Thanks to NVIDIA's early access program, we had the opportunity to get hands-on with the NVIDIA DGX™ Spark. This is an extraordinary system, as NVIDIA rarely releases such compact all-in-one machines that condense supercomputing-level performance into a desktop workstation form factor.
Over the past year, SGLang has rapidly expanded its developer community in the data center space, renowned for its excellent inference performance. It has successfully deployed DeepSeek using Prefill-decode Disaggregation (PD) and Expert Parallelism (EP), running on 96 NVIDIA H100 GPU clusters and the latest GB200 NVL72 systems, continuously pushing the limits of large-scale inference performance and developer productivity.
Inspired by DGX Spark, SGLang is expanding from data centers to the consumer market for the first time, bringing mature inference frameworks directly to developers and researchers worldwide. This review will examine this exquisite device in detail, from its aesthetic design to performance benchmarks and application scenarios.
Also check out our video review here.

Design and Aesthetics
DGX Spark is a masterpiece of engineering aesthetics. The all-metal chassis features a champagne gold brushed finish, with front and rear panels utilizing metal foam technology, reminiscent of NVIDIA DGX A100 and H100 designs.
The rear panel offers rich connectivity: power button, four USB-C ports (leftmost supports up to 240W power delivery), HDMI port, 10 GbE RJ-45 ethernet port, and two QSFP ports (up to 200 Gbps) powered by NVIDIA ConnectX-7 NIC. These ports allow two DGX Spark units to interconnect for running larger AI models.
The USB Type-C power design is distinctive and rarely seen in other desktop machines. Compared to the C5/C7 power plugs on Mac Mini or Mac Studio, USB-C moves the power supply outside, freeing up internal cooling space. However, care must be taken to avoid accidental disconnection.

Hardware Specifications
In terms of hardware, DGX Spark delivers impressive performance within its compact size and power consumption. At its core is the NVIDIA GB10 Grace Blackwell Superchip designed specifically for this machine, integrating 10 Cortex-X925 performance cores and 10 Cortex-A725 efficiency cores, totaling 20 CPU cores.
On the GPU side, GB10 provides up to 1 PFLOP sparse FP4 tensor performance, with AI capabilities between RTX 5070 and 5070 Ti. The highlight is 128 GB coherent unified system memory, seamlessly shared between CPU and GPU, avoiding data transfer overhead between system and VRAM. With dual QSFP ethernet ports (aggregated 200 Gb/s bandwidth), two units can form a small cluster supporting distributed inference for larger models. NVIDIA states that two interconnected DGX Spark units can handle models up to 405 billion parameters in FP4.
The only shortcoming is memory bandwidth - the unified memory uses LPDDR5x with maximum 273 GB/s, shared between CPU/GPU. Subsequent testing confirms this as the main bottleneck for AI inference. Nevertheless, 128 GB memory enables it to run large models that most desktop systems cannot load.

Performance Testing
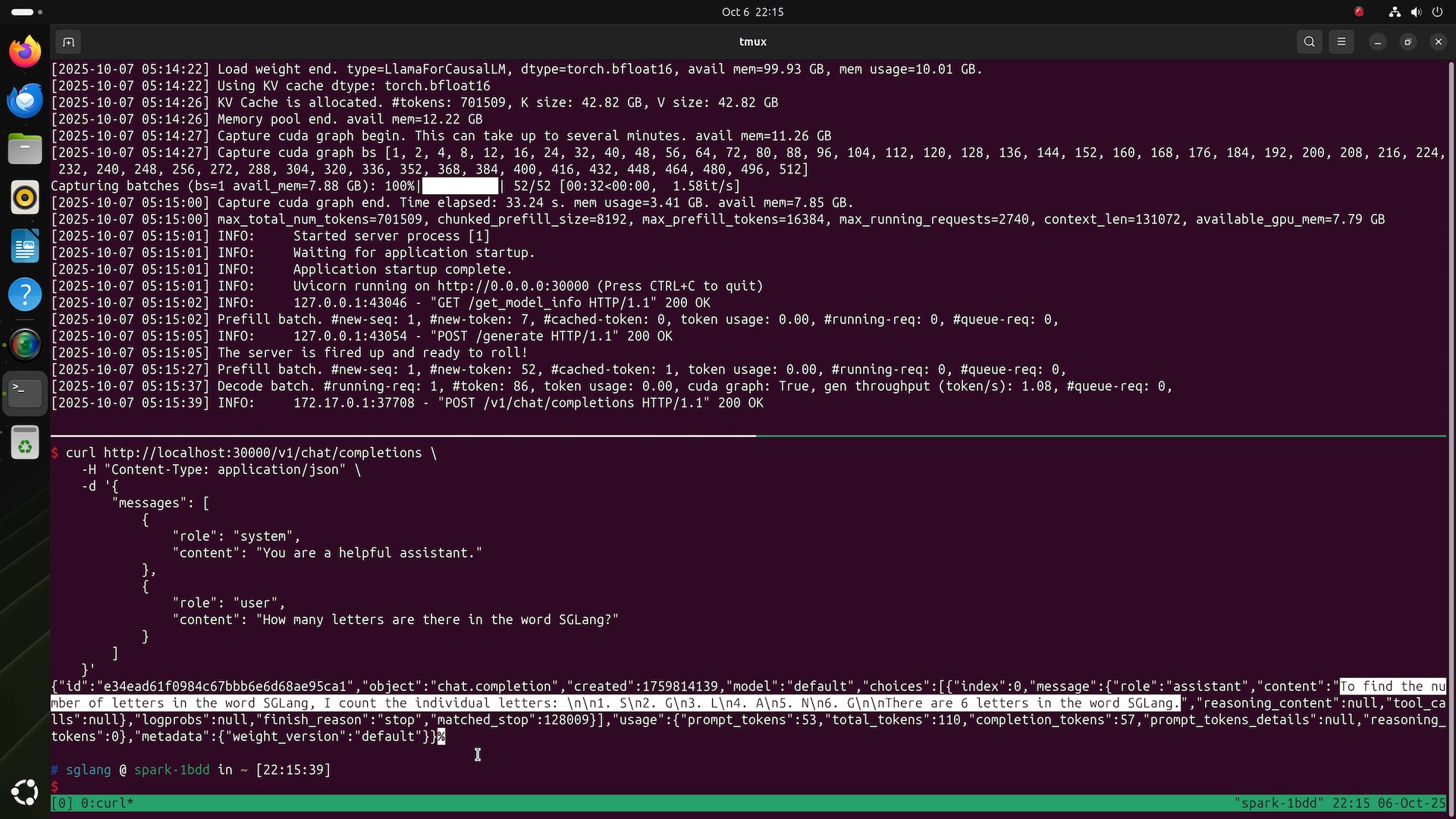
We benchmarked multiple open-source large language models on DGX Spark using SGLang and Ollama. Results show it can load and run ultra-large models like GPT-OSS 120B and Llama 3.1 70B, but is better suited for prototyping and experimentation rather than production environments. For smaller models, especially with batching enabled, performance is excellent.
Testing Methodology
⚠️ Note: Software support is still in early stages, benchmark results may become outdated with future updates.
Test Equipment
- NVIDIA DGX Spark
- NVIDIA RTX PRO™ 6000 Blackwell Workstation Edition
- NVIDIA GeForce RTX 5090 Founders Edition
- NVIDIA GeForce RTX 5080 Founders Edition
- Apple Mac Studio (M1 Max, 64 GB unified memory)
- Apple Mac Mini (M4 Pro, 24 GB unified memory)
Benchmark Models
We evaluated multiple open-source LLMs using SGLang and Ollama:
| Framework | Batch Size | Models & Quantization |
|---|---|---|
| SGLang | 1–32 | Llama 3.1 8B (FP8) Llama 3.1 70B (FP8) Gemma 3 12B (FP8) Gemma 3 27B (FP8) DeepSeek-R1 14B (FP8) Qwen 3 32B (FP8) |
| Ollama | 1 | GPT-OSS 20B (MXFP4) GPT-OSS 120B (MXFP4) Llama 3.1 8B (q4_K_M / q8_0) Llama 3.1 70B (q4_K_M) Gemma 3 12B (q4_K_M / q8_0) Gemma 3 27B (q4_K_M / q8_0) DeepSeek-R1 14B (q4_K_M / q8_0) Qwen 3 32B (q4_K_M / q8_0) |
We also tested speculative decoding (EAGLE3) with SGLang on select models, excluding those exceeding memory capacity.
Test Results
Full results available here.
Overall Performance
DGX Spark excels in engineering within its size and power constraints, but raw performance trails discrete GPU systems. For example, with Ollama GPT-OSS 20B (MXFP4), Spark achieves 2,053 tps prefill / 49.7 tps decode, while RTX Pro 6000 Blackwell reaches 10,108 tps / 215 tps, approximately 4x faster; RTX 5090 also achieves 8,519 tps / 205 tps. Unified LPDDR5x bandwidth is the main limitation.
For smaller models like Llama 3.1 8B, SGLang batch 1 achieves 7,991 tps prefill / 20.5 tps decode, scaling linearly to 7,949 tps / 368 tps at batch 32, demonstrating excellent batching efficiency.
Unified Memory Advantage
128 GB coherent unified memory is the core highlight, with CPU/GPU sharing address space. Large models like Llama 3.1 70B, Gemma 3 27B, or GPT-OSS 120B can be loaded directly without transfer overhead. Llama 3.1 70B (FP8) achieves 803 tps prefill / 2.7 tps decode, impressive for desktop-class hardware. Ideal for prototyping, model experimentation, and edge AI research.
Speculative Decoding Acceleration
Enabling SGLang EAGLE 3 speculative decoding, where smaller "draft" models pre-generate tokens and larger models verify in parallel, achieves up to 2x speedup in end-to-end throughput for models like Llama 3.1 8B. Software optimization effectively mitigates bandwidth bottlenecks.
Efficiency and Cooling
No thermal throttling under high loads - for example, SGLang DeepSeek-R1 14B (FP8) batch 8 achieves 2,074 tps / 83.5 tps, with stable fan noise and temperature, thanks to metal foam cooling and optimized power delivery. USB-C 240W input + external PSU provides greater thermal headroom than Mac Mini/Studio.

Summary
DGX Spark isn't designed to compete head-to-head with full-size Blackwell/Ada GPUs, but rather to condense the DGX experience into a developer-friendly compact form factor. Ideal for:
- Model prototyping and experimentation
- Lightweight on-device inference
- Research on memory-coherent GPU architectures
It's a beautifully engineered mini supercomputer that trades raw performance for accessibility.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接