inactive at any moment and can live on CPU. C128 is dense (every position is touched) and SWA is already small (128 tokens), so neither benefits from offload. By using a CPU memory pool to extend just the C4 KV cache pool, we improve overall token capacity and throughput for long-context serving by up to 3x.


Left: the GPU keeps only small device buffers for the active working set of the C4 KV cache, while a larger pinned CPU mirror stores the full-context KV cache. At each step, the HiSparse Coordinator swaps missed pages in from CPU and evicts inactive GPU pages using an LRU policy. Newly generated tokens are asynchronously backed up to the CPU mirror. Right: peak throughput for DeepSeek-V4-Flash on 2xB200, 200K-input / 20K-output, swa_full_tokens_ratio=0.001.
Fast Kernel Integrations
-
New FlashMLA path for hybrid attention: DeepSeek-V4's hybrid attention combines SWA over the local window with an "extra" attention over either C4 (sparse top-k over compressed KV) or C128 (dense over compressed KV). We integrate the refreshed FlashMLA interface so SWA and the extra attention run in a single fused kernel call (the kernel takes both k_cache and extra_k_cache with their respective indices), sharing metadata construction in the forward pass. Target GPUs are Hopper/SM90 and Blackwell/SM100 where the corresponding kernels are supported.
-
FlashInfer TRTLLM-Gen fused MoE for MXFP8 x MXFP4: DeepSeek-V4 ships native FP4 expert weights, making small-batch MoE decode sensitive to expert-weight bandwidth. We integrate the TRTLLM-Gen fused MoE backend through FlashInfer to pair MXFP8 activations with MXFP4 expert weights and adapt SGLang's weight/scale layout to the kernel's expected format. This path targets Blackwell GPUs and relies on Blackwell-specific FP4 tensor-core machinery and tiled/persistent execution.
-
TileLang mHC kernels with split-K: mHC replaces the residual stream with a per-token mixture over hc_mult parallel branches. A Sinkhorn normalization over a GEMM output produces the mixture weights. In low-latency decoding, the pre-GEMM TileLang kernel can become the bottleneck because batch sizes are small and parallelism is limited. We therefore extend our two-stage split-K TileLang kernel (mhc_pre_gemm_sqrsum_splitk_kernel) to partition the K dimension across different CTAs, improving GPU utilization at small batch sizes. We also integrate a fused mhc_pre_big_fuse_tilelang path that combines RMSNorm, Sinkhorn, and residual mixing in one kernel, with PDL enabled.
-
DeepGEMM Mega MoE integration: We integrate DeepGEMM's Mega MoE path on Blackwell. This kernel fuses EP dispatch, the first FP8xFP4 expert GEMM, SwiGLU, the second FP8xFP4 expert GEMM, and EP combine into a single symmetric-memory-based mega-kernel, overlapping NVLink communication with tensor-core computation. Because Mega MoE requires transformed FP4 expert weights with UE8M0 scale factors, we adapt the existing EP/MoE activation path to consume the transformed layout directly. This avoids keeping two resident copies of expert tensors in GPU memory while still enabling both the DeepEP path and the low-latency Mega MoE path.
For background on kernel-level integration patterns, see our earlier blog Scaling DeepSeek on GB200.
Various Kernel Optimizations
We elaborate on two representative kernels below.
 Figure 5. Two general kernel-level optimizations. Left: Flash Compressor fuses the naive 5-stage compression chain into one on-chip pass, cutting HBM round-trips from 5 to 2. Right: Lightning TopK replaces a global sort with a cluster-of-8 radix-select reduction -- each CTA builds a local 10-bit radix histogram, the cluster reduces histograms to pick a threshold that admits exactly K = 512 candidates, then each CTA scatters only its above-threshold entries.
Figure 5. Two general kernel-level optimizations. Left: Flash Compressor fuses the naive 5-stage compression chain into one on-chip pass, cutting HBM round-trips from 5 to 2. Right: Lightning TopK replaces a global sort with a cluster-of-8 radix-select reduction -- each CTA builds a local 10-bit radix histogram, the cluster reduces histograms to pick a threshold that admits exactly K = 512 candidates, then each CTA scatters only its above-threshold entries.
Flash Compressor: IO-aware Exact Compression
Compressed attention compresses a group of tokens into one KV via softmax-weighted averaging over per-token scores. A naive implementation hits HBM five times and runs softmax over a non-contiguous dimension, so compression itself often costs more than the compressed attention it feeds. We fuse the whole pipeline into a single on-chip pass (Figure 5, left), with softmax kept warp-local for C4 and a single CTA-wide reduction for C128. On H200 this can reach up to 80% of peak memory bandwidth and more than 10x over a naive PyTorch pipeline.
Lightning TopK
Sparse attention depends on a top-k selection step in the indexer. With 4:1 compression, a 1M-token context still produces 256K candidates per request. At this scale, a naive implementation can take more than 100 us even at batch size 1, exceeding the latency of both the indexer GEMM upstream and the sparse attention kernel downstream. We address this with a custom radix-select kernel for long-context decode. Instead of performing a full global sort, the kernel narrows the candidate set and uses CUDA cluster launch with asynchronous copy to increase parallelism and overlap memory movement with selection. This avoids expensive global sort and cross-CTA synchronization through HBM, which effectively reduces small-batch top-k latency to about 15 us and remains performant at large batch size.
Parallelism and Deployment
- Context parallelism for long-context prefill. Most of DSv4's hybrid attention path -- SWA, C4/C128 compressors, indexer -- can't be sharded along heads, so TP hits a ceiling on long prompts. CP round-robins tokens across attention ranks: each rank owns 1 / cp_size of the sequence, and all per-token metadata (SWA page indices and lengths, C4/C128 positions, page tables, indexer top-k lengths) is reindexed locally, while the compressor's output-write locations stay global so the produced KV still lands contiguously. CP is specifically the prefill NSA path and is what makes long-context TTFT scale here.
- FlashMLA head padding under high TP. FlashMLA requires num_heads to be a multiple of 128 on Blackwell (64 on Hopper), which high TP sizes easily violate. Rather than rewrite the kernel, we pad per call at the tensor level: allocate a full-width Q buffer, copy the rank's real heads into its slice, pad the rest, invoke the kernel, trim the output. The extra FLOPs brings negligible overhead because MLA decode is typically memory-bandwidth-bound on KV reads.
- Paged KV transfer for PD disaggregation. We extend SGLang's existing PD transfer protocol with page-indexed KV transport. Pages are moved by index through the standard path and reinterpreted on the receiving side via its own shadow mappings, so the transport layer stays oblivious to DSv4's non-uniform on-device layout (see ShadowRadix).
- Expert parallelism on DeepEP + Mega MoE. DSv4's MoE runs on top of DeepEP for all-to-all expert routing. On top of it we integrate DeepGEMM's Mega MoE path (described in the kernel-integration section above). Mega MoE expects expert weights in a different layout from the standard DeepEP path; we set up the Mega MoE weights as an aliased view of the DeepEP expert tensors so large-scale deployments don't pay for two copies of expert weights in GPU memory. The full path pairs this with SwiGLU-clamp and JIT activation fusions on the EP side.
Hierarchical Multi-Stream Overlap
Attention preparation is a crowd of small kernels -- Q/KV projections, compressor, indexer -- and at small batch each one underfills the GPU. Serial launch overhead then starts to dominate decode.
We fan them across CUDA streams on two levels (Figure 6). The top level runs the four preparation ops in parallel. The indexer is the heaviest of them, so inside it we split again -- Q projection, weights projection, and compressor GEMM overlap too. Events like q_lora_ready and q_scale_ready hand off between streams as soon as a dependency finishes, so nothing waits on a whole stream to drain.
 Figure 6. Two-level stream fan-out for attention preparation, with fine-grained q_lora_ready / q_scale_ready events linking dependent work across streams.
Figure 6. Two-level stream fan-out for attention preparation, with fine-grained q_lora_ready / q_scale_ready events linking dependent work across streams.
This runs inside the CUDA graph and only kicks in at small batch -- large prefills already saturate the device, so the overlap wouldn't add anything.
Reinforcement Learning -- Miles Support
 Figure 4. Day-0 Verified RL pipeline for DeepSeek-V4: Miles and SGLang together provide stability (R3 and indexer replay, Step-0 train-inference diff ~0.02-0.03), efficiency (DP/TP/SP/EP/PP/CP, Tilelang kernels, FP8/BF16 rollout and training), and broad hardware support (Hopper, Blackwell, Grace Blackwell).
Figure 4. Day-0 Verified RL pipeline for DeepSeek-V4: Miles and SGLang together provide stability (R3 and indexer replay, Step-0 train-inference diff ~0.02-0.03), efficiency (DP/TP/SP/EP/PP/CP, Tilelang kernels, FP8/BF16 rollout and training), and broad hardware support (Hopper, Blackwell, Grace Blackwell).
Training backend: DeepSeek-V4 Modeling in Megatron-LM
For DeepSeek-V4, most ops is rebuilt because of the brand new model architecture, for example, the complex compressed attention, the new sparse-MLA and indexer modules and the mHC layer.
Parallelism: DP/TP/SP/EP/PP/CP supported
All six strategies in Megatron (DP/TP/SP/EP/PP/CP) are supported.
- TP and SP are implemented across the compressed-attention module.
- PP: mHC's four streams have to survive stage boundaries so the receiving stage can mix them at every sublayer, so we carry [seq, batch, hc_mult, hidden] across p2p instead of the usual 3-D tensor.
- CP: we support all-gather CP on the DeepSeek-V4 Compressed Attention. The C4 compressor's overlap transform shifts half of each compression group one position back along the sequence (adjacent groups share context at no extra KV cost), so under CP the shift crosses rank boundaries. A halo exchange would fix the overlap alone, but the downstream indexer top-k needs every compressed position anyway, so we fold both collectives into a single all-gather. For example, at CP=4 on a 1024-token sequence each rank holds 256 tokens; we all-gather the full compressed tensor across the CP group, apply the overlap on the assembled sequence, and slice back the local view. C128 layers have no overlap transform and skip the all-gather entirely.
Kernels
Thanks to Slime's kernel support for GLM-5, we adopted and extended their kernels for DeepSeek-V4.
- We adapted the Tilelang DSA indexer kernels to DeepSeek-V4's indexer architecture and use them in the lightning indexer.
- We extended the sparse-MLA Tilelang kernel with per-head learnable attention-sink logits in the softmax denominator to support core attention.
- We use the fused Tilelang Sinkhorn kernel for mHC.
RL Features
We also supported and tested the important RL features, including Rollout Routing Replay (R3), TIS/MIS, FP8 training and FP8 attention QAT, in our DeepSeek-V4 training stack:
-
FP8 rollout, FP8/BF16 training supported. We supported FP8 rollout and both BF16 and FP8 training, with the quantization processor in the weight update.
-
Attention QAT. We simulate FP8 activation quantization on the paths served in FP8 at rollout (compressor KV, vanilla KV, indexer query) for kernel-level numerical match with SGLang when using FP8 rollout precision.
-
Rollout Routing Replay (R3). We extend the R3 processor and the TIS/MIS loss to (b, s, h, d) format in miles to support DeepSeek-V4 backends.
-
Indexer replay (experimental). DeepSeek-V4 has a second stochastic operator beyond MoE routing — the DSA indexer's top-k over compressed KV. We implemented the indexer replay mechanism, capture rollout top-k in SGLang in compressed attention backend, transport them on the existing rollout channel, and re-inject per C4 layer at training. This is an experimental feature - the pipeline passes short-context correctness checks but has not been verified end-to-endl.
Numerical Precision on a Mixed-Precision Stack
- We carefully maintain FP32 precision of sensitive master weights and their gradients across training, checkpoint conversion, and weight update.
- The compressor's backward is a softmax-weighted sum over a long axis where the smallest summands matter; BF16 rounding accumulated across TP ranks biases the sum toward the largest-magnitude contributor. We switch only this all-reduce to FP32.
- We selectively freeze the unstable paths: Sinkhorn in mHC (as a mixing oracle), the MoE router gate, the per-expert score-correction bias, and hash-routed early layers.
- To avoid random numerical spikes in KL loss, we pin some deterministic ops: cuDNN deterministic, NCCL to Ring, TransformerEngine off its nondeterministic paths, and cuBLAS to a fixed workspace. Cost ~10–15% throughput.
And multiple other fixes in Megatron:
- We fixed the checkpoint precision in distributed-optimizer under mixed FP32/BF16 groups.
- To solve the OOM encountered when resuming checkpoint, We allocate the optimizer state on CPU during load to avoid a large peak memory.
Training Result
We launched the 285B model training with the training stack on DAPO at 4096 max response length, running on 32 GB300 GPUs with TP/SP/EP/PP parallelism, FP8 rollout + BF16 training, and R3 enabled. The training dynamics are stable: rollout/training log-prob drift is ~0.023 at the first step, and both reward and eval score grow steadily over the run.


Benchmark Notes
Figure 1 is a Day-0 snapshot of SGLang on DeepSeek-V4, not a definitive ranking. Benchmark setups are messy and we may have missed knobs that would close some of the gap -- if you spot something off, please file an issue and we'll be happy to re-run.
Setup. B200 Pro (1.6T) at TP=8; H200 Flash (285B) at TP=4. Single-batch decode, OSL=4096, on a 30K-token prefix truncated from Dream of the Red Chamber. Decode throughput is 1000 / TPOT (ms).
Speculative decoding (best-effort per each engine's official recipe):
- SGLang: EAGLE 3/1/4 (num-steps=3, eagle-topk=1, num-draft-tokens=4); accept length ~2.5 on both Pro and Flash.
- Other OSS engine: MTP-3 on B200 Pro (accept ~1.19). The per-position breakdown is heavily skewed -- positions 0/1/2 accept 2226 / 354 / 55 tokens respectively -- so the spec path looks like it is mostly accepting only position 0. This suggests the MTP path may not be hitting full effectiveness on Pro; we did not investigate further. On H200 Flash, num_speculative_tokens >= 2 hits a paged_mqa_logits_metadata kernel assertion at server startup that we could not work around in time, so the H200 panel falls back to MTP-1 (accept ~1.92).
Long contexts. We pin the head-to-head at 30K because we did not get stable long-context runs on the other OSS engine in this round (200K+ inputs did not return within our timeout). There may well be a configuration that handles longer contexts; we just did not find it in time.
Roadmap: The Path Ahead
Future work is tracked in:
- SGLang: sgl-project/sglang#23602
- Miles: radixark/miles#1046
Acknowledgement
Thanks to DeepSeek for the model and the Day-0 collaboration, to RadixArk for the GPU infrastructure across Hopper, Blackwell, and Grace Blackwell and the engineering support behind it, and to the SGLang and Miles communities for the upstream frameworks this work builds on.
Thanks also to the individuals who contributed directly to this effort: Justin Chen, Tingwei Huang, Zhangheng Huang, Jamie Li, Sam(Kesen) Li, Zhengda Qin, Jiang Shao, Ray Wang, Hai Xiao, Christina(Jingrong Zhang), Even Zhou, Yijie Zhu.
Citation
@misc{sglang2026dsv4, author \= {Ke Bao and Tom Chen and Mingyi Lu and Ying Sheng and Yusheng Su and Yihao Wang and Zhiqiang Xie and Ziyi Xu and Liangsheng Yin and Qiaolin Yu and Yueming Yuan and Baizhou Zhang and Banghua Zhu}, title \= {DeepSeek-V4 on Day 0: From Fast Inference to Verified RL with SGLang and Miles}, year \= {2026}, url \= {https://www.lmsys.org/blog/2026-04-25-deepseek-v4/} }© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接