千里之行,始于足下。
今天,我们发布了Miles,一个专为大规模MoE训练和生产工作负载设计的企业级强化学习框架。
Miles基于slime构建,后者是轻量级RL框架,已悄然驱动当今众多后训练管道和大模型MoE训练(如GLM-4.6)。slime验证了轻量设计的有效性,而Miles则迈出下一步:提供真实企业部署所需的可靠性、规模化和控制力。
GitHub: radixark/miles。
为什么选择Miles?
每一段进步都源于精准的一步——slime便是如此。作为高度轻量且可定制的RL框架,slime在社区中迅速流行,并在GLM-4.6的大规模MoE训练中经受实战检验。slime遵循几项优雅设计原则:
开箱即用的性能
提供对SGLang和Megatron完整优化栈的原生结构化支持,跟上推理与训练框架的快速发展。
模块化设计
核心组件——Algorithm、Data、Rollout和Eval——完全解耦。只需少量代码修改,即可接入新代理类型、奖励函数或采样策略。
专为研究者打造
每个抽象层都易读易改。算法研究者无需深挖底层代码,即可调整重要性采样、rollout逻辑或损失动态。我们还提供纯推理和纯训练调试模式,便于快速诊断。
社区驱动
slime源于LMSYS和SGLang社区的实战反馈,体现了研究与工程开放协作的成果。
新功能亮点
Miles在slime基础上,针对新硬件(如GB300)、大规模MoE RL和生产级稳定性进行了优化。近期新增功能(多数已上游回馈slime)包括:
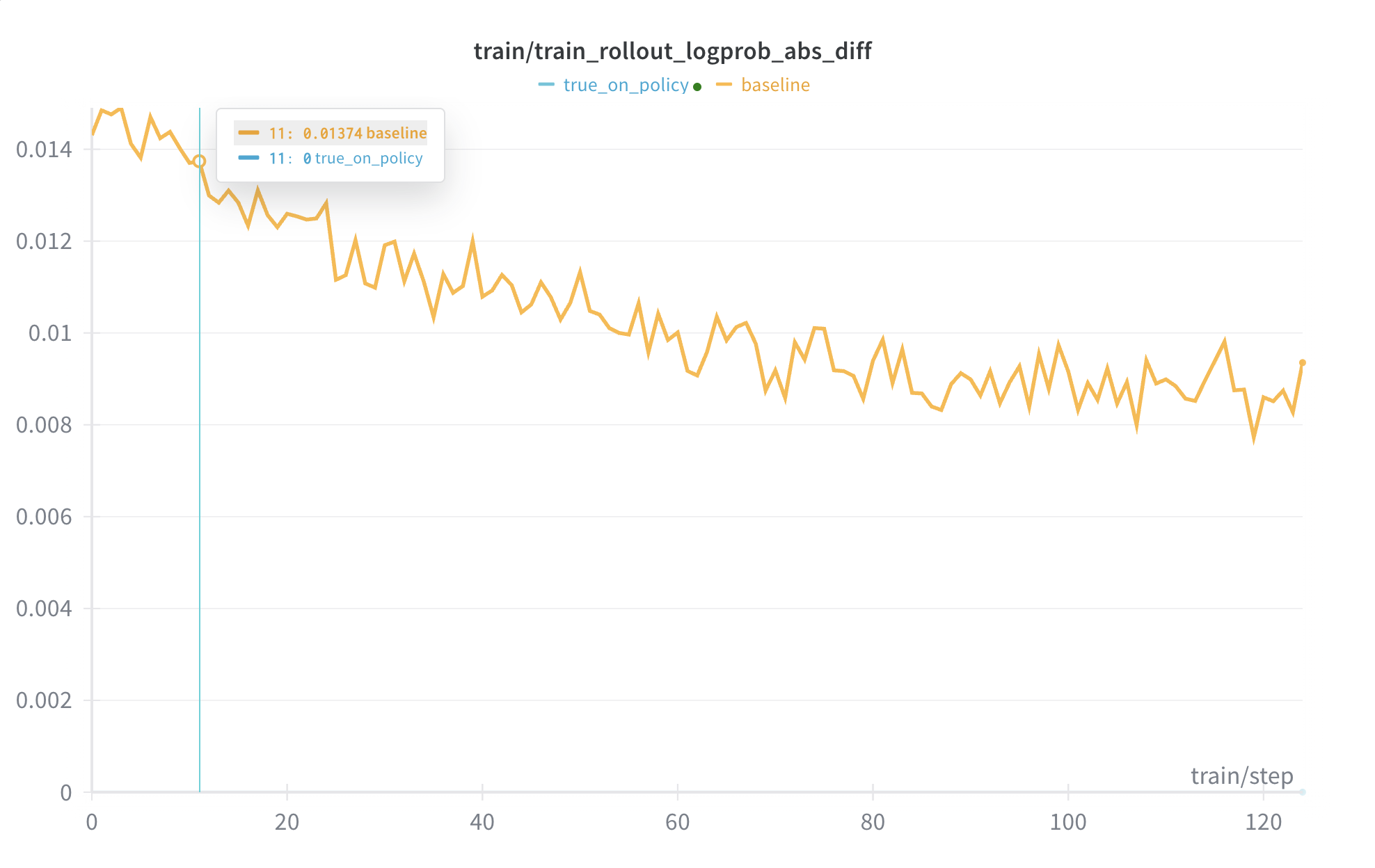
真On-Policy支持
超越确定性推理(逐位相同结果),现通过基础设施实现true on-policy:true_on_policy示例。
- 消除训练与推理间的差异,使KL散度精确为0。
- 采用Flash Attention 3、DeepGEMM、Thinking Machines Lab的batch invariant kernels,以及
torch.compile,并对齐训练与推理的数值运算。
内存优化
为最大化性能并避免OOM错误,我们进行了多项改进:
- 添加错误传播,避免良性OOM崩溃。
- 实现内存裕度,修复NCCL相关OOM。
- 修复FSDP过度内存使用。
- 支持基于move的和部分卸载,以及主机峰值内存节省。
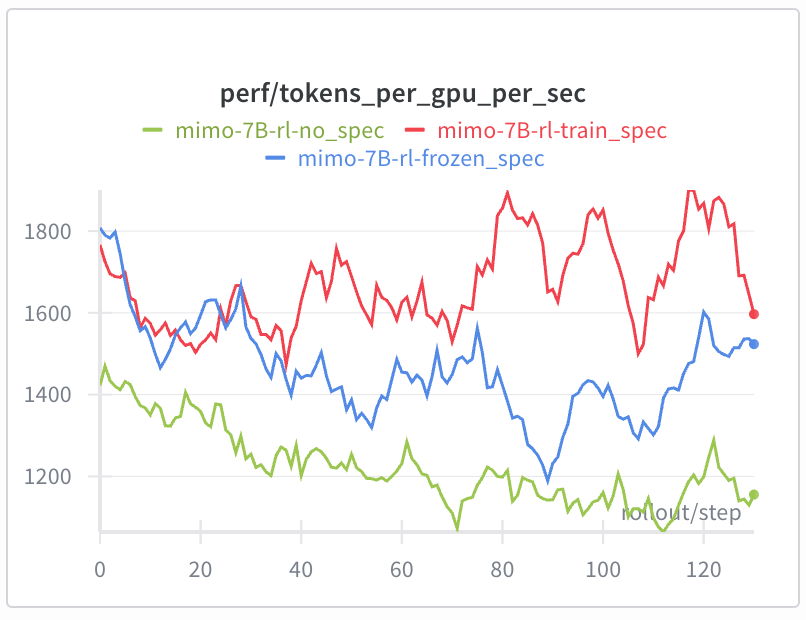
带在线草稿模型训练的投机解码
RL中冻结草稿模型会使其偏离目标模型策略,降低接受长度和加速比。现全程进行在线SFT训练草稿模型:spec文档。
- 相较冻结MTP,实现25%+ rollout加速,尤其在训练后期。
- 支持MTP序列打包+CP、损失掩码边缘案例处理、LM head/embedding梯度隔离,以及Megatron↔SGLang权重同步。
其他改进
我们增强了FSDP训练后端,支持独立部署rollout子系统,并添加更多调试工具(指标、事后分析器、更好profiling)。还包含Lean形式数学示例,附带SFT/RL脚本。
未来路线图
我们致力于企业级RL训练支持。即将推进:
- 新硬件(如GB300)的大规模MoE RL示例。
- 多模态训练支持。
- Rollout加速:兼容SGLang spec v2、高级投机解码(如EAGLE3、多spec层)。
- 大规模异步训练中训练与服务的平衡资源分配。
- 对GPU故障的弹性支持。
致谢
Miles离不开slime作者及更广泛的SGLang RL社区。我们邀请研究者、初创企业和团队探索slime与Miles——选择适合你的——共同打造高效可靠的强化学习。社区反馈是我们前进动力,我们正积极迭代Miles,构建生产就绪的训练环境。