We are excited to introduce SGLang-Jax, a state-of-the-art open-source inference engine built entirely on Jax and XLA.
It leverages the high-performance server architecture of SGLang and utilizes Jax to compile model forward passes. By combining SGLang and Jax, this project achieves fast native TPU inference while preserving advanced features such as continuous batching, prefix caching, tensor parallelism, expert parallelism, speculative decoding, kernel fusion, and highly optimized TPU kernels.
Benchmarks show that SGLang-Jax's performance matches or exceeds other TPU inference solutions. The source code is available on GitHub.
Why Choose a Jax Backend?
Although SGLang was originally built on PyTorch, the community has been anticipating Jax support. Our main reasons for developing a Jax backend include:
- Jax has been optimized for TPU from its inception, making it the best choice for achieving extreme performance. As Google expands public access to TPU, the Jax + TPU combination will be widely adopted for cost-effective inference.
- Leading AI labs such as Google DeepMind, xAI, Anthropic, and Apple already rely on Jax. Unifying training and inference frameworks can reduce maintenance costs and avoid two-stage drift.
- Jax + XLA is a mature compilation-driven stack that performs excellently on TPU and is applicable to various TPU-like custom AI chips.
Architecture
The diagram below shows the architecture of SGLang-Jax. The entire stack is implemented in pure Jax, resulting in clean code with minimal dependencies.
On the input side, it supports OpenAI-compatible APIs, leverages SGLang's efficient RadixCache for prefix caching, and employs an overlap scheduler for low-overhead batching. The scheduler pre-compiles Jax computation graphs for different batch sizes. On the model side, implementation is based on Flax, using shard_map to support various parallelism strategies. Core operators—attention and MoE—are implemented as custom Pallas kernels.
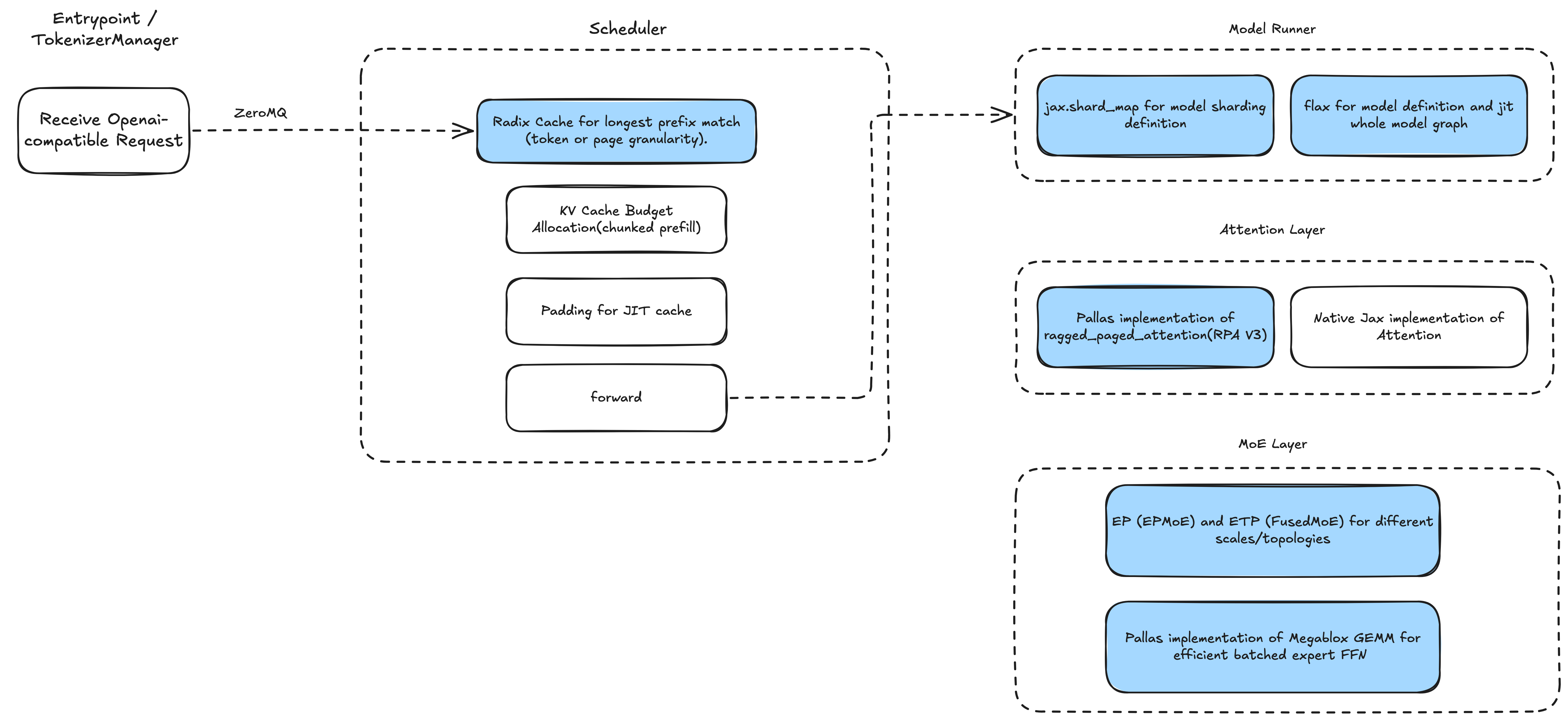
SGLang-Jax Architecture Diagram
Key Optimizations
Integration of Ragged Paged Attention v3
We integrated Ragged Paged Attention v3 (RPA v3) and extended it to support SGLang features:
- Tuned kernel grid block configurations for different scenarios to improve performance.
- Compatible with RadixCache.
- Added custom masking in the verification phase to support EAGLE speculative decoding.
Reduced Scheduling Overhead
Sequential operations between CPU and TPU in forward passes can impact performance. However, operations on different devices can be decoupled; for example, while TPU starts computation, the CPU can immediately prepare the next batch. To improve performance, the scheduler overlaps CPU processing with TPU computation.
In the overlapping event loop, the scheduler pipelines CPU and TPU work using result queues and thread events. While TPU processes batch N, the CPU prepares batch N+1. By profiling and optimizing the operation sequence, for Qwen/Qwen3-32B, gaps between prefill and decode were reduced from ~12ms to 38μs, and from ~7ms to 24μs. Details can be found in our previous blog post.

Profiling diagram with overlap scheduler enabled, showing minimal gaps between batches.
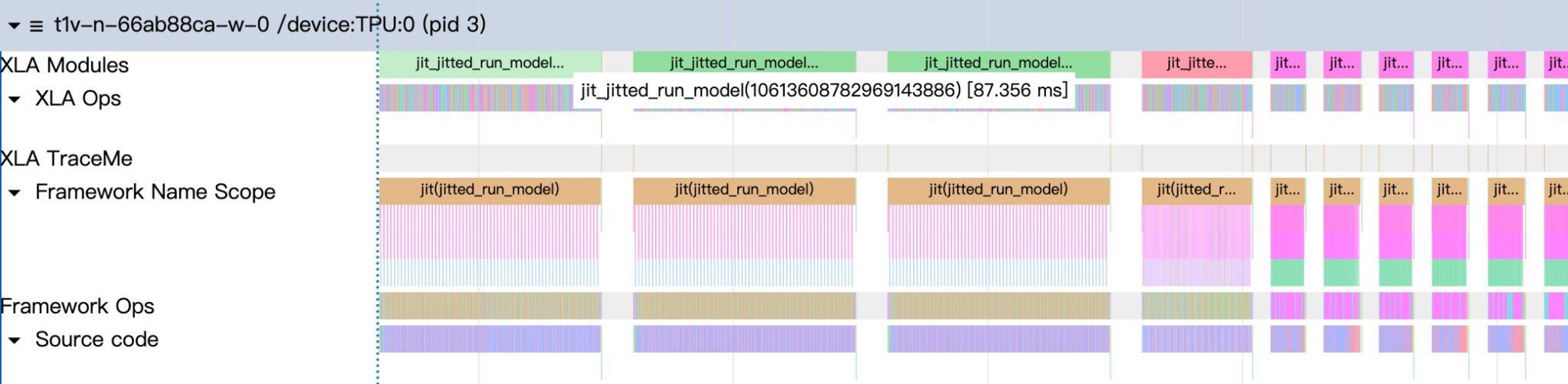
Profiling diagram without overlap scheduler, showing significant CPU overhead gaps between batches.
MoE Kernel Optimization
The MoE layer supports two strategies: EPMoE and FusedMoE. EPMoE integrates the Megablox GMM operator, replacing the previous ragged_dot implementation. Megablox GMM is specifically designed for MoE, efficiently handling variable-length expert groups, avoiding unnecessary computation and non-contiguous memory access, resulting in 3-4x improvement in end-to-end (e2e) ITL speed. Combined with efficient token permutation, ragged_all_to_all expert parallel communication, and adaptive tiling, it significantly improves throughput, especially suitable for multi-expert scenarios across devices. FusedMoE fuses all expert computations using dense einsum operations with no communication overhead, suitable for scenarios where individual experts are large but few in number (<64), and also serves as a lightweight debugging alternative.
Speculative Decoding
SGLang-Jax implements EAGLE-based speculative decoding, namely Multi-Token Prediction (MTP). This technique uses lightweight draft heads to predict multiple tokens and accelerates generation through parallel verification with a single full model pass. To implement tree-like MTP-Verify, we added non-causal masking support to Ragged Paged Attention V3 for parallel decoding in the verification phase. Currently supporting Eagle2 and Eagle3, we will optimize kernels and extend attention backend support in the future.
TPU Performance
After optimization, SGLang-Jax matches or exceeds other TPU inference solutions and is highly competitive compared to GPU solutions. Complete benchmark results and explanations can be found in this GitHub issue.
Usage Guide
Installing SGLang-Jax and Starting the Server
Installation:
# Using uv
uv venv --python 3.12 && source .venv/bin/activate
uv pip install sglang-jax
# From source
git clone https://github.com/sgl-project/sglang-jax
cd sglang-jax
uv venv --python 3.12 && source .venv/bin/activate
uv pip install -e python/Starting the server:
MODEL_NAME="Qwen/Qwen3-8B" # or "Qwen/Qwen3-32B"
jax_COMPILATION_CACHE_DIR=/tmp/jit_cache \
uv run python -u -m sgl_jax.launch_server \
--model-path ${MODEL_NAME} \
--trust-remote-code \
--tp-size=4 \
--device=tpu \
--mem-fraction-static=0.8 \
--chunked-prefill-size=2048 \
--download-dir=/tmp \
--dtype=bfloat16 \
--max-running-requests 256 \
--page-size=128Using TPU via GCP Console
In Menu → Compute Engine, select Create TPU. Note that only specific regions support specific TPU versions, and set the software version to v2-alpha-tpuv6e. In Compute Engine → Settings → Metadata, add your SSH public key. After creation, use the external IP shown in the console and your public key username to log in. See GCP documentation for details.
Using TPU via SkyPilot
We recommend using SkyPilot for daily development. After installing the GCP version of SkyPilot, run the sgl-jax.sky.yaml from the repository:
sky launch sgl-jax.sky.yaml --cluster=sgl-jax-skypilot-v6e-4 --infra=gcp -i 30 --down -y --use-spotThis command automatically selects the lowest-cost TPU spot instance, shuts down after 30 minutes of inactivity, and pre-installs the sglang-jax environment. Once complete, simply ssh cluster_name to log in.
Future Roadmap
The community is working with Google Cloud and partners on the following plans:
- Model Support and Optimization: Optimize Grok2, Ling/Ring, DeepSeek V3, GPT-OSS; support MiMo-Audio, Wan 2.1, Qwen3 VL.
- TPU Optimized Kernels: Quantization kernels, communication-computation overlap kernels, MLA kernels.
- RL Integration with tunix: Weight synchronization, Pathways and multi-host support.
- Advanced Serving Features: Prefill-decode disaggregation, hierarchical KV cache, multi-LoRA batching.
Acknowledgments
SGLang-Jax Team: sii-xinglong, jimoosciuc, Prayer, aolemila, JamesBrianD, zkkython, neo, leos, pathfinder-pf, Jiacheng Yang, Hongzhen Chen, Ying Sheng, Ke Bao, Qinghan Chen
Google: Chris Yang, Shun Wang, Michael Zhang, Xiang Li, Xueqi Liu
InclusionAI: Junping Zhao, Guowei Wang, Yuhong Guo, Zhenxuan Pan
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接