Introduction
Recently, the SGLang RL team has made significant progress in RL training stability, efficiency, and application scenarios, including:
- INT4 QAT End-to-End Training: Achieving a complete QAT INT4 closed-loop solution from training to inference, with detailed technical recipes, significantly improving deployment efficiency and stability.
- Unified Multi-turn VLM/LLM Training: Providing a VLM multi-turn sampling paradigm implementation blog, where developers only need to write custom
rolloutfunctions to easily launch VLM multi-turn RL, just like training LLMs. - Rollout Router Replay: Implementing the Rollout Router Replay mechanism, significantly improving MoE model RL training stability.
- FP8 End-to-End Training: Successfully implementing end-to-end FP8 training and sampling in RL scenarios, further unleashing hardware performance.
- Speculative Decoding in RL: Successfully practicing speculative sampling in RL scenarios, achieving lossless acceleration in large-scale training.
Building on this foundation, we go further: reproducing and deploying an end-to-end INT4 QAT solution on the slime framework: INT4 Quantization-Aware Training (QAT). This solution is deeply inspired by the Kimi team's K2-Thinking technical report and their W4A16 QAT practice: W4A16 QAT. To honor the pioneers and give back to the community, this article dissects the technical details of building a full pipeline in the open-source ecosystem, providing practical references that balance stability and performance.
Key Benefits at a Glance:
- Breaking Memory Bottlenecks: Weight compression and low-bit quantization compress ~1TB-scale K2-like models to a single H200 (141GB) GPU, avoiding cross-node communication bottlenecks.
- Training-Inference Consistency: Training uses QAT to shape weights into INT4-friendly distributions; inference uses W4A16 (INT4 weights, BF16 activations), both relying on BF16 Tensor Cores, achieving training-inference consistency comparable to full BF16 precision.
- Doubling Single-Node Efficiency: For ultra-large models, INT4 significantly reduces memory and bandwidth pressure, with deployment efficiency far exceeding W8A8 (FP8 weights, FP8 activations).
This project was jointly completed by SGLang RL team, InfiXAI team, Ant Group Asystem & AQ Infra team, slime team, and RadixArk team. Related features and recipes have been synchronized to the slime and Miles communities, welcome to try and contribute. We are further challenging MXFP8 and NVFP4, and thank Verda Cloud for their computing power sponsorship.
Technical Overview
Overall Pipeline
We have implemented a complete INT4 QAT closed loop from training to inference, as shown in the following figure:
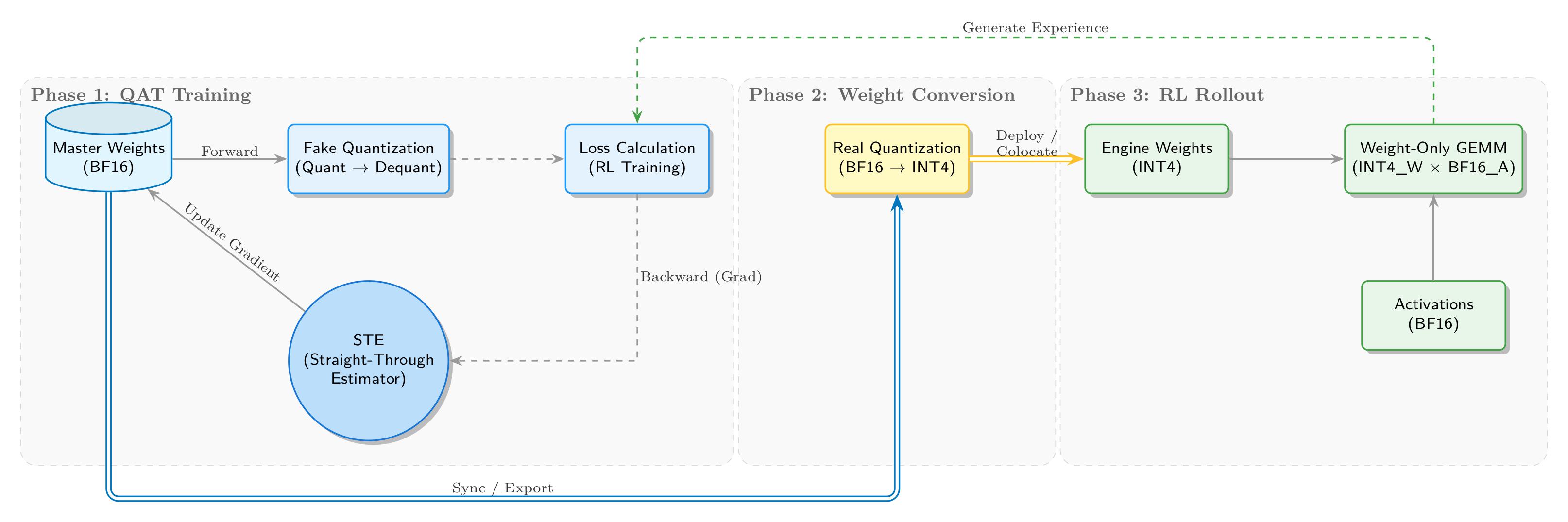
In the QAT training phase, the training side maintains BF16 master weights, with forward propagation introducing quantization noise through fake quantization. "Fake" means not actually converting BF16 tensors to low-precision INT4 storage, but retaining the floating-point computation path and inserting QDQ (Quantize-DeQuantize) operations to simulate low-precision computation. Specifically, high-precision weights are first "discretized" to INT4 and then immediately restored. Although the physical dtype remains floating-point, the value precision is effectively reduced. The difference between the original and restored values introduces quantization error, equivalent to injecting noise into the network, forcing the model to adapt to precision loss through gradient updates.
Backpropagation uses STE (Straight-Through Estimator) to bypass the non-differentiability of quantization. The core quantization operation rounding is a step function with derivatives almost everywhere 0, which would block gradient flow. STE adopts a "straight-through gradient estimator" strategy: during backward pass, the rounding derivative is defined as 1 (treated as an identity mapping), like building a bridge across a cliff, allowing gradients to pass through the rounding layer to update high-precision floating-point weights, closing the QAT training loop.
In the weight conversion phase, converged BF16 weights are exported and undergo real quantization, converting to INT4 format adapted for inference engines (such as Marlin).
In the RL rollout phase, SGLang loads INT4 weights and runs efficient W4A16 inference (INT4 weights × BF16 activations). Generated experience data flows back to the first phase, forming a self-consistent closed loop.
Key Strategy Choices
The quantization format follows Kimi-K2-Thinking, choosing INT4 (W4A16). Compared to FP4, INT4 has broader support on existing hardware (pre-Blackwell), with mature high-performance Marlin kernels in the ecosystem. Experiments show that with 1×32 scale granularity, INT4 has sufficient dynamic range, stable precision, and well-optimized performance and tools. As an industry "good enough" quantization standard, INT4 achieves a rational balance between performance, risk, and maintenance costs. In the future, we plan to explore FP4 RL on NVIDIA Blackwell GPUs.
Training adopts the classic fake quantization + STE combination: maintaining BF16 master weights, simulating quantization noise in forward pass, and directly passing gradients in backward pass, maximizing low-precision training convergence and stability.
Training Side: Fake Quantization Modification of Megatron-LM
Fake Quantization and STE Implementation
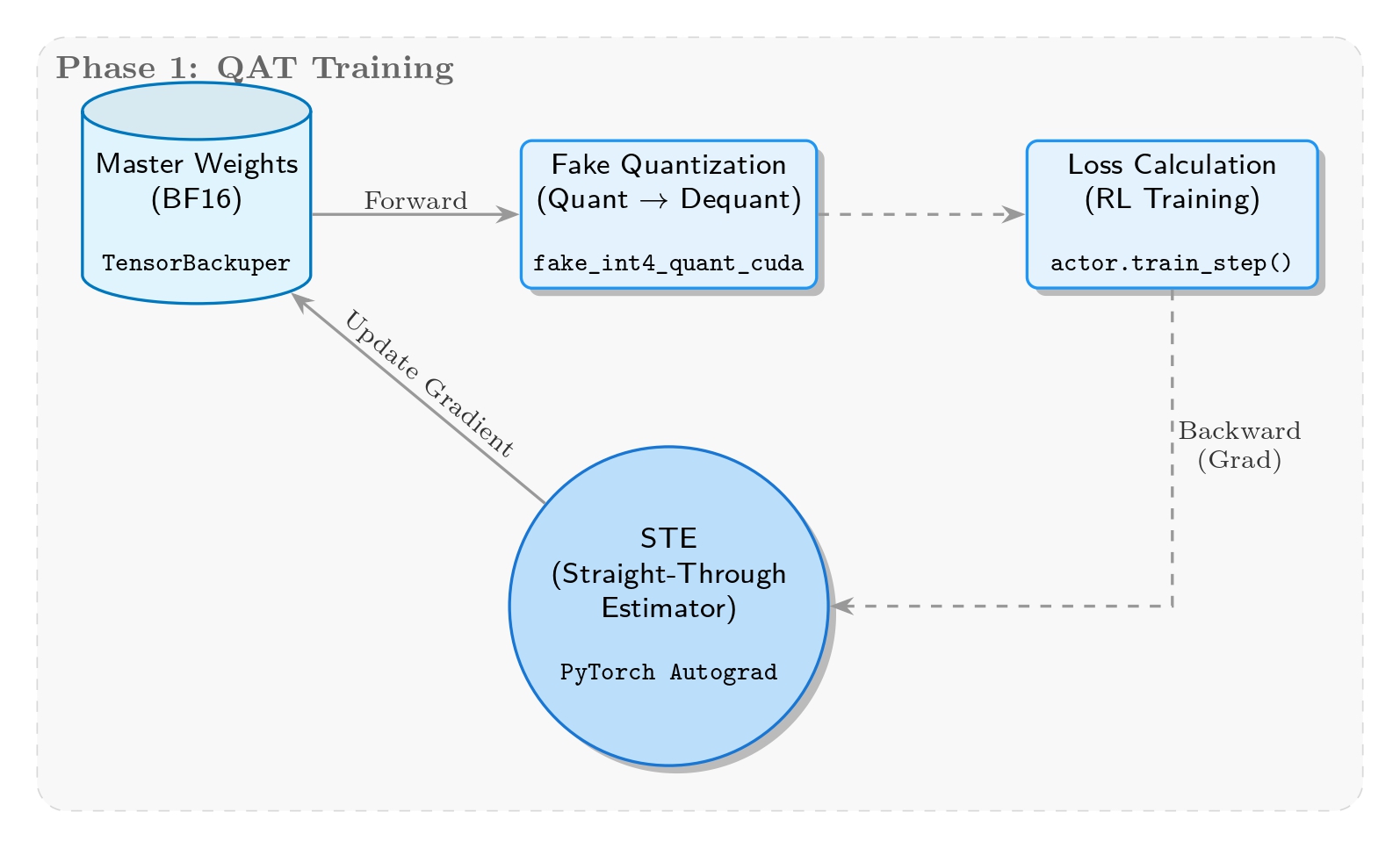
The core goal of this phase is to simulate quantization error in real-time during training, forcing the model to "learn" to adapt to low-precision representation. Therefore, we adopt fake quantization: weights are stored and updated in BF16, temporarily mapped to INT4 precision range in forward pass.
In implementation, the core logic is located in the _FakeInt4QuantizationSTE class in megatron/core/extensions/transformer_engine.py. Based on per-group max abs value dynamic quantization, it simulates INT4's [-7, 7] range and clipping, but still computes in BF16, only injecting quantization error. Key backpropagation introduces STE, ensuring gradients pass through the quantization layer unchanged to update master weights, maintaining training continuity.
Fake Quantization Ablation Experiments
To verify the necessity of QAT and study the impact of training-inference precision mismatch, we designed two asymmetric scenario ablations:
- QAT INT4 training enabled, BF16 rollout
- QAT training disabled, direct INT4 rollout
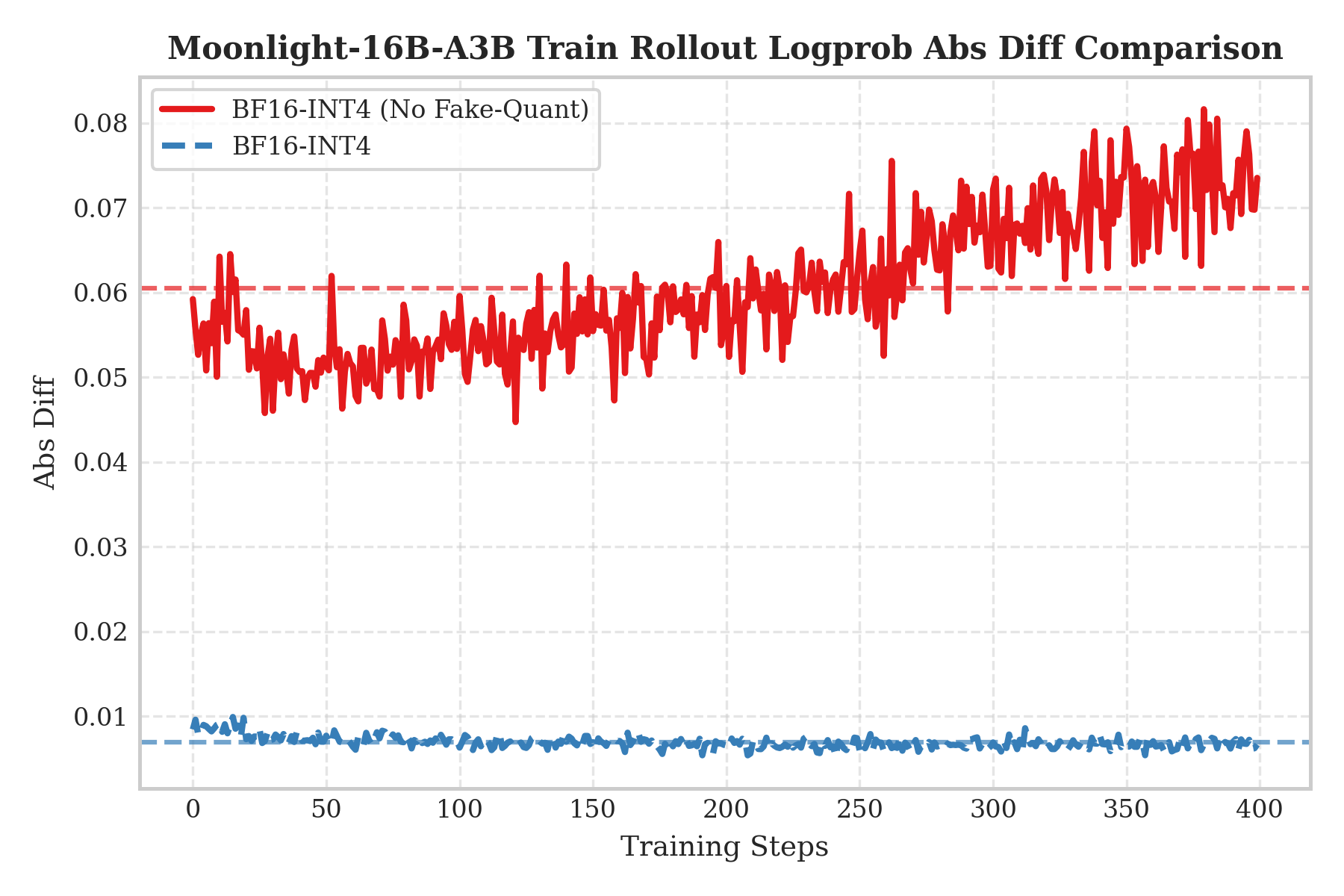
We use log probabilities absolute difference (Logprob Abs Diff) to measure training-inference inconsistency.
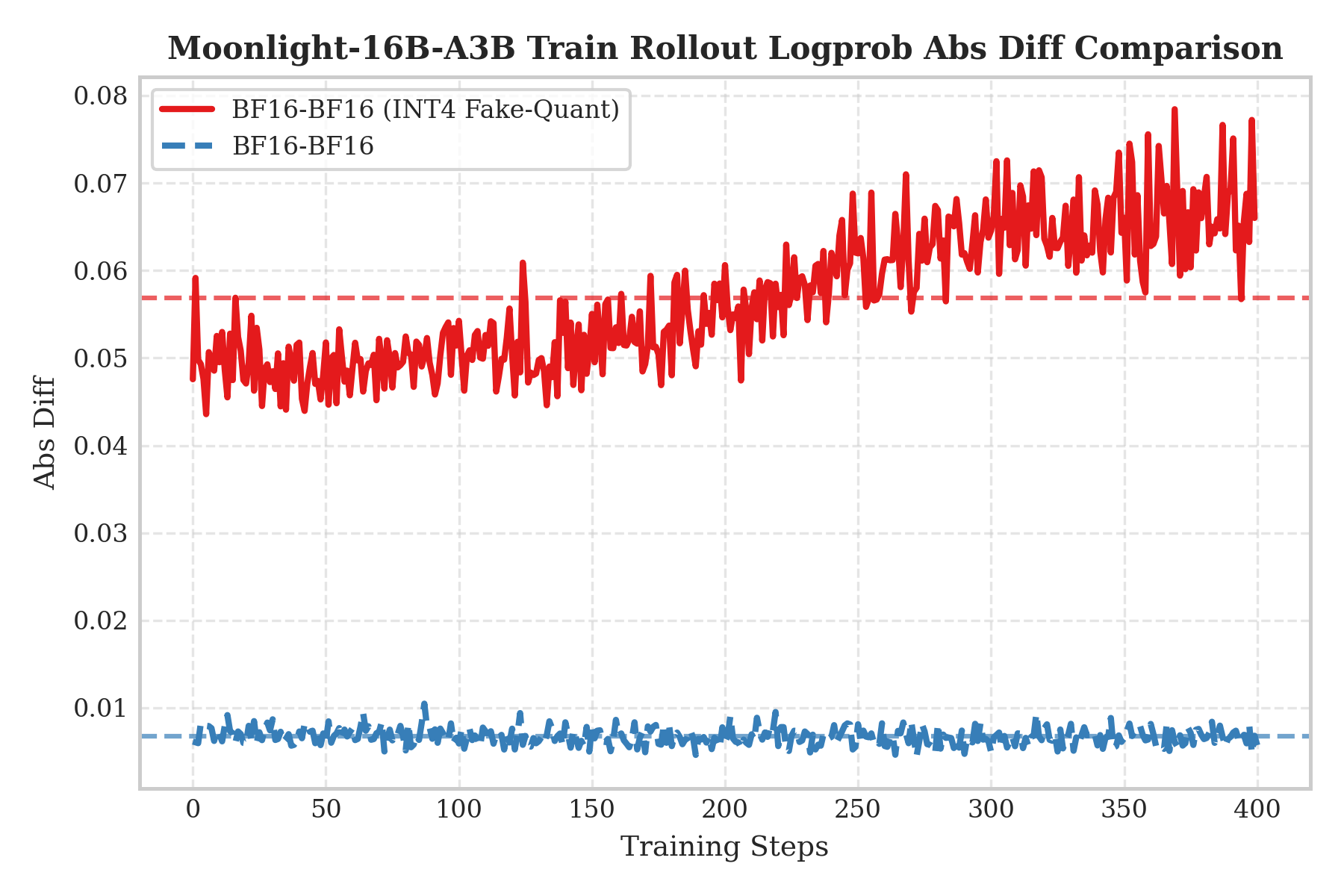
Left figure shows "QAT INT4 training + BF16 rollout" (red curve). Interestingly, even with high-precision BF16 inference, the error is still significantly higher. Because QAT has adapted to INT4 quantization noise through "compensation", if quantization is removed during inference, this compensation becomes disturbance, causing distribution shift.
Right figure shows "No QAT training + direct INT4 rollout" (red curve), corresponding to a typical post-training quantization (PTQ) scenario, with results showing significant training-inference inconsistency, verifying the necessity of QAT.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接