引言
SGLang社区此前已证明EPD解耦对VLM服务的必要性与优势,尤其在多图像输入场景下可大幅降低TTFT。本文进一步观察到视觉编码是图像密集场景的主要瓶颈,因此提出将部分视觉编码工作卸载到头节点CPU。
视觉编码器(CNN/ViT)通常小于语言模型部分,配备AMX等矩阵加速器的现代CPU足以胜任;同时视觉编码仅发生在prefill阶段,便于插入异构worker,无需复杂跨worker状态管理。
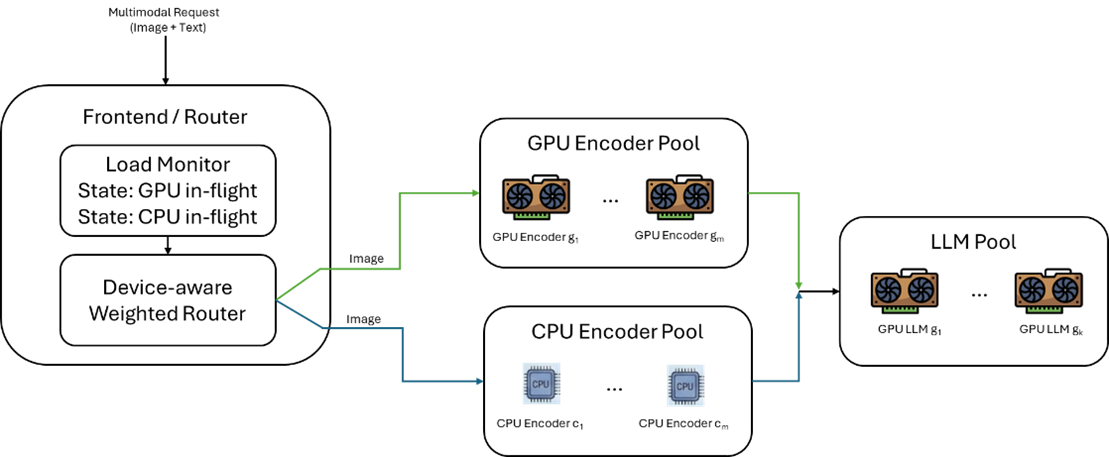
设备感知加权路由器
通过与Dynamo社区合作,团队将设备感知加权路由模式合并至动态路由器,支持异构分发。该路由器引入GPU与CPU之间的预算节流机制,使用能力比率R定义GPU相对CPU的吞吐量,并计算CPU允许的在飞预算B_cpu。
公式为:B_cpu = I_gpu * N_cpu / (R * N_gpu)。当CPU实例在飞请求数低于该预算时路由至CPU,否则路由至GPU。
实验设置
环境采用Intel Xeon 6747P CPU(4 NUMA节点)与5张L40S GPU,模型为Qwen3-VL-8B-Instruct。数据集包含128/256输入输出长度、1080p分辨率、8张图像,QPS范围1.0-2.0。部署对比1E/4PD纯GPU方案与(4 CPU + 1 GPU)E/4PD异构方案,能力比率R设为12。
基准测试结果
使用sglang.bench_serving脚本进行测试,重点关注P99 TTFT、P99 TPOT与请求吞吐量。
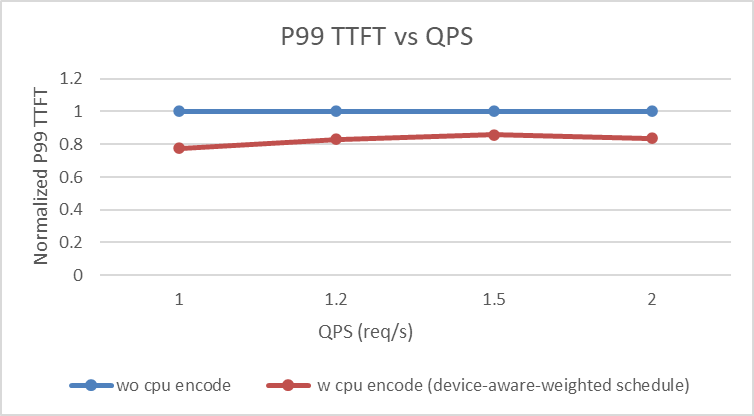
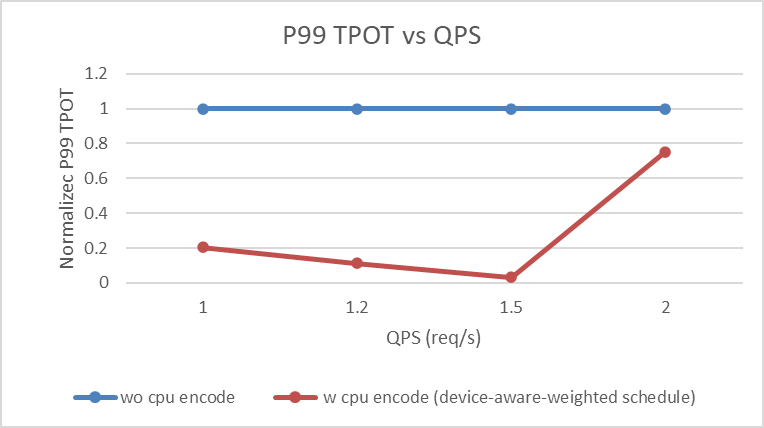
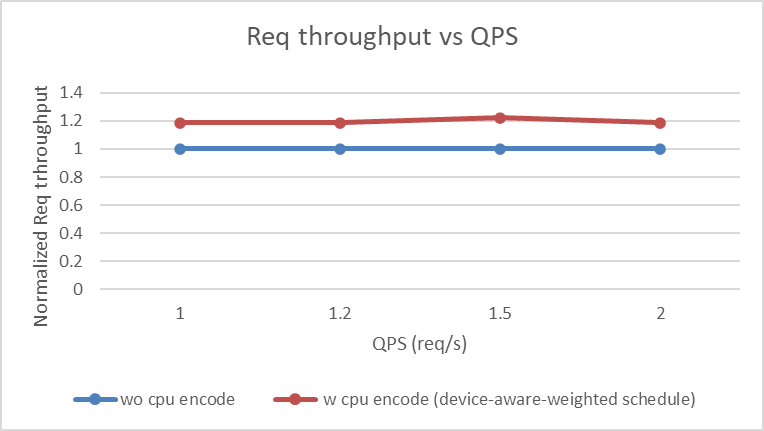
关键发现:
- 异构CPU+GPU EPD解耦在所有指标上均优于纯GPU方案。
- P99 TTFT与吞吐量提升约1.2-1.3倍,表明CPU有效分担GPU视觉编码负担。
- P99 TPOT降低1.3-30倍,缓解了视觉编码流量导致的生成队列延迟。
该方案在纯GPU EPD解耦带来的ROI基础上,几乎零成本地实现更高投资回报率。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接