This article presents our preliminary results on supporting a new serving paradigm called PD-Multiplexing in SGLang. This paradigm aims to bring higher goodput to LLM serving. It fully leverages GreenContext—a new technology from NVIDIA GPUs that supports lightweight, fine-grained partitioning of GPU resources within the same process, enabling efficient resource sharing across tasks. We believe this represents a powerful new path for Model-as-a-Service (MaaS) deployment, offering stronger SLO guarantees and higher goodput.
Goodput Challenges in LLM Serving: A Persistent Problem
Large-scale MaaS deployment requires LLM serving systems to consistently meet strict Service Level Objectives (SLOs) without sacrificing throughput. In practice, this means guaranteeing latency SLOs for both inference phases: Time-to-First-Token (TTFT) for the prefill phase, and Inter-Token Latency (ITL, also known as Time-Between-Tokens, TBT) for the decode phase. The challenge lies in the fact that prefill and decode execute alternately on the same serving instance, leading to GPU resource contention. Common solutions include:
- Instance-level PD separation: Placing prefill and decode on different instances. However, this requires static partitioning of GPU resources, and KV cache migration across instances introduces complexity, requiring high-performance interconnects and communication libraries.
- Sequence-level chunked-prefill: Breaking long sequences into small chunks and fusing them with decode iterations to control ITL. This requires balancing chunk size: too small affects ITL guarantees, too large reduces GPU utilization.
These limitations become increasingly apparent when dealing with the tight SLO thresholds of real-world LLM services.
PD-Multiplexing: A New Paradigm for Efficient Serving
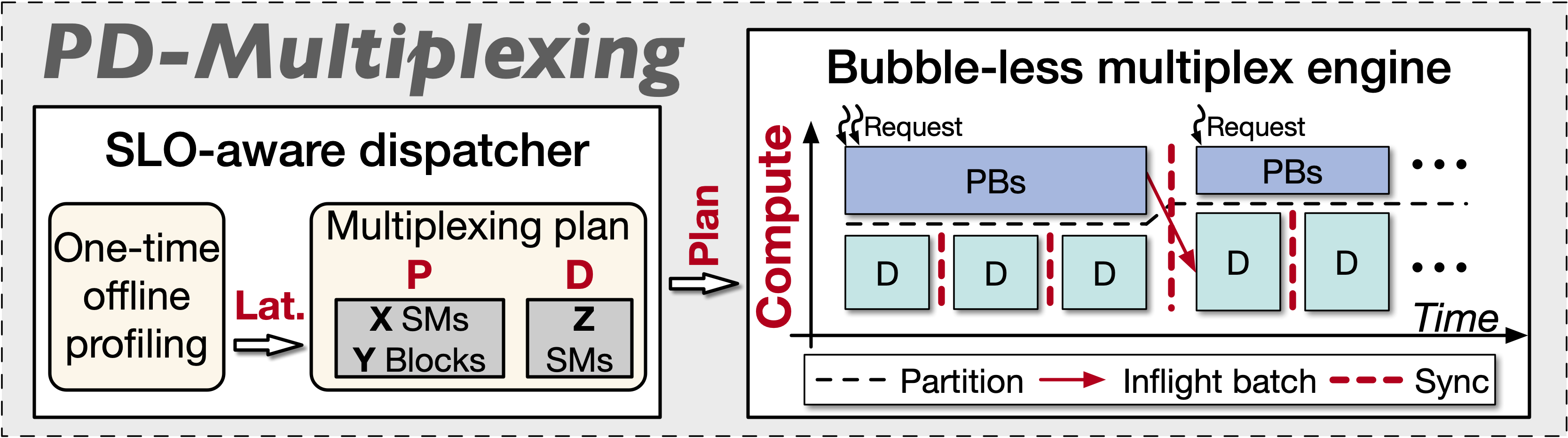
To address these issues, we propose PD-Multiplexing, a new paradigm that achieves multiplexing of prefill and decode through intra-GPU spatial sharing within the same instance. Key advantages include:
- Prefill and decode share the KV cache pool of the same instance, eliminating expensive cross-instance migration.
- GPU compute resources (SMs) can flow dynamically, allocating between prefill and decode as load changes.
- Decoupled execution ensures prefill performance remains unaffected while meeting strict ITL SLOs.
As shown in Figure 1, the core of this paradigm includes a bubble-free multiplexing engine (executing prefill/decode independently and efficiently) and an SLO-aware scheduler (iteratively generating compliant multiplexing plans).
Bubble-Free Multiplexing Engine via GreenContext
We build this paradigm using GreenContext (introduced in CUDA 12.4, with support for dedicated SM allocation across multiple CUDA streams in 12.6), enabling intra-process spatial sharing. GPU resources can be dynamically partitioned in real-time to adapt to SLOs, workloads, and other requirements.
To maintain the existing architecture, we use single-threaded scheduling to multiplex prefill/decode (avoiding Python GIL limitations), leveraging asynchronous features to switch between dedicated GreenContext streams.
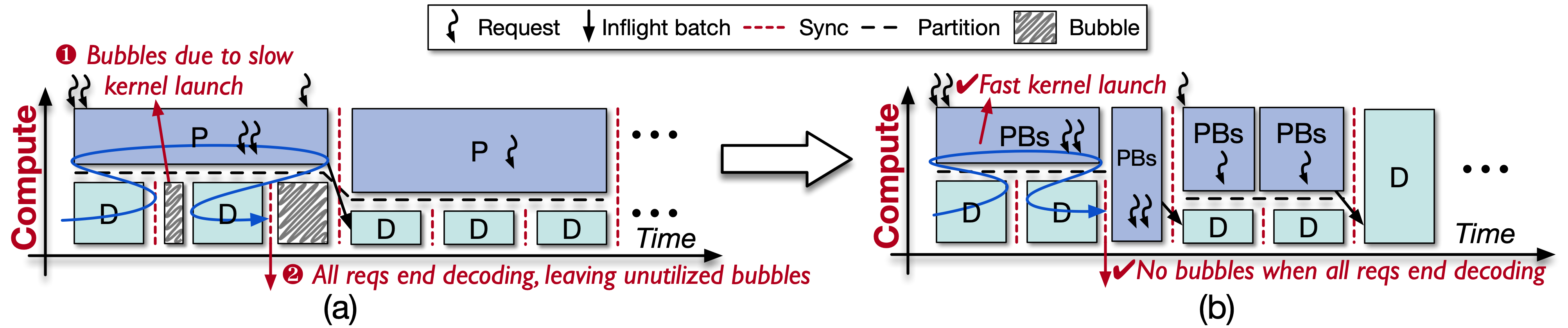
However, direct integration of GreenContext produces GPU bubbles (as shown in Figure 2(a)): (1) prefill launch time is much longer than decode (single CUDA graph); (2) decode iterations are uncertain, with early termination causing SM idleness. To address this, we split prefill into small chunks (as in Figure 2(b)). Since prefill is compute-intensive, this overhead is negligible, effectively eliminating bubbles.
Performance Profiling and Scheduling Strategy Design
With the bubble-free engine in place, the next step is scheduling prefill chunks and decode batches. Offline profiling shows that both phases compete for resources under GreenContext (SM partitioned but memory bandwidth shared). We use offline profiling of representative workloads to train latency predictors that drive SLO-aware scheduling (details vary by model/hardware; tutorials to be provided in the future).
Scheduling intuition: Allocate just enough SMs to decode to meet ITL SLO, give the rest to prefill, while determining the number of prefill chunks. This way, decode strictly complies with SLO while prefill maximizes progress to expand decode batches.
Benchmarks
We compare against various baselines and evaluate PD-Multiplexing across multiple workloads/devices. We first show easily reproducible experiments, then demonstrate advantages using real traces, and finally visualize scheduling details. In comprehensive evaluations, PD-Multiplexing achieves up to 3.06x goodput improvement.
* The following results are for research purposes. In practical applications, SLOs are more specific; here we demonstrate the potential of PD-Multiplexing.Comparison with Chunked-prefill at Different Chunk Sizes
Running CodeLlama-34b-hf on a single H200, we compare chunked-prefill with different chunk sizes. Figure 3 reports P99 TTFT and ITL, with ITL SLO target of 60ms (TTFT unconstrained, only P99 reported). Solid points indicate meeting ITL SLO, hollow points indicate violations.
PD-Multiplexing provides the fastest TTFT while consistently meeting strict ITL SLOs. Chunked-prefill requires chunk size below 1024 for compliance, but this harms prefill performance and GPU utilization, especially noticeable with long contexts like LooGLE. For reproduction details, see here.
Real Workload Results
Using real trace Mooncake-Tool&Agent for evaluation, we compare against chunked-prefill (chunk=512) and PD-disaggregation (P:D=1:1, both based on SGLang), on 8xA100s, Llama3.1-70B, with prefix cache sharing enabled.
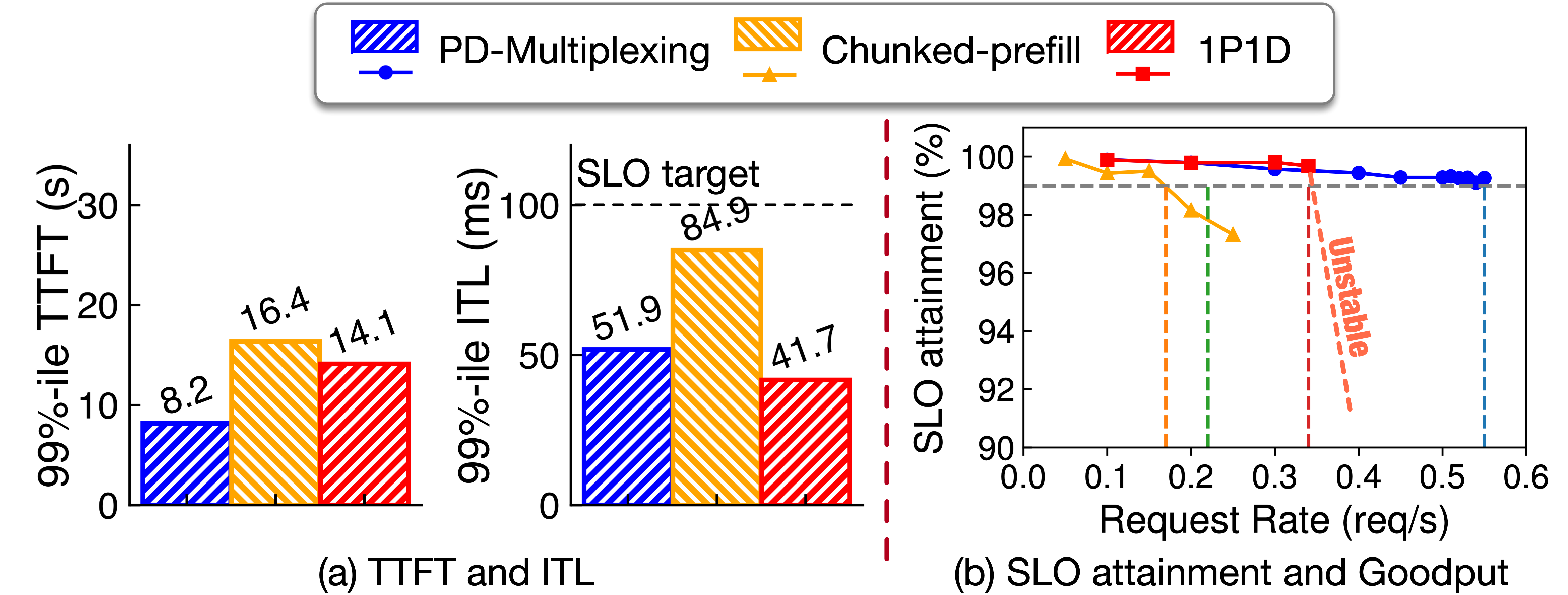
Figure 4(a) shows TTFT and ITL: PD-Multiplexing outperforms chunked-prefill; compared to PD-disaggregation, it achieves shorter TTFT, with both meeting decode SLO. To evaluate goodput, we gradually increase request rate and measure SLO achievement rate. As shown in Figure 5, PD-Multiplexing...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接