TL;DR: This article shares SGLang's efforts to achieve deterministic inference and progress in promoting reproducible RL training in collaboration with slime.
Recently, Thinking Machines Lab published a blog post detailing their research findings. Since then, the industry has responded enthusiastically, expecting open-source inference engines to achieve stable and practical deterministic inference, and even further enable fully reproducible RL training. Now, SGLang and slime have joined forces to provide solutions.
Based on Thinking Machines Lab's batch-invariant operators, SGLang achieves fully deterministic inference while maintaining compatibility with chunked prefill, CUDA graphs, radix cache, and non-greedy sampling. With CUDA graphs enabled, SGLang delivers 2.8x acceleration, reducing performance overhead to 34.35% (compared to TML's 61.5%).
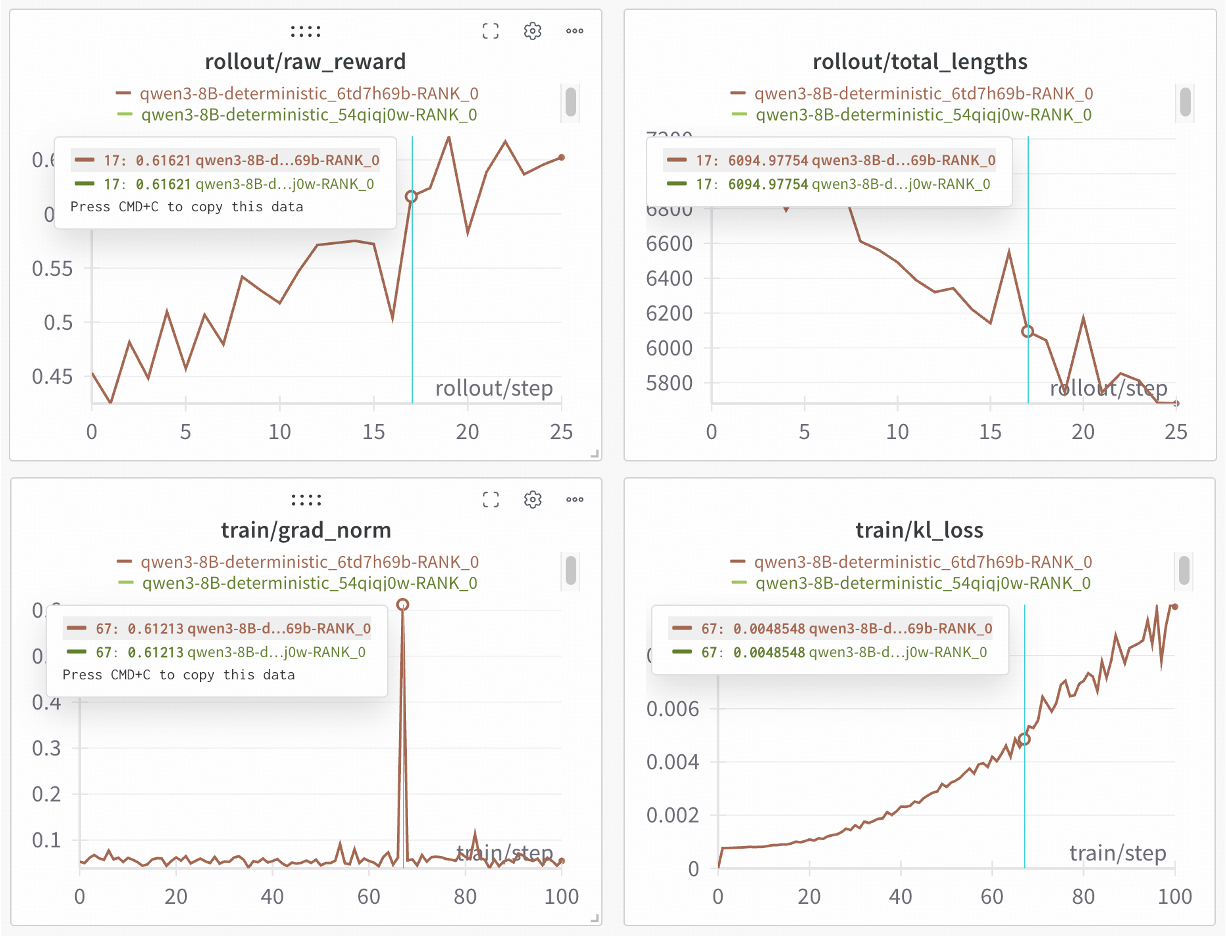
Building on this foundation, SGLang collaborated with the slime team to further unlock 100% reproducible RL training—achievable with minimal code modifications. Validation experiments on Qwen3-8B show that two independent training runs produce identical curves, providing reliable guarantees for rigorous scientific experiments.
Why Deterministic Inference Matters
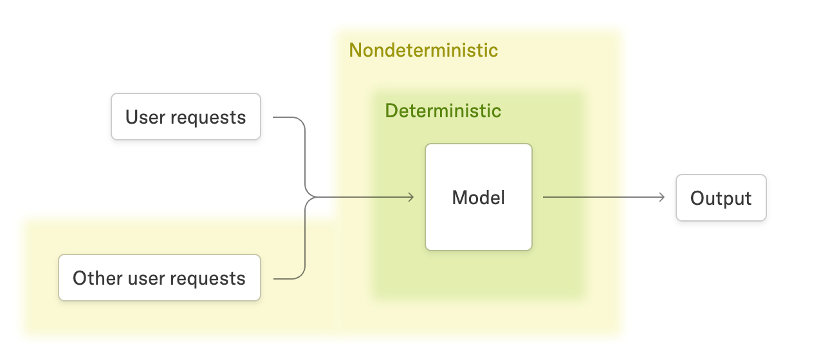
The ability to produce consistent outputs in Large Language Models (LLMs) inference is becoming increasingly important. For example, non-determinism in inference results may implicitly transform on-policy reinforcement learning (RL) into off-policy RL (as researchers have pointed out). Even when temperature is set to 0 in SGLang, sampling remains non-deterministic due to the effects of dynamic batching and radix cache (see past discussions here).
As noted in the TML blog, the biggest source of non-determinism comes from batch size variations: when users repeatedly submit the same prompt, differences in batch sizes due to batching with other requests lead to non-deterministic outputs. Specifically, different batch sizes affect the reduction splitting of kernels, causing variations in the order and size of reduction blocks. Due to the non-associativity of floating-point operations, this produces non-deterministic outputs. To solve this problem, they replaced reduction kernels (RMSNorm, matrix multiplication, attention, etc.) with batch-invariant implementations and open-sourced them as a companion library.
He, Horace and Thinking Machines Lab, "Defeating Nondeterminism in LLM Inference", Thinking Machines Lab: Connectionism, Sep 2025.
Building on TML's work, SGLang provides a high-throughput deterministic LLM inference solution, combining batch-invariant kernels, CUDA graphs, radix cache, and chunked prefill with high performance efficiency. Determinism is validated through comprehensive testing and RL training experiments.
Key enhancements include:
- Integration of TML's batch-invariant kernels, including mean, log-softmax, and matrix multiplication kernels.
- Implementation of batch-invariant attention kernels with fixed split-KV sizes, supporting multiple backends including FlashInfer, FlashAttention 3, and Triton.
- Full compatibility with common inference features such as chunked prefill, CUDA graph, and radix cache, all supported in deterministic mode.
- Exposed per-request seed, allowing deterministic inference even when temperature > 0.
- Performance optimization: Compared to TML blog's 61.5% slowdown, SGLang averages only 34.35% on FlashInfer and FlashAttention 3 backends, achieving 2.8x acceleration with CUDA graphs.
Experimental Results
Verifying Deterministic Behavior
We introduce a deterministic test suite to verify inference result consistency under different batching conditions. The test covers three sub-tests from simple to complex:
- Single: Same prompt run under different batch sizes, checking output consistency.
- Mixed: Short/long prompts mixed in the same batch, verifying consistency.
- Prefix: Different prefix-length prompts derived from the same long text, randomly batched, testing reproducibility.
Results from 50 sampling trials, where numbers indicate unique output counts for each sub-test (lower is more deterministic).
| Attention Backend | Mode | Single Test | Mixed Test (P1/P2/Long) | Prefix Test (prefix_len=1/511/2048/4097) |
|---|---|---|---|---|
| FlashInfer | Normal | 4 | 3 / 3 / 2 | 5 / 8 / 18 / 2 |
| FlashInfer | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| FA3 | Normal | 3 | 3 / 2 / 2 | 4 / 4 / 10 / 1 |
| FA3 | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| Triton | Normal | 3 | 2 / 3 / 1 | 5 / 4 / 13 / 2 |
| Triton | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
*Tested on QWen3-8B. CUDA graph and chunked prefill enabled, radix cache disabled for FlashInfer and Triton (support under development).
CUDA Graph Acceleration
CUDA graphs accelerate inference by merging multiple kernel launches into a single launch. Evaluating total throughput for 16 requests (1024 tokens input/output each), results show at least 2.79x acceleration across all attention kernels.
| Attention Backend | CUDA Graph | Throughput (tokens/s) |
|---|---|---|
| FlashInfer | Disabled | 441.73 |
| FlashInfer | Enabled | 1245.51 (2.82x) |
| FA3 | Disabled | 447.64 |
| FA3 | Enabled | 1247.64 (2.79x) |
| Triton | Disabled | 419.64 |
| Triton | Enabled | 1228.36 (2.93x) |
*Configuration: QWen3-8B, TP1, H100 80GB. All performance benchmarks disable radix cache.
Offline Inference Performance Measurement
Using three common RL rollout workloads (256 requests, varying input/output lengths) to measure end-to-end latency. Deterministic mode overhead ranges from 25%-45%, averaging 34.35% for FlashInfer and FA3. Main overhead comes from unoptimized batch-invariant kernels, with significant optimization potential.
| Attention Backend | Mode | Input 1024 Output 1024 | Input 4096 Output 4096 | Input 8192 Output 8192 |
|---|---|---|---|---|
| FlashInfer | Normal | 30.85 | 332.32 | 1623.87 |
| FlashInfer | Deterministic | 43.99 (+42.6%) | 485.16 (+46.0%) | 2020.13 (+24.4%) |
| FA3 | Normal | 34.70 | 379.85 | 1438.41 |
| FA3 | Deterministic | 44.14 (+27.2%) | 494.56 (+30.2%) | 1952.92 (+35.7%) |
| Triton | Normal | 36.91 | 400.59 | 1586.05 |
| Triton | Deterministic | 57.25 (+55.1%) | 579.43 (+44.64%) | 2296.60 (+44.80%) |
*Configuration: QWen3-8B, TP1, H200 140GB. Radix cache disabled.
While deterministic inference is slower than normal mode, it's recommended for debugging and reproducibility. Future work focuses on acceleration, targeting overhead reduction to below 20% or parity with normal mode.
How to Use
Environment Setup
Install SGLang version ≥0.5.3:
pip install "sglang[all]>=0.5.3"
Starting the Server
SGLang supports deterministic inference for multiple models. For example, Qwen3-8B only requires adding the --enable-deterministic-inference flag:
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-8B \
--attention-backend \
--enable-deterministic-inference
Technical Details
Chunked Prefill
SGLang's chunked prefill technique is used to handle long-context requests, but the default chunking strategy violates the determinism requirements of attention kernels. As shown in the figure, consider two sequences seq_a and seq_b with length 6000, maximum chunk size 8192, and split-KV size 2048 required for deterministic attention. Each sequence can be processed in chunks...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接