概述
我们兴奋地宣布 SGLang 与 AutoRound 正式合作,支持低比特量化以实现高效 LLM 推理。通过这一集成,开发者可以使用 AutoRound 的符号梯度优化技术对大模型进行量化,并直接在 SGLang 的高效运行时中部署,实现低比特模型推理,同时最小化准确率损失并显著降低延迟。
AutoRound 是什么?
AutoRound 是一款先进的后训练量化(PTQ)工具包,专为大语言模型(LLMs)和视觉语言模型(VLMs)设计。它利用符号梯度下降联合优化权重舍入和裁剪范围,实现 INT2 到 INT8 等低比特量化,在多数场景下准确率损失极小。例如,在 INT2 精度下,其相对准确率比流行基线高出高达 2.1 倍;在 INT4 精度下也保持领先优势。下图展示了 AutoRound 核心算法概览。
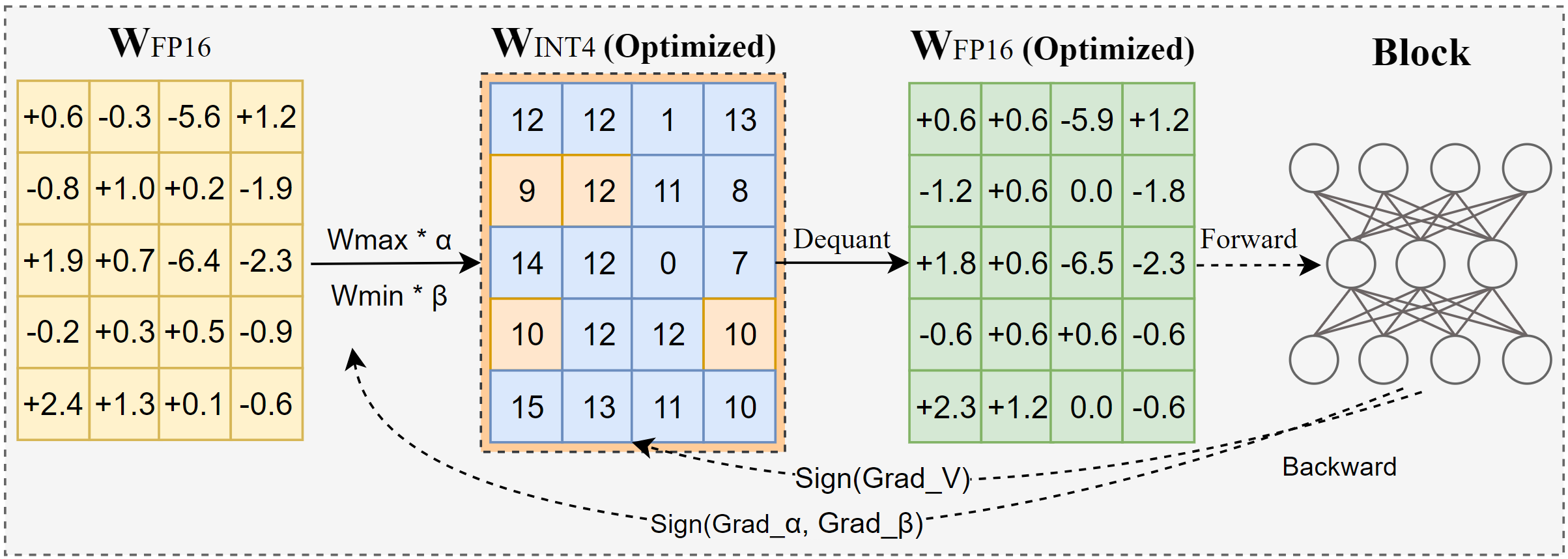
AutoRound 算法概述
完整技术细节见 AutoRound 论文:Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs。
尽管性能强劲,AutoRound 仍保持高效轻量——在轻量模式下,单 GPU 量化 72B 模型仅需 37 分钟。它还支持混合比特调优、lm-head 量化,以及 GPTQ/AWQ/GGUF 格式导出和自定义调优配方。
AutoRound 亮点
AutoRound 不仅注重算法创新,还以完整的量化工程能力广受认可。
- 准确率:低比特精度下提供卓越准确率
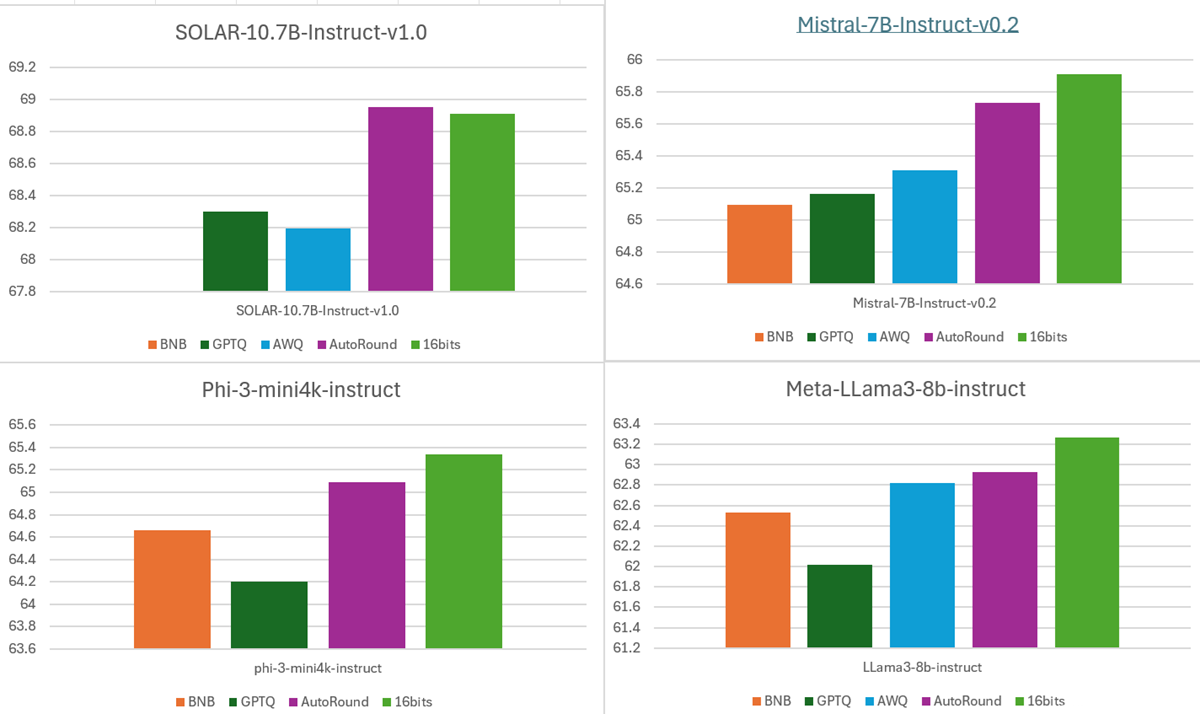
INT4 权重下 10+ 任务平均准确率
- 量化方案:支持仅权重量化、权重与激活量化,以及激活量化的动态/静态模式
- 混合比特:数分钟内生成混合比特/其他数据类型方案的有效算法
- 广泛兼容性:
- 支持几乎所有流行 LLM 架构及 10+ VLMs
- 设备:CPU、Intel GPU、CUDA
- 数据类型:INT2-INT8、MXFP4、NVFP4、FP8、MXFP8
- 效率:块状调优降低 VRAM 使用率,同时保持高吞吐量且速度快

量化时间成本对比
- 社区采用:无缝集成 SGLang、TorchAO、Transformers 和 vLLM;HuggingFace 模型库(如 Intel、OPEA、Kaitchup、fbaldassarri)下载量约 200 万
- 导出格式:AutoRound、GPTQ、AWQ、GGUF、Compressed-tensor(初步支持)
集成概述
SGLang 提供新一代推理运行时,支持可扩展、低延迟 LLM 部署。其多模态、多 GPU 和流式执行模型适用于聊天和代理推理任务,效率卓越。
SGLang 的灵活架构现提供原生量化模型加载钩子,释放 AutoRound 在部署中的全部潜力。
1. 使用 AutoRound 量化
AutoRound 自动优化权重舍入,并导出与 SGLang 兼容的量化权重。
1.1 API 使用
# for LLM
from auto_round import AutoRound
model_id = "meta-llama/Llama-3.2-1B-Instruct"
quant_path = "Llama-3.2-1B-Instruct-autoround-4bit"
# Scheme examples: "W2A16", "W3A16", "W4A16", "W8A16", "NVFP4", "MXFP4" (no real kernels), "GGUF:Q4_K_M", etc.
scheme = "W4A16"
format = "auto_round"
autoround = AutoRound(model_id, scheme=scheme)
autoround.quantize_and_save(quant_path, format=format) # quantize and save1.2 CMD 使用
auto-round \
--model Qwen/Qwen2-VL-2B-Instruct \
--bits 4 \
--group_size 128 \
--format "auto_round" \
--output_dir ./tmp_autoround2. 使用 SGLang 部署
SGLang(版本 >= v0.5.4.post2)直接支持 AutoRound 量化模型,兼容常见 LLM、VLM 和 MoE 模型,并支持混合比特量化模型的推理与评估。
2.1 OpenAI 兼容推理
from sglang.test.doc_patch import launch_server_cmd
from sglang.utils import wait_for_server, print_highlight, terminate_process
# 等同于终端命令:
# python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound --host 0.0.0.0
server_process, port = launch_server_cmd(
"""
python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound \
--host 0.0.0.0 --log-level warning
"""
)
wait_for_server(f"http://localhost:{port}")2.2 离线引擎 API 推理
import sglang as sgl
llm = sgl.Engine(model_path="Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound")
prompts = ["Hello, my name is"]
sampling_params = {"temperature": 0.6, "top_p": 0.95}
outputs = llm.generate(prompts, sampling_params)
for prompt, output in zip(prompts, outputs):
print(f"Prompt: {prompt}\nGenerated text: {output['text']}")更多灵活配置和部署选项待您探索!
量化路线图
AutoRound 量化基准结果显示,低精度下准确率保持强劲。下表突出其在 MXFP4、NVFP4 和混合比特量化中的优势。准确率基于 lambada_openai、hellaswag、piqa、winogrande 和 mmlu 任务平均值。
未来路线图包括提升常见模型的 MXFP4 & NVFP4 准确率,以及自动混合比特量化。
- MXFP4 & NVFP4 量化(RTN 为基线,'alg_ext' 表示实验优化算法)
| MXFP4 | llama3.1-8B-Instruct | Qwen2-7.5-Instruct | Phi4 | Qwen3-32B |
|---|---|---|---|---|
| RTN | 0.6212 | 0.6550 | 0.7167 | 0.6901 |
| AutoRound | 0.6686 | 0.6758 | 0.7247 | 0.7211 |
| AutoRound+alg_ext | 0.6732 | 0.6809 | 0.7225 | 0.7201 |
| NVFP4 | llama3.1-8B-Instruct | Qwen2-7.5-Instruct | Phi4 | Qwen3-32B |
|---|---|---|---|---|
| RTN | 0.6876 | 0.6906 | 0.7296 | 0.7164 |
| AutoRound | 0.6918 | 0.6973 | 0.7306 | 0.7306 |
| AutoRound+alg_ext | 0.6965 | 0.6989 | 0.7318 | 0.7295 |
- 自动 MXFP4 & MXFP8 混合比特量化
| 平均比特 | Llama3.1-8B-I | Qwen2.5-7B-I | Qwen3-8B | Qwen3-32B |
|---|---|---|---|---|
| BF16 | 0.7076 (100%) | 0.7075 (100%) | 0.6764 (100%) | 0.7321 (100%) |
| 4-bit | 0.6626 (93.6%) | 0.6550 (92.6%) | 0.6316 (93.4%) | 0.6901 (94.3%) |
| 4.5-bit | 0.6808 (96.2%) | 0.6776 (95.8%) | 0.6550 (96.8%) | 0.7176 (98.0%) |
| 5-bit | 0.6857 (96.9%) | 0.6823 (96.4%) | 0.6594 (97.5%) | 0.7201 (98.3%) |
| 6-bit | 0.6975 (98.6%) | 0.6970 (98.5%) | 0.6716 (99.3%) | 0.7303 (99.8%) |
结论
AutoRound 与 SGLang 的集成标志着高效 AI 模型部署的重要里程碑。这一合作桥接了精度优化与运行时可扩展性,让开发者从量化到实时推理无缝过渡。AutoRound 的符号梯度量化即使在极端压缩比下也能保持高保真,而 SGLang 的高吞吐推理引擎则在 CPU、GPU 和多节点集群中释放低比特执行潜力。
展望未来,我们将扩展高级量化格式支持、优化内核效率,并将 AutoRound 量化引入更广泛的多模态和代理任务。AutoRound 与 SGLang 共同树立了智能、高效、可扩展 LLM 部署的新标准。