We are thrilled to announce that SGLang has achieved Day 0 support for DeepSeek-V3.2! According to DeepSeek's technical report, DeepSeek-V3.2 equips DeepSeek-V3.1-Terminus with DeepSeek Sparse Attention (DSA) through continual training, a fine-grained sparse attention mechanism powered by Lightning Indexer that achieves significant improvements in training and inference efficiency, especially in long-context scenarios. Interested in more upcoming features? Check out our roadmap.
Installation and Quick Start
To get started quickly, simply pull the container and launch SGLang as follows:
NVIDIA GPU
docker pull lmsysorg/sglang:v0.5.3-cu129
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --enable-dp-attentionAMD (MI350X/MI355X)
docker pull lmsysorg/sglang:dsv32-rocm
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "aiter"
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "tilelang"
NPU
# NPU A2
docker pull lmsysorg/sglang:dsv32-a2
# NPU A3
docker pull lmsysorg/sglang:dsv32-a3
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --trust-remote-code --attention-backend ascend --mem-fraction-static 0.85 --chunked-prefill-size 32768 --disable-radix-cache --tp-size 16 --quantization w8a8_int8Detailed Description
DeepSeek Sparse Attention: Unlocking Long-Context Efficiency
At the core of DeepSeek-V3.2 is DeepSeek Sparse Attention (DSA), a fine-grained sparse attention mechanism that redefines long-context efficiency.
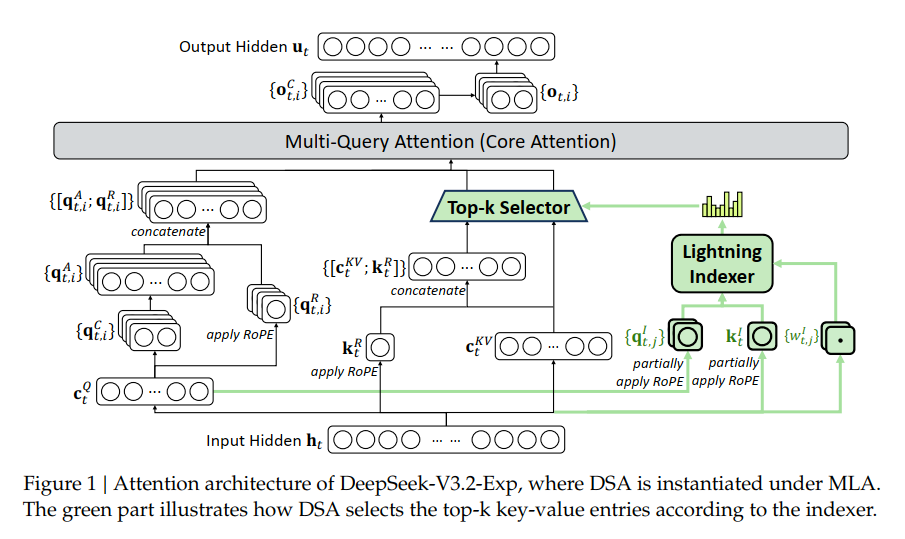
DSA abandons quadratic full attention computation over all tokens and instead introduces:
- Lightning Indexer (ultra-lightweight FP8 scorer) to identify the most relevant tokens for each query.
- Top-k Token Selection, computing only on the most influential key-value entries.
This design reduces core attention complexity from O(L2) to O(Lk), achieving significant efficiency improvements in training and inference for context lengths up to 128K, with virtually no loss in model quality.
To support this breakthrough, SGLang has implemented and integrated:
- Lightning Indexer Support – Dedicated
key&key_scalecache in the memory pool for ultra-fast token scoring. - Native Sparse Attention (NSA) Backend – A new backend designed for sparse workloads, including:
- FlashMLA (DeepSeek's optimized multi-query attention kernel)
- FlashAttention-3 Sparse (adapted for compatibility and maximum kernel reuse)
- Additional optimization: Support for different page sizes within the same attention backend:
- Indexer
key&key_scalecache requires page size = 64 (from kernels provided by DeepSeek) - Token-level sparse forward operators require page size = 1
- Indexer
These innovations enable DeepSeek-V3.2-Exp to achieve GPU-optimized sparse attention and dynamic cache management, drastically reducing memory overhead and seamlessly scaling to 128K contexts. The end result is significantly reduced inference costs while preserving state-of-the-art inference quality — making long-context LLM deployment not just feasible, but practical at scale.
Future Work
Future work will be tracked here. Specific plans include:
- Multi-token Prediction (MTP) Support coming soon: MTP will accelerate decoding, especially when batch sizes are not large.
- FP8 KV Cache: Can nearly double the number of tokens in KV cache compared to traditional BF16 KV cache and halve memory access pressure in attention kernels, thereby serving longer contexts or more requests faster.
- TileLang Support: TileLang kernels facilitate flexible development.
Acknowledgments
We sincerely thank the DeepSeek team for their outstanding contributions to open-source model research, which greatly benefits the open-source community, and for their efficient kernels integrated into the SGLang inference engine.
Thanks to SGLang community members Tom Chen, Ziyi Xu, Liangsheng Yin, Biao He, Baizhou Zhang, Henry Xiao, Hubert Lu, Wun-guo Huang, Zhengda Qin, and Fan Yin for their contributions to DeepSeek-V3.2-Exp support.
We also thank NVIDIA, AMD, and Nebius Cloud for sponsoring the GPU machines used for this work's development.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接