GB200 NVL72是深度学习领域最强大的硬件之一。本文延续上篇博客,分享SGLang团队对DeepSeek V3/R1推理性能的优化进展,采用FP8 attention、NVFP4 MoE、大规模专家并行(EP)、预填充-解码分离等多种技术。在FP8 attention和NVFP4 MoE下,对于2000 token输入序列,SGLang实现每NVIDIA Blackwell GPU预填充26,156 input tokens/s、解码13,386 output tokens/s,较H100配置提升3.8倍和4.8倍。即使使用传统BF16 attention和FP8 MoE,也达到18,471 input tokens/s和9,087 output tokens/s。复现指南见此处。
亮点
- SGLang在DeepSeek V3/R1上实现每NVIDIA Blackwell GPU预填充26,156 input tokens/s、解码13,386 output tokens/s(2000 token输入),较H100提升3.8倍和4.8倍。
- 传统精度(BF16 attention + FP8 MoE)下,仍达18,471 input tokens/s和9,087 output tokens/s。
- FP8 attention和NVFP4 GEMM较原精度提升最高1.8倍和1.9倍。
- FP8 attention和NVFP4 GEMM精度损失可忽略不计。
优化方法
以下策略得到应用:
- FP8 Attention:除传统BF16外,现支持attention中KV cache的FP8精度。这减少解码内存访问压力,支持更快Tensor Core指令,提升解码attention内核速度。同时,增加KV cache token数量,支持更长序列和更大batch size,进一步提高系统效率。
- NVFP4 GEMM:相较经典FP8 GEMM,NVFP4不仅降低GEMM内存带宽压力,还利用更强的FP4 Tensor Core。同时,token分发通信流量减半,权重内存占用减少,便于扩展KV cache空间。除MoE专家外,attention输出投影GEMM也可选量化至NVFP4。与NVIDIA官方checkpoint不同,我们进一步将q_b_proj用FP8执行以提升性能。
- 通过卸载缩减规模:支持缩小EP规模。当设备内存不足时,利用GB200 CPU-GPU间高速带宽(900GB/s,双向)将权重卸载至主机内存并预取。这降低通信开销,在计算放缓被通信收益抵消时提升性能。最优规模取决于计算/通信内核和模型配置。同时,减少单预填充实例GPU使用,缩小故障影响,并减少等待最慢rank的时间。
- 计算通信重叠:针对更高通信带宽,放弃以往两batch重叠,采用细粒度重叠。将combine通信与down GEMM及共享专家重叠。在GEMM信号中使用带release语义的atomic指令(TMA store commit后多步),并采用cp.async.bulk.wait_group PTX指令。
内核级集成/优化包括:
- NVIDIA Blackwell DeepGEMM(预填充attention):统一内核,支持高性能预填充和解码,已集成至预填充路径。
- FlashInfer Blackwell CuTe DSL GEMM(NVFP4解码):用CuTe DSL实现带mask布局的NVFP4 GEMM,利用TMA和tcgen05.mma指令(含2CTA MMA),结合持久tile调度和warp specialization。
- FlashInfer Blackwell CUTLASS GEMM(NVFP4预填充):支持多数据类型CUTLASS实现,优化类似CuTe版,适合高吞吐预填充。
- Flash Attention CuTe(BF16 KV-cache预填充):CuTe DSL框架,实现预填充MHA高性能。
- FlashInfer Blackwell TensorRT-LLM Attention(解码和FP8 KV-cache预填充):基于cluster launch control的持久调度器,高效隐藏prologue/epilogue,支持BF16/FP8。
- DeepEP中融合NVFP4:DeepEP可选量化token分发,融合NVFP4量化,网络流量减半。
- 更小内核优化:量化/拼接等内核融合优化;FlashInfer MLA RoPE量化内核优化;FlashInfer中TensorRT-LLM内核原型优化,端到端加速5%、单内核最高2.5倍。
实验
端到端性能
在GB200 NVL72上评估DeepSeek在SGLang的端到端性能,遵循大规模EP和GB200第一部分实验设置。评估原精度(BF16 attention + FP8 MoE)和低精度(FP8 attention + NVFP4 MoE/输出投影GEMM)。解码用48 ranks(大规模EP);预填充高精度4 ranks/实例,低精度2 ranks。使用CuTe DSL早期访问版。
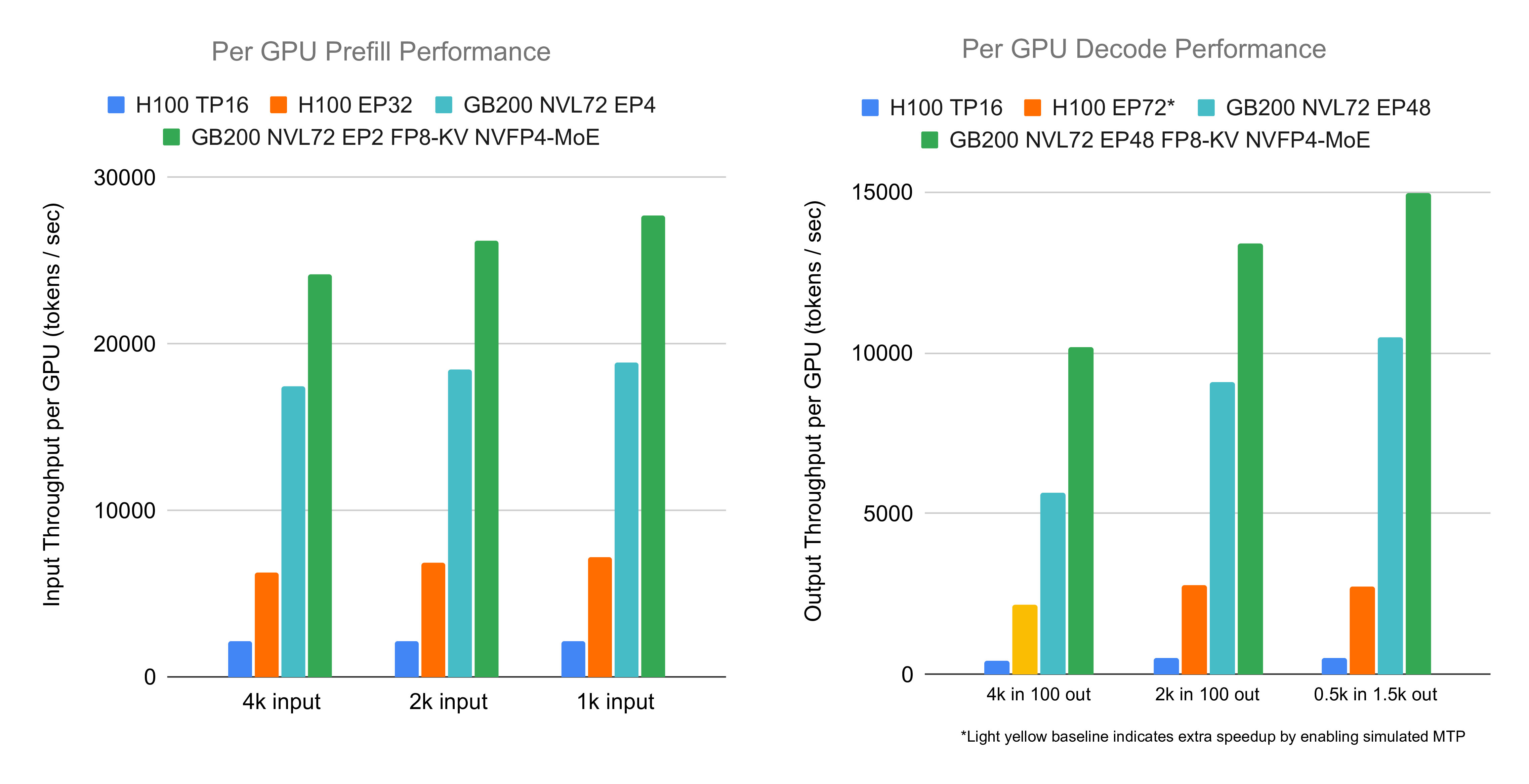
实验显示GB200较H100预填充加速3.8倍、解码4.8倍。主要因素包括:
- 低精度:FP8替换BF16 attention、NVFP4替换FP8 GEMM,减少计算/内存访问,支持更大batch。
- 更快内核:集成高性能attention/GEMM内核,占端到端时间大比例。
- 各种优化:重叠、卸载、小内核加速/融合等,乘性贡献。
- 先前因素:上篇博客因素适用于新预填充优化。
备注:高/低精度路径差异不止精度变化,还涉及辅助内核/策略及EP平衡性(batch size使KV cache满载,如4k ISL用768、2k用1408;减小batch如2k从1408至768,性能降约10%)。
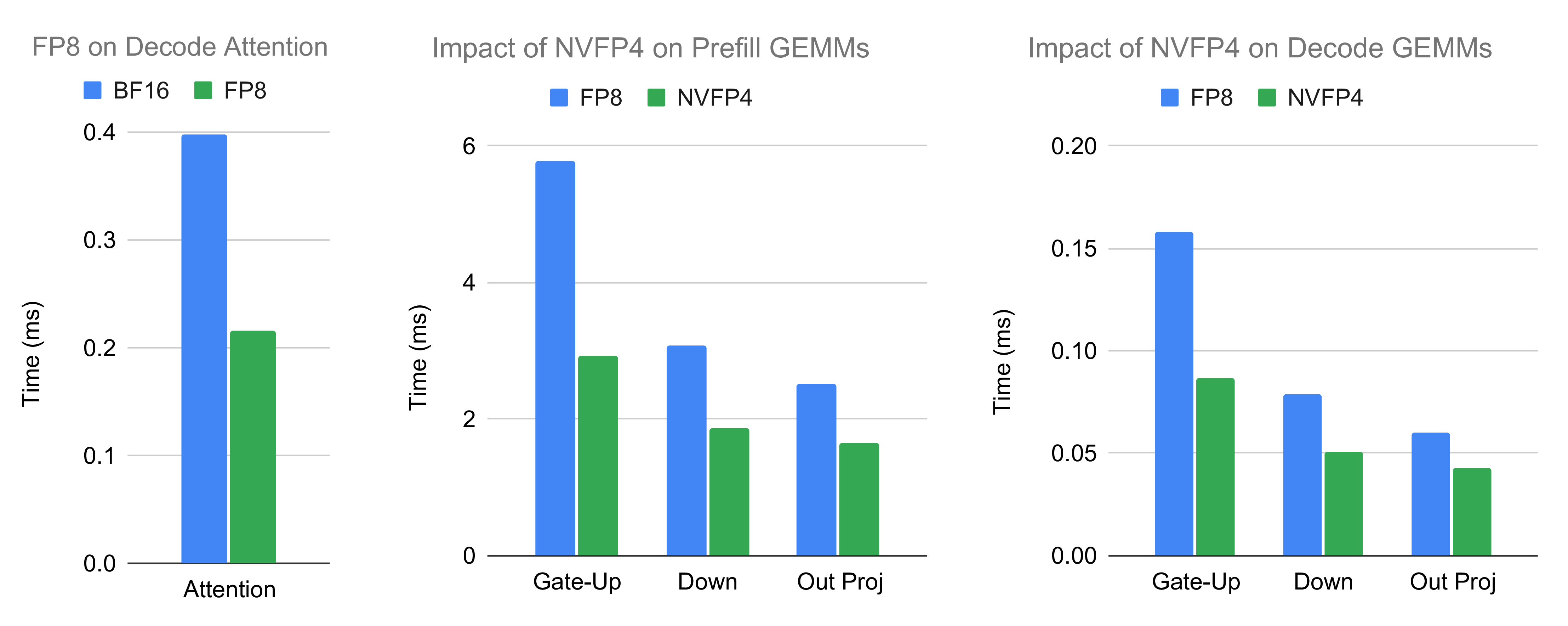
低精度内核放大分析
考察从标准精度至低精度内核的影响,针对attention、MoE gate-up/down GEMM及attention输出投影GEMM。典型案例下,低精度显著加速:attention 1.8倍、GEMM最高1.9倍。此外,KV cache token增加支持更大batch,提升性能。
精度
后训练量化...