The GB200 NVL72 is one of the most powerful hardware platforms in deep learning. This article continues from our previous blog post, sharing the SGLang team's optimization progress on DeepSeek V3/R1 inference performance using multiple techniques including FP8 attention, NVFP4 MoE, large-scale expert parallelism (EP), and prefill-decode separation. With FP8 attention and NVFP4 MoE, for 2000-token input sequences, SGLang achieves 26,156 input tokens/s for prefill and 13,386 output tokens/s for decode per NVIDIA Blackwell GPU, representing 3.8x and 4.8x improvements compared to the H100 configuration. Even with traditional BF16 attention and FP8 MoE, we reach 18,471 input tokens/s and 9,087 output tokens/s. Reproduction guidelines are available here.
Highlights
- SGLang achieves 26,156 input tokens/s for prefill and 13,386 output tokens/s for decode per NVIDIA Blackwell GPU on DeepSeek V3/R1 (2000-token input), 3.8x and 4.8x improvements over H100.
- With traditional precision (BF16 attention + FP8 MoE), still achieves 18,471 input tokens/s and 9,087 output tokens/s.
- FP8 attention and NVFP4 GEMM provide up to 1.8x and 1.9x improvements over original precision.
- Precision loss from FP8 attention and NVFP4 GEMM is negligible.
Optimization Methods
The following strategies have been applied:
- FP8 Attention: In addition to traditional BF16, we now support FP8 precision for KV cache in attention. This reduces memory access pressure during decoding, supports faster Tensor Core instructions, and improves decode attention kernel speed. Additionally, it increases KV cache token capacity, supporting longer sequences and larger batch sizes, further improving system efficiency.
- NVFP4 GEMM: Compared to classic FP8 GEMM, NVFP4 not only reduces GEMM memory bandwidth pressure but also utilizes more powerful FP4 Tensor Cores. Additionally, token dispatch communication traffic is halved, and weight memory usage is reduced, making it easier to expand KV cache space. Besides MoE experts, attention output projection GEMM can also be optionally quantized to NVFP4. Unlike NVIDIA's official checkpoint, we further execute q_b_proj with FP8 to improve performance.
- Scale Reduction via Offloading: Supports reducing EP scale. When device memory is insufficient, we utilize GB200's high-speed CPU-GPU bandwidth (900GB/s, bidirectional) to offload weights to host memory with prefetching. This reduces communication overhead and improves performance when compute slowdown is offset by communication benefits. The optimal scale depends on compute/communication kernels and model configuration. It also reduces GPU usage for single prefill instances, minimizing failure impact and reducing waiting time for the slowest rank.
- Compute-Communication Overlap: For higher communication bandwidth, we abandon previous two-batch overlap in favor of fine-grained overlap. We overlap combine communication with down GEMM and shared experts. We use atomic instructions with release semantics in GEMM signaling (multiple steps after TMA store commit) and employ cp.async.bulk.wait_group PTX instructions.
Kernel-level integrations/optimizations include:
- NVIDIA Blackwell DeepGEMM (prefill attention): A unified kernel supporting high-performance prefill and decode, integrated into the prefill path.
- FlashInfer Blackwell CuTe DSL GEMM (NVFP4 decode): Implements NVFP4 GEMM with masked layout using CuTe DSL, utilizing TMA and tcgen05.mma instructions (with 2CTA MMA), combined with persistent tile scheduling and warp specialization.
- FlashInfer Blackwell CUTLASS GEMM (NVFP4 prefill): Supports multi-datatype CUTLASS implementation with optimizations similar to CuTe version, suitable for high-throughput prefill.
- Flash Attention CuTe (BF16 KV-cache prefill): CuTe DSL framework implementing high-performance prefill MHA.
- FlashInfer Blackwell TensorRT-LLM Attention (decode and FP8 KV-cache prefill): Persistent scheduler based on cluster launch control, efficiently hiding prologue/epilogue, supporting BF16/FP8.
- Fused NVFP4 in DeepEP: DeepEP can optionally quantize token dispatch, fusing NVFP4 quantization, halving network traffic.
- Smaller kernel optimizations: Quantization/concatenation kernel fusion optimizations; FlashInfer MLA RoPE quantization kernel optimization; TensorRT-LLM kernel prototype optimization in FlashInfer, achieving 5% end-to-end acceleration and up to 2.5x for single kernels.
Experiments
End-to-End Performance
We evaluated DeepSeek's end-to-end performance on SGLang using GB200 NVL72, following the experimental setup from large-scale EP and GB200 Part 1. We evaluated both original precision (BF16 attention + FP8 MoE) and low precision (FP8 attention + NVFP4 MoE/output projection GEMM). Decode uses 48 ranks (large-scale EP); prefill uses 4 ranks/instance for high precision and 2 ranks for low precision. We used the CuTe DSL early access version.
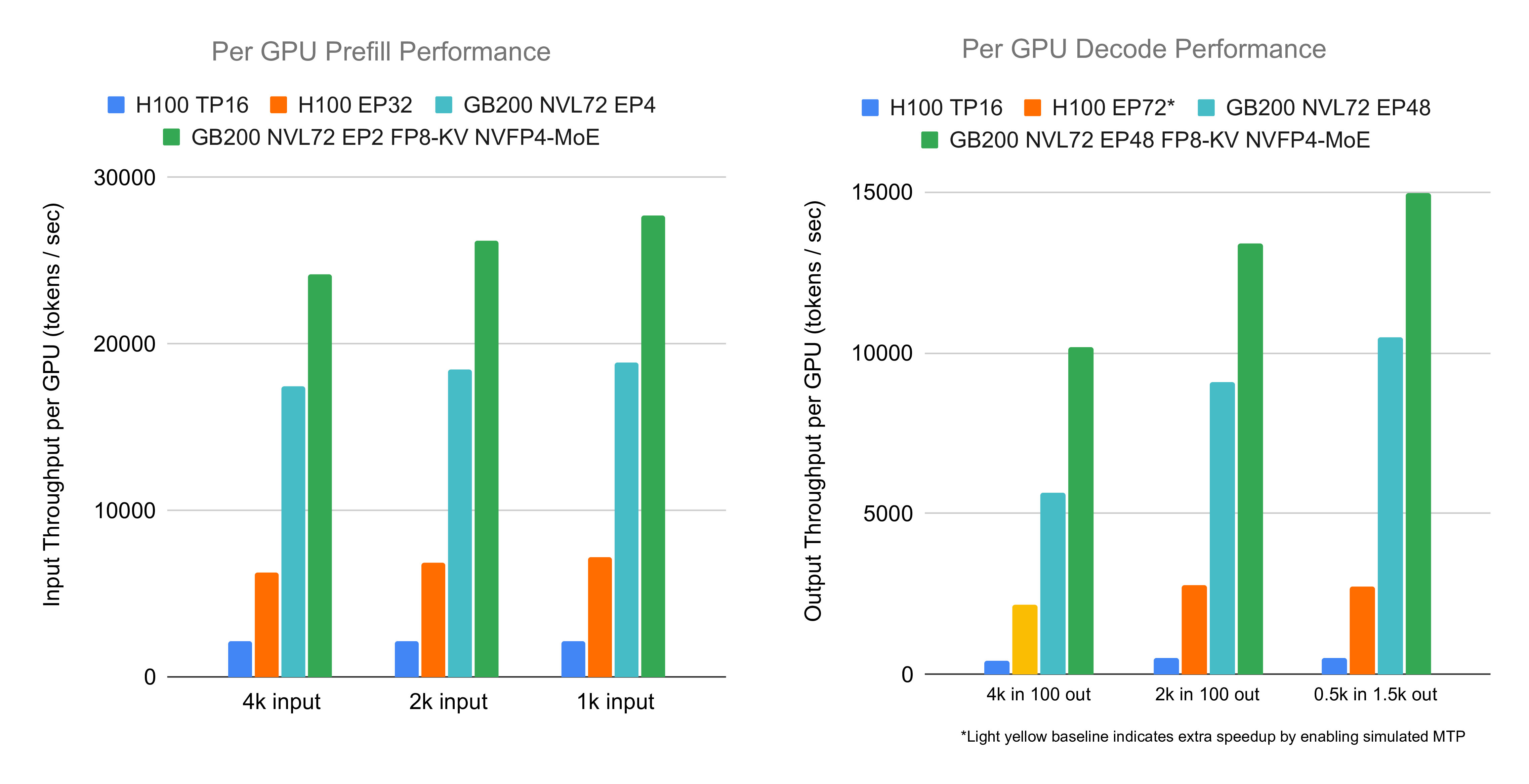
Experiments show GB200 achieves 3.8x prefill acceleration and 4.8x decode acceleration compared to H100. Main factors include:
- Low precision: Replacing BF16 attention with FP8 and FP8 GEMM with NVFP4 reduces computation/memory access, supporting larger batches.
- Faster kernels: Integration of high-performance attention/GEMM kernels, which comprise a large proportion of end-to-end time.
- Various optimizations: Overlap, offloading, small kernel acceleration/fusion, etc., contributing multiplicatively.
- Previous factors: Factors from the previous blog post apply to new prefill optimizations.
Note: High/low precision path differences include not only precision changes but also auxiliary kernels/strategies and EP balance (batch size maximizes KV cache utilization, e.g., 768 for 4k ISL, 1408 for 2k; reducing batch from 1408 to 768 for 2k decreases performance by about 10%).
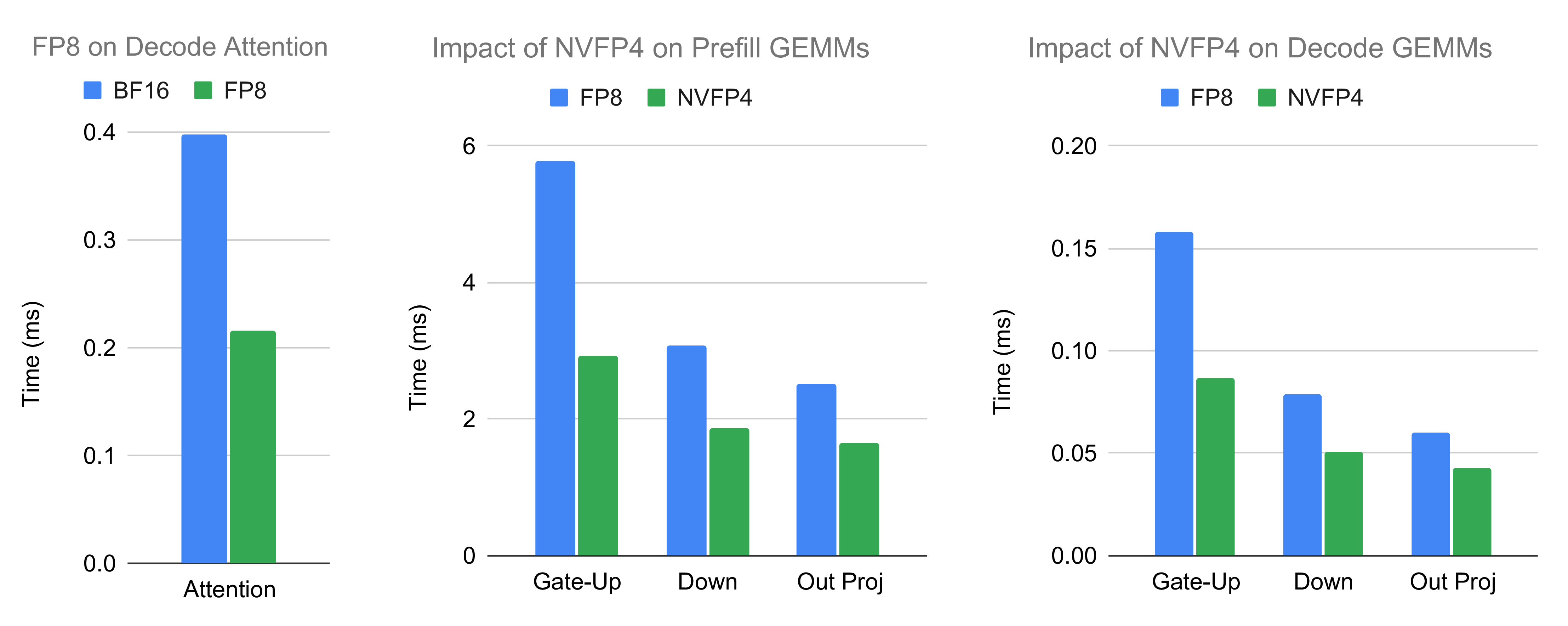
Low-Precision Kernel Amplification Analysis
We examine the impact of transitioning from standard to low-precision kernels for attention, MoE gate-up/down GEMM, and attention output projection GEMM. In typical cases, low precision significantly accelerates: 1.8x for attention, up to 1.9x for GEMM. Additionally, increased KV cache token capacity supports larger batches, improving performance.
Accuracy
Post-training quantization...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接