Elastic EP in SGLang: Achieving Partial Failure Tolerance for DeepSeek MoE Deployments
The Mooncake Team, Volcano EngineMarch 25, 20261. The Problem: The Necessity and Vulnerability of Wide EP
To serve massive Mixture-of-Experts (MoE) models efficiently, deploying a "wide" Expert Parallelism (EP) strategy—often spanning 32 GPUs or more per inference instance—is not just an option; it is a necessity. We need wide EP for two critical reasons:
- Maximizing Batch Size to Reduce Cost: Wide EP aggregates the massive VRAM required to support exceptionally large batch sizes. Maintaining a large batch size is the fundamental driver for reducing the overall cost per token in production.
- Minimizing TPOT for Faster Speeds: Scaling the aggregated memory bandwidth across these numerous GPUs directly reduces the Time Per Output Token (TPOT), ensuring fast, responsive generation.
However, scaling up the EP size introduces a severe reliability bottleneck. In traditional EP architectures, the "blast radius" (or failure diameter) is directly proportional to the size of the EP group. Because experts are rigidly bound to specific hardware, the larger the EP, the higher the statistical probability that a single hardware glitch or process failure will bring down the entire inference instance. When a failure occurs in the original setup, a full server restart is required. This process typically takes several minutes, causing massive resource waste, catastrophic downtime, and broken user experiences. SGLang's previous MoE mode did not natively support partial failure tolerance within a single instance, creating an urgent need for a solution that minimizes disruption to the existing system without sacrificing scale.
2. Solution Overview: Elastic EP and Its Potential
To solve the fragile nature of large-scale MoE inference, we integrated Elastic EP into the SGLang framework.
At its core, Elastic EP solves the failure problem by decoupling the rigid mapping between experts and specific GPUs. By maintaining redundant experts across the cluster, the system can detect a localized hardware or process failure, redistribute expert weights, and instantly reroute tokens to surviving experts. This ensures partial failure tolerance without halting the ongoing inference process. (Note: Dynamic process recovery is also under active development in PR #15771.)
The Effect
Implementing Elastic EP drastically improves system reliability without sacrificing speed.
- Service Recovers Within Seconds: To test extreme resilience, we ran DeepSeek V3.2 on 4 nodes (32 GPUs total, setting ep_size=dp_size=32) with 256 redundant experts, enabling tolerance of up to 16 rank failures. We then terminated a subset of running processes to simulate failures, benchmarked the system using sglang.bench_serving, and measured the time required to redistribute lost expert weights and restore service, based on EPLBManager logs. After recovery, the system continues inference correctly with lower overall throughput due to reduced resources. The results show that service interruption remains under 10 seconds—representing a 90% reduction compared to the 2–3 minutes typically required for a full restart.
| Number of failed ranks | Interruption time with Elastic EP (sec) | Throughput with remaining ranks (tokens/sec) |
|---|---|---|
| 1 | 6.8 | 5552.41 |
| 2 | 6.5 | 5431.50 |
| 4 | 6.8 | 5265.12 |
| 8 | 6.4 | 4479.84 |
| 16 | 6.2 | 2825.44 |
- Zero Static Performance Degradation: We evaluated DeepSeek V3.2 on a 4-node setup (2 prefill nodes, 2 decode nodes, with 8 GPUs each). Comparing key metrics, serving with our Elastic EP (Mooncake EP) matches the exact static performance of the standard DeepEP approach.
| System | Throughput (tokens/sec) | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|---|
| Elastic EP | 3560.21 | 19399.24 | 54.25 |
| Standard | 3626.38 | 21227.86 | 52.88 |
3. Detailed Structural Modifications
To achieve this, the solution introduces two key structural changes to the SGLang architecture:
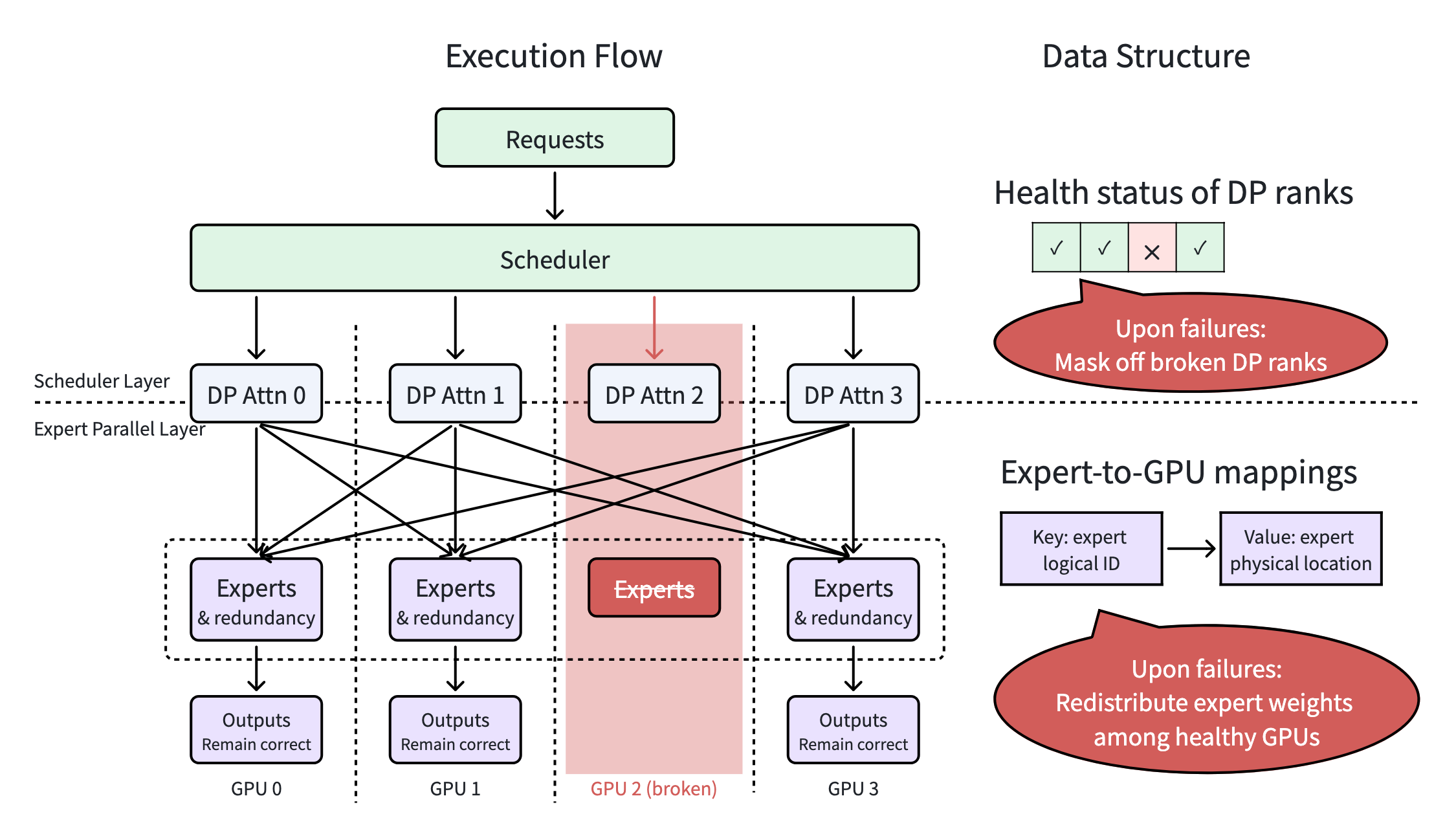
- Scheduler Layer (High-Level, Scheduling Focused): This layer acts as the system's gatekeeper. It continuously maintains the health status of the Data Parallel (DP) ranks. If a rank fails, the scheduler immediately filters it out, ensuring new batches and requests are only assigned to healthy resources. By doing so, it prevents inference tasks from routing to failed ranks, providing partial failure tolerance at the scheduling level with zero disruption. (Corresponding PR: #11657.)
- Expert Parallel Layer (Low-Level, Execution Focused): This layer handles the heavy lifting of dynamic fault tolerance. It manages failures within the EP groups by adjusting the expert-to-GPU mappings in real-time. When a failure happens, it instantly redistributes the required experts across the surviving EP members. This ensures the MoE inference mathematically resolves correctly and aligns with the available resources, avoiding heavy interruptions to the actual execution. (Corresponding PRs: #10423, #10606, #17374, #12068.)
Together, these two layers transform a fragile MoE pipeline into a highly resilient engine.

Figure: System diagram of Elastic EP, under a 4-GPU case.
4. Facilitating Elastic EP: The Role of Mooncake
To implement Elastic EP effectively, the system requires a highly resilient communication library capable of handling dynamic topology changes while ensuring the mathematically correct execution of MoE inference under partial failure conditions. Mooncake EP, a robust solution recognized within the broader PyTorch ecosystem, meets this exact need by serving as both the fault-tolerant backend and the core communication layer for Expert Parallelism.
By acting as the communication backbone, Mooncake EP provides several critical capabilities:
- Resilient General Collectives: It ensures strict fault tolerance for standard collective communication primitives, such as broadcast and allgather.
- Specialized EP Primitives: It delivers fault-tolerant handling for the specialized communication primitives essential to Expert Parallelism—specifically dispatch and combine—which are crucial for managing the sparse activation patterns inherent in large MoE models.
- High-Performance RDMA & Rapid Fault Detection: By heavily utilizing GPU Direct RDMA, Mooncake enables exceptionally high-throughput and low-latency token distribution across the cluster. Furthermore, it leverages this low-level network control to implement rapid, timeout-based fault detection mechanisms.
- Seamless SGLang Integration: Despite its complex underlying networking, the library is designed to integrate seamlessly with SGLang’s existing execution flow and scheduling logic. This plug-and-play compatibility minimizes the need for large-scale system restructuring while immediately unlocking partial failure tolerance.
5. Enabling Elastic EP
To enable Elastic EP when starting the SGLang server, use the following parameters:
- --elastic-ep-backend mooncake: Enable Mooncake as the fault-tolerant torch distributed backend.
- --moe-a2a-backend mooncake: Enable Mooncake as the EP communication backend.
- --mooncake-ib-device <comma-separated-ib-device-list>: Specify the IB devices used for Mooncake communication.
- --ep-num-redundant-experts <num>: Set the number of redundant experts for fault tolerance. The higher this value, the more rank failures the system can tolerate.
- --disable-custom-all-reduce: Disable the system’s default custom all-reduce.
- --enable-elastic-expert-backup: Enable expert weight backup in memory, allowing for fast recovery of weights during fault tolerance scenarios.
Note: NIXL EP is a recent implementation proposed by the NVIDIA Dynamo Team under the Elastic EP framework. Try it out by setting --moe-a2a-backend nixl.
Acknowledgment
We would like to thank everyone in the community who has contributed to or support this work.
- SGLang Core Team: Shangming Cai, Cheng Wan, Jingyi Chen, Lianmin Zheng, and many others.
- Mooncake Team: Xun Sun, Pingchuan Ma, Haoran Hu, Feng Ren, Mingxing Zhang, and many others.
- Volcano Engine: Han Han, Shan Lu, Qin Qi, Yang Zhang, and colleagues.
- Approaching AI: Yue Chen, Zhanhao Cao, Ke Yang, and colleagues.
- JD.com: Ziwei Yuan, Junlin Wei, Lianzhi Lin, and colleagues.
- Aliyun: Xinpeng Zhao, Xuchun Shang, Teng Ma, and colleagues.
We would like to extend our sincere gratitude to the NVIDIA Dynamo Team for their support and contributions.
Links
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接