SGLang-JAX 现已支持 inclusionAI 的 Ling-2.6-1T 在 TPU v7x 上高效部署。基线运行后,性能分析指出 Mixture-of-Experts(MoE)路径为主要瓶颈:每层需将 token 散射至 32 个 JAX 设备(每 v7x 芯片两设备)、运行专家 FFN,再收集输出。本文重点介绍 Fused MoE V2——一个全新的 Pallas 内核,它将 scatter、expert FFN 与 gather 融合,同时隐藏 TPU 计算与数据移动。
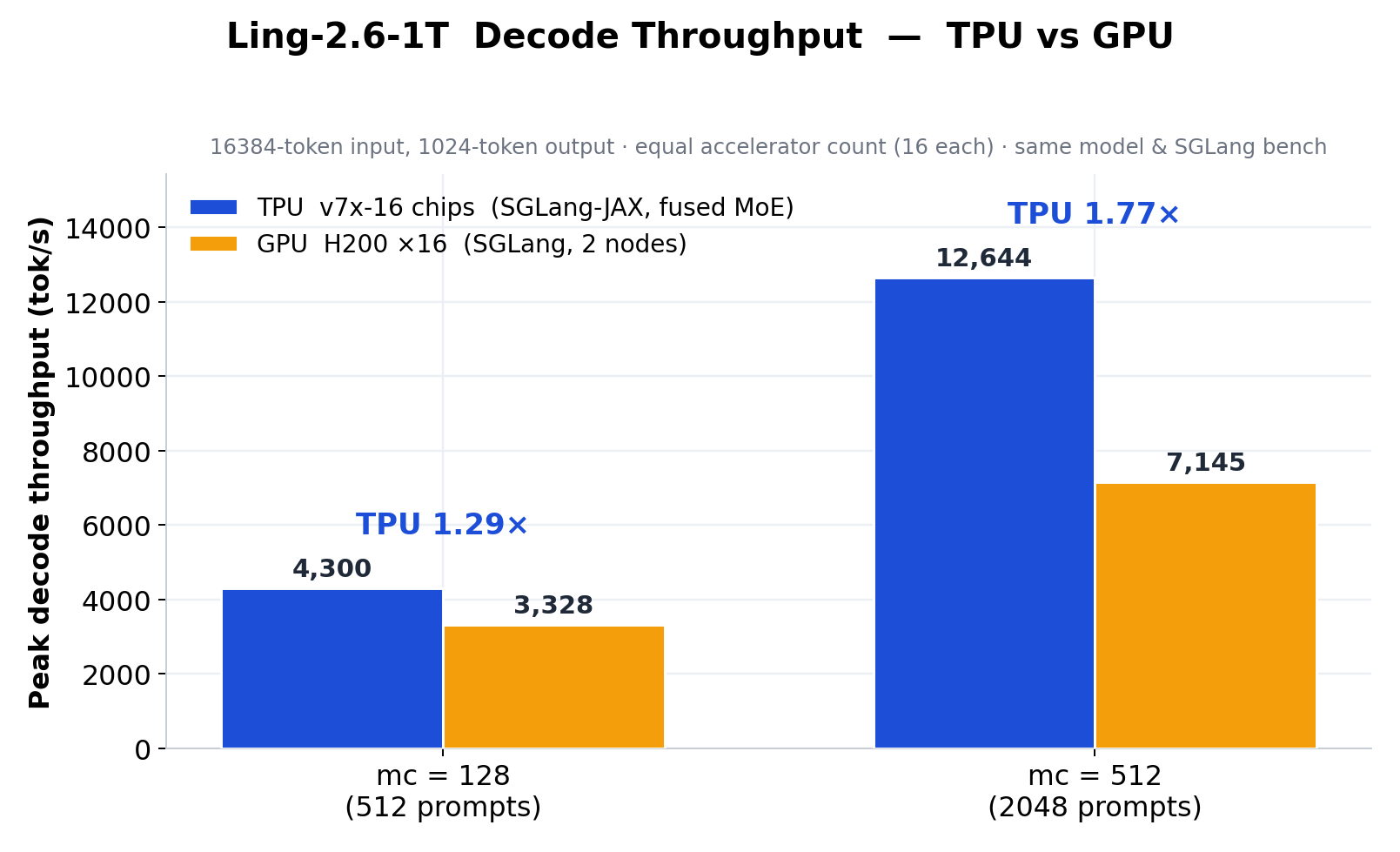
借助 Fused MoE V2,MoE prefill 延迟从 5.16 ms 降至 2.42 ms,相同 SGLang decode 基准下,16 块 TPU v7x 芯片的输出吞吐达到 16 张 H200 GPU 的 1.29×–1.77×。
TL;DR
- Fused MoE V2:MoE prefill 延迟较 V1 下降 53%(5.16→2.42 ms),decode 内核延迟下降约 15%(0.249→0.211 ms)。
- 端到端收益:仅替换 MoE 内核即可使 prefill 吞吐提升 24.8%,decode 吞吐提升 18.5%–35.3%。
- TPU vs H200:TPU v7x-16 在 mc=128 时 decode 输出吞吐为 H200×16 的 1.29 倍,在 mc=512 时达到 1.77 倍。
Ling-2.6-1T 模型概览
Ling-2.6-1T 是一个 1T 参数稀疏 MoE 模型,每 token 激活 63B 参数,包含 256 个 routed expert(top-8 路由)加一个 shared expert,采用 per-channel fp8 权重与 MLA + Lightning Linear 混合骨干网络。
融合 MoE 内核优化
所有 MoE 数据来自 jax.profiler 设备 trace。测试环境为 16 芯片 TPU v7x slice(ep=32,2×2×4 ICI 环面,每芯片两设备),输入 16,384 token prefill 与 512 token decode batch。
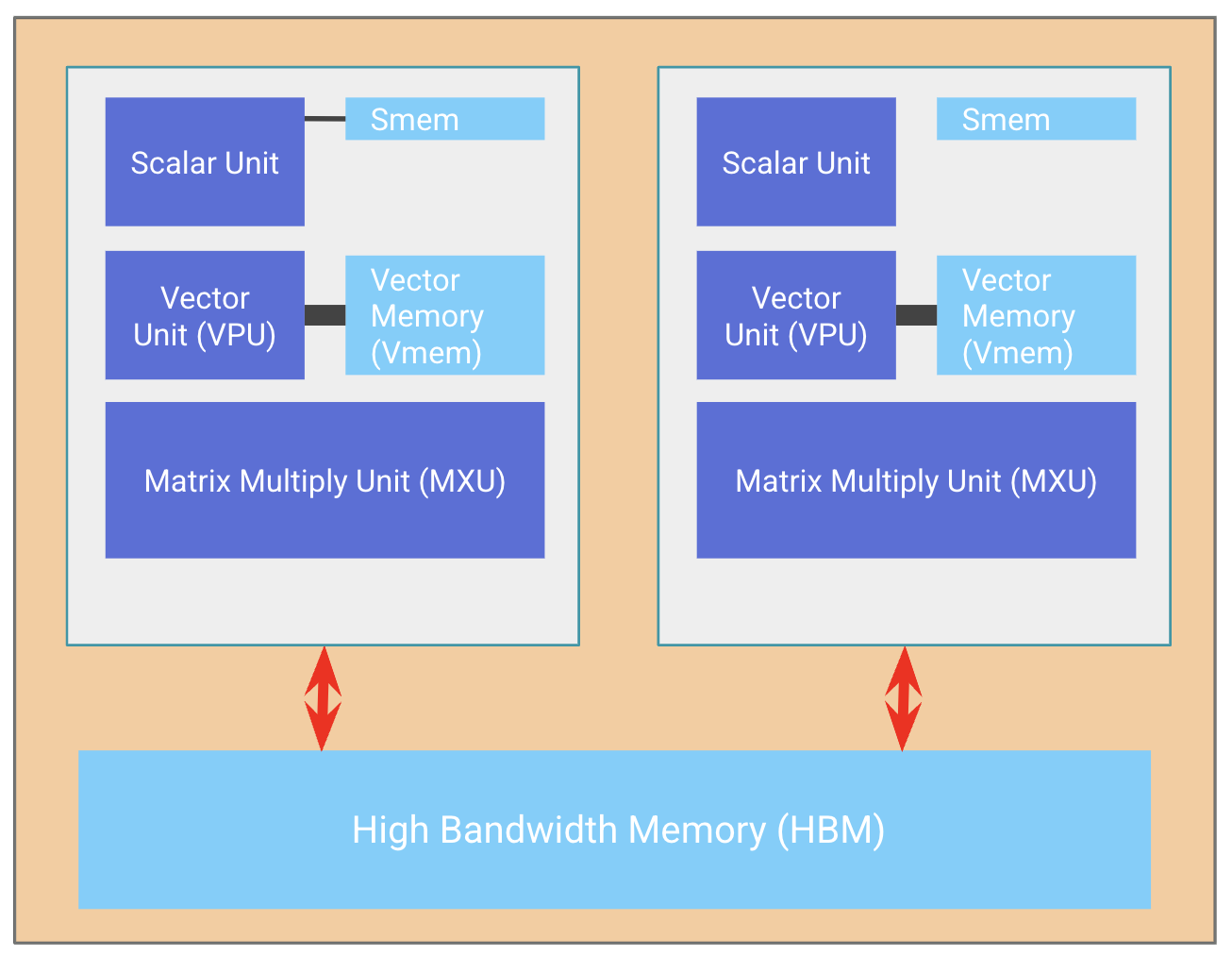
1. MoE 内核成本模型
每设备拥有 8 个本地 routed expert。routed 路径为 scatter → local expert FFN → gather。理想计算下限约为 0.36 ms,而实测 2.42 ms 仍高出约 7 倍,表明数据移动是瓶颈。

2. 为何需要 Pallas 融合内核
纯 JAX 无法精细调度单层 MoE 内部的 ICI-DMA、HBM 预取与 MXU 重叠。Fused MoE V2 通过双缓冲与流水线隐藏权重预取。
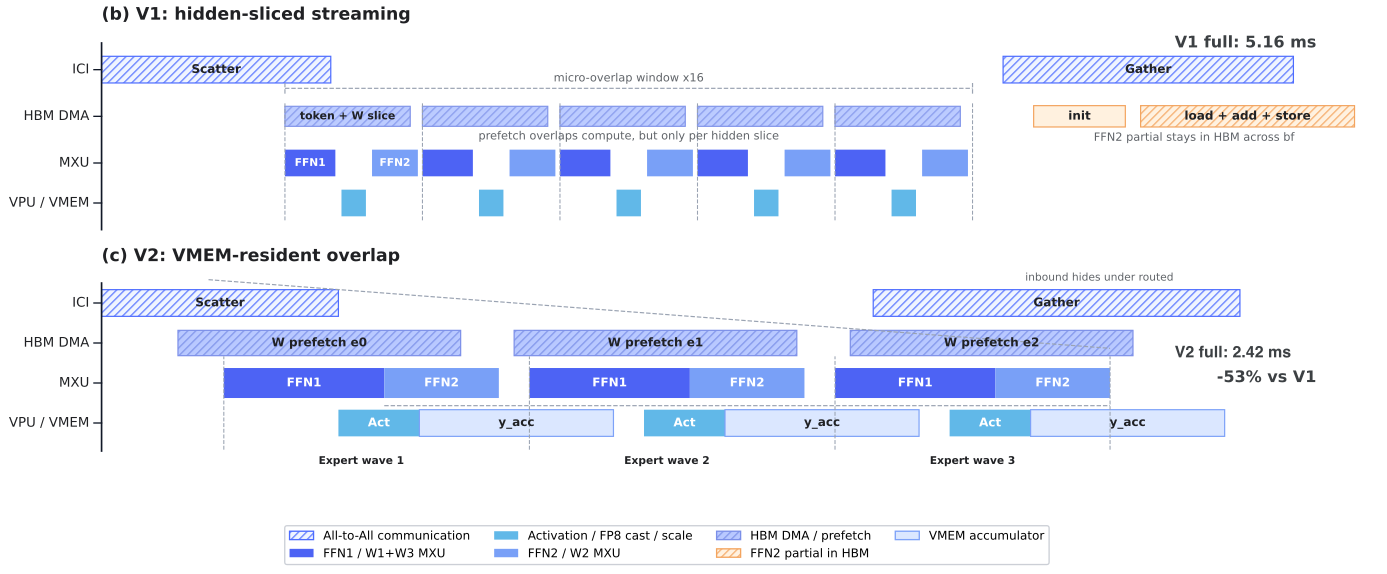
3. 性能结果
prefill 关键路径 breakdown 与吞吐对比显示 V2 显著优于 V1。
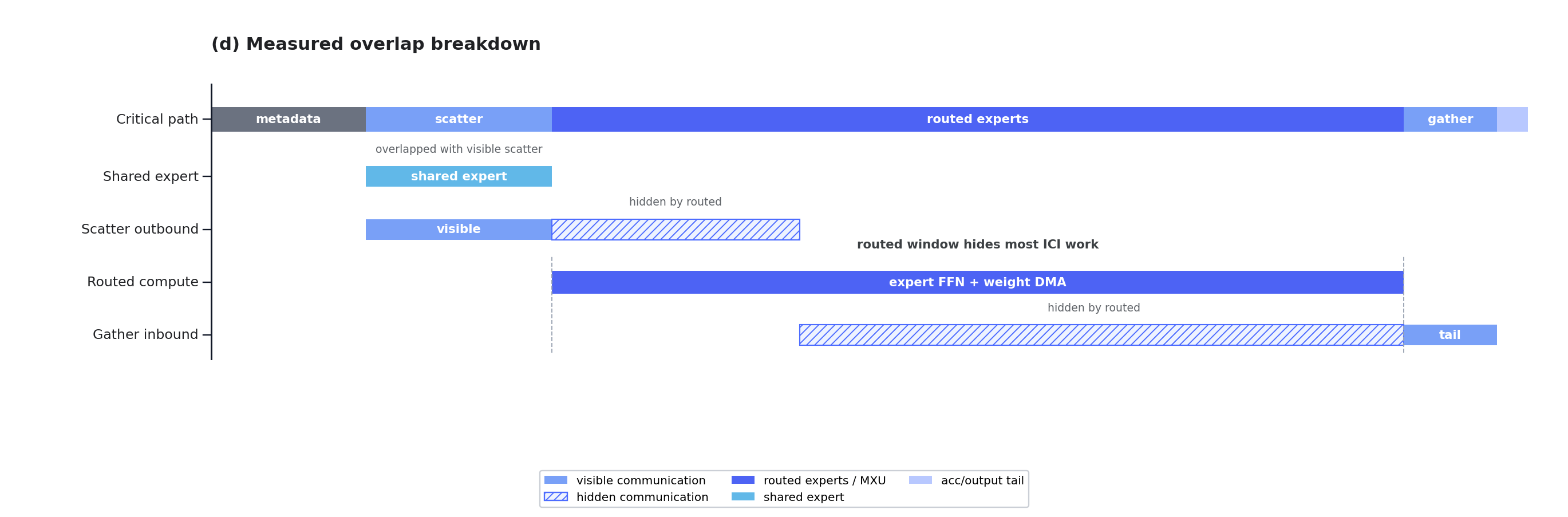
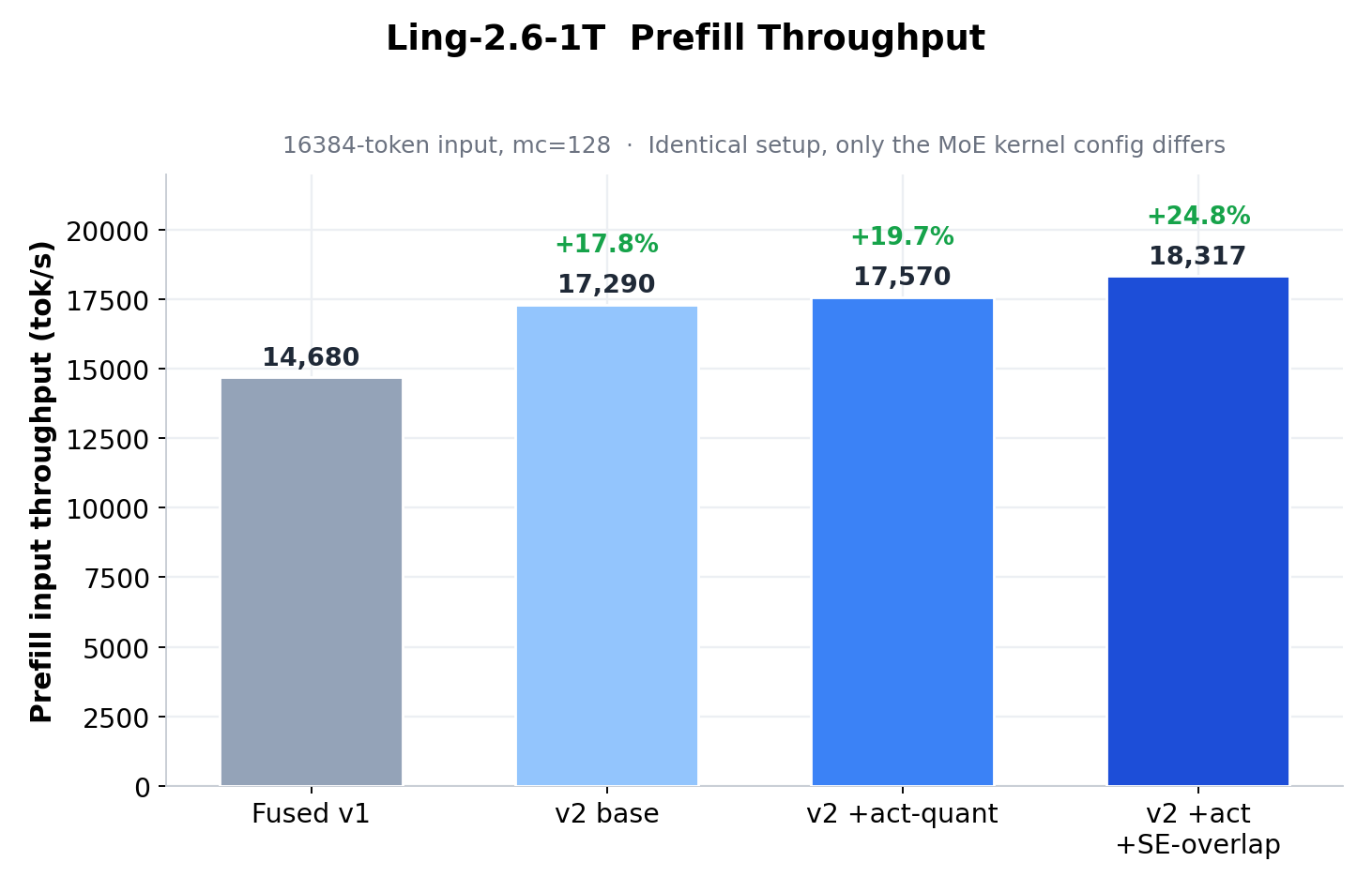
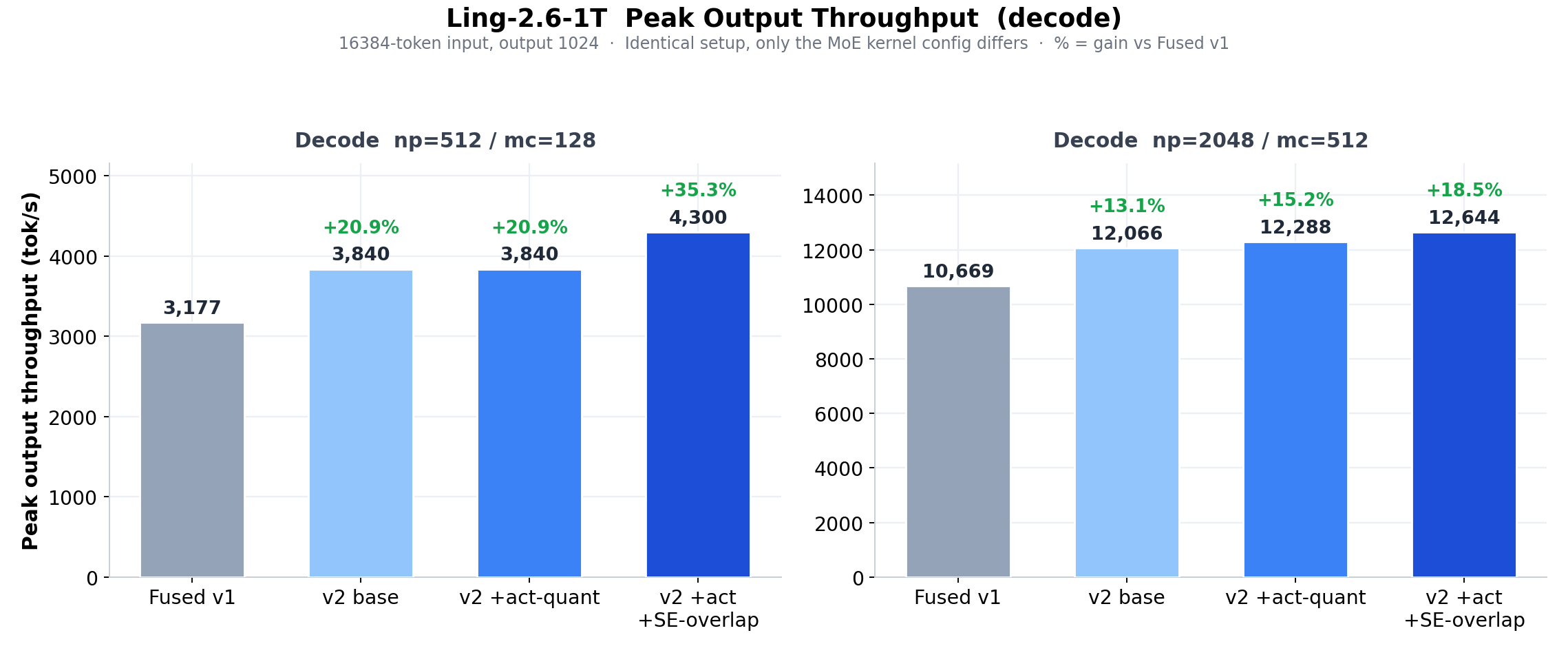
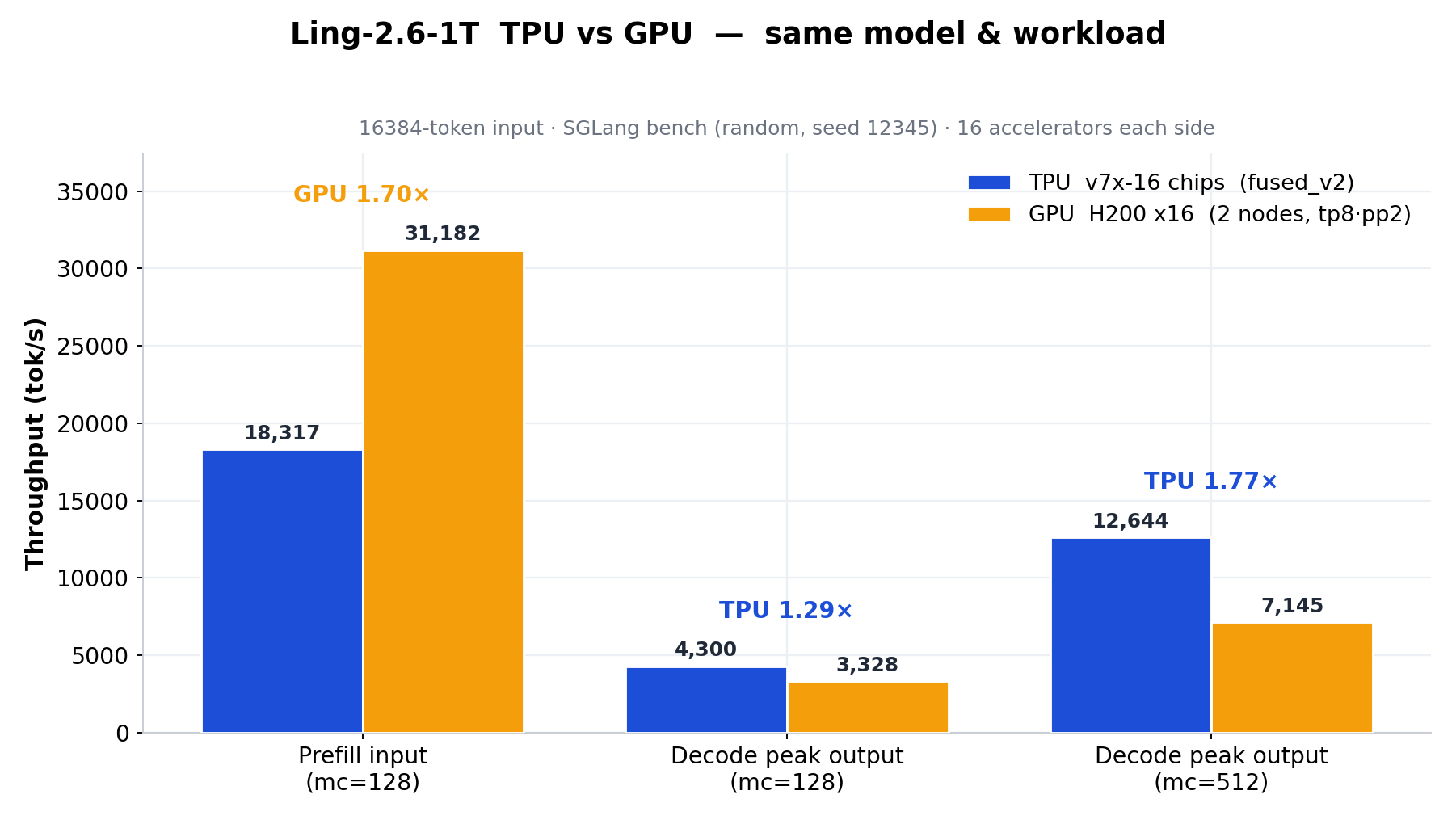
最终 16 块 TPU v7x 在相同模型与负载下全面超越 16 张 H200。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接