本文介绍我们在SGLang中支持全新服务范式PD-Multiplexing的初步成果。该范式旨在为LLM服务带来更高的goodput。它充分利用GreenContext——NVIDIA GPU的一项新技术,支持同一进程内GPU资源的轻量级细粒度分区,实现跨任务的高效资源共享。我们认为,这将是Model-as-a-Service (MaaS)部署的有力新路径,能提供更强的SLO保障和更高的goodput。
LLM服务中的Goodput挑战:持久难题
大规模MaaS部署要求LLM服务系统在不牺牲吞吐量的前提下,持续满足严格的Service Level Objectives (SLO)。实践中,这意味着需同时保障推理两个阶段的延迟SLO:prefill阶段的Time-to-First-Token (TTFT),以及decode阶段的Inter-Token Latency (ITL,也称Time-Between-Tokens, TBT)。难点在于prefill和decode在同一服务实例上交替执行,导致GPU资源争用。目前常见方案包括:
- 实例级PD分离:将prefill和decode置于不同实例。但这需静态分区GPU资源,且KV cache跨实例迁移引入复杂性,需要高性能互连和通信库。
- 序列级chunked-prefill:将长序列拆分成小块,并与decode迭代融合以控制ITL。但需权衡chunk大小:过小影响ITL保障,过大降低GPU利用率。
尤其针对实际LLM服务的紧SLO阈值,这两种方法的局限性愈发明显。
PD-Multiplexing:高效服务新范式
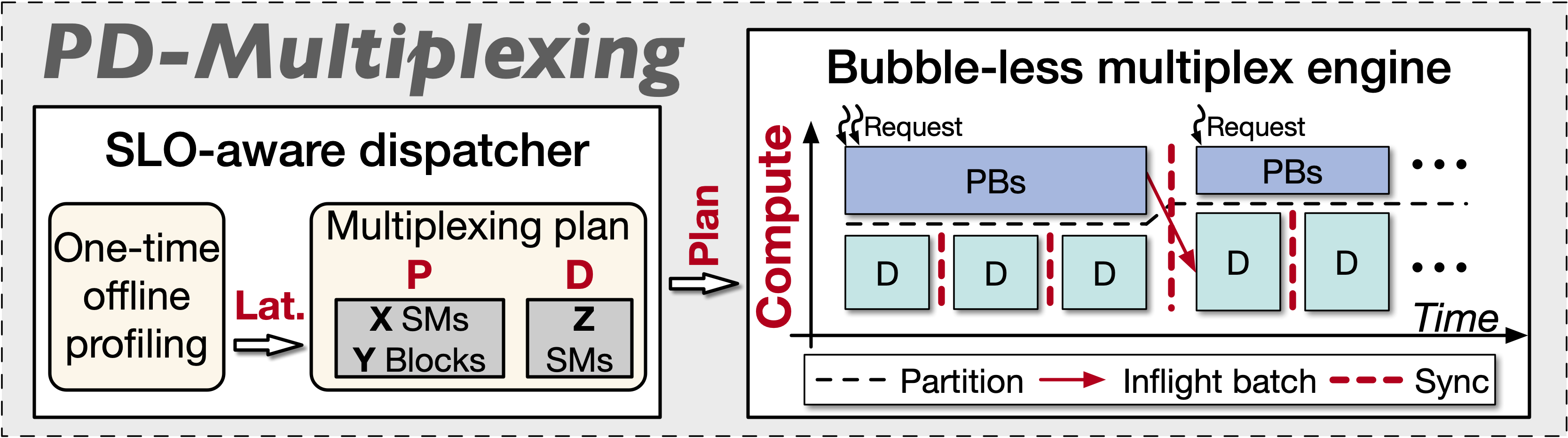
为此,我们提出PD-Multiplexing新范式,通过同一实例内intra-GPU空间共享,实现prefill和decode的复用。主要优势包括:
- prefill和decode共享同一实例的KV cache池,免除昂贵的跨实例迁移。
- GPU计算资源(SMs)可动态流动,随负载变化在prefill和decode间分配。
- 解耦执行,确保满足严格ITL SLO时prefill性能不受影响。
如图1所示,该范式核心包括无bubble的复用引擎(独立高效执行prefill/decode)和SLO感知调度器(迭代生成合规复用计划)。
借助GreenContext实现无Bubble复用引擎
我们基于GreenContext(CUDA 12.4起引入,12.6支持多CUDA流专用SM分配)构建该范式,实现intra-process空间共享。GPU资源可实时动态分区,适应SLO、工作负载等需求。
为保持现有架构,我们采用单线程调度复用prefill/decode(避开Python GIL限制),利用异步特性切换专用GreenContext流。
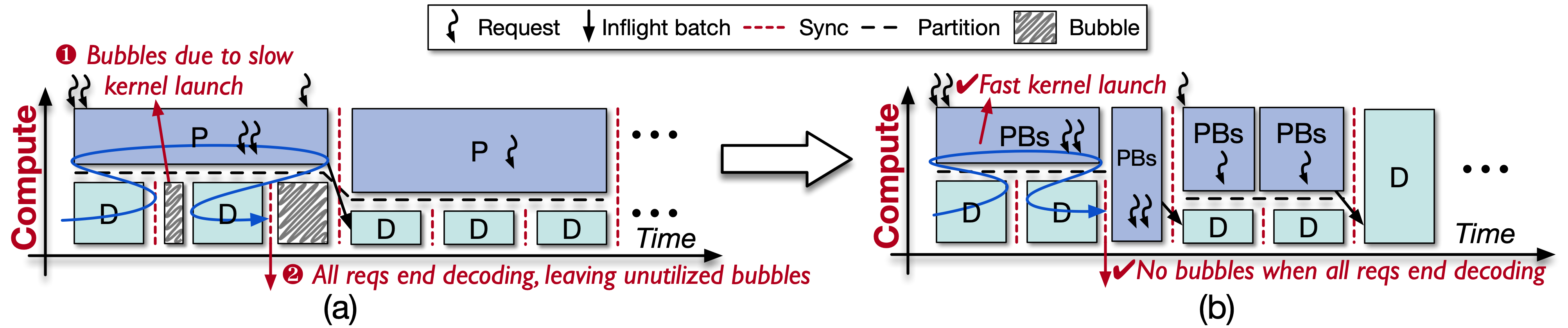
然而,直接集成GreenContext会产生GPU bubble(如图2(a)):(1) prefill启动时间远长于decode(单CUDA graph);(2) decode迭代不确定,早结束导致SM闲置。为此,我们将prefill拆分成小块(如图2(b)),因prefill计算密集,此开销微乎其微,有效消除bubble。
性能剖析与调度策略设计
配备无bubble引擎后,下一步是调度prefill块和decode批次。离线剖析显示,两阶段在GreenContext下争用资源(SM分区但内存带宽共享)。我们通过离线剖析代表负载,训练延迟预测器驱动SLO感知调度(细节依模型/硬件而定,未来提供教程)。
调度直觉:为decode分配刚好满足ITL SLO的SMs,其余全给prefill,同时决定prefill块数。如此,decode严格合规,prefill最大化推进以扩decode批次。
基准测试
我们对比多种基线,在多负载/设备上评估PD-Multiplexing。先展示易复现实验,再用真实trace展示优势,最后可视化调度细节。全面评估中,PD-Multiplexing goodput最高提升3.06x。
* 以下结果用于研究。在实际应用中,SLO更具体,此处展示PD-Multiplexing潜力。与不同Chunk Size的Chunked-prefill对比
在单H200运行CodeLlama-34b-hf,对比不同chunk size的chunked-prefill。图3报告P99 TTFT和ITL,ITL SLO目标60ms(TTFT无约束,仅报告P99)。实心点表示满足ITL SLO,空心表示违规。
PD-Multiplexing提供最快TTFT,同时稳定满足严格ITL SLO。chunked-prefill需chunk size降至1024以下才合规,但损害prefill性能和GPU利用率,尤其长上下文如LooGLE更明显。复现详见此处。
真实负载结果
用真实trace Mooncake-Tool&Agent评估,对比chunked-prefill(chunk=512)和PD-disaggregation(P:D=1:1,均基于SGLang),在8xA100s上,Llama3.1-70B,启用prefix cache共享。
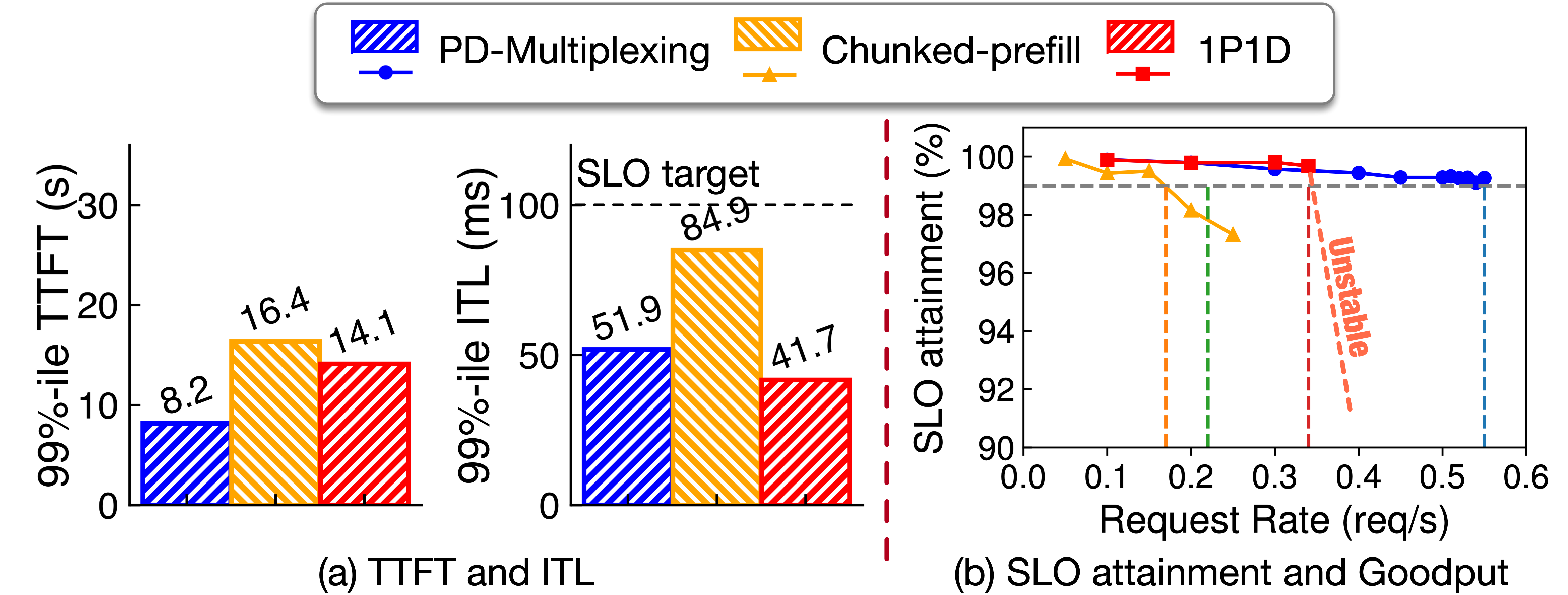
图4(a)显示TTFT和ITL:PD-Multiplexing优于chunked-prefill;较PD-disaggregation,TTFT更短,两者均满足decode SLO。为评估goodput,我们渐增请求率并测SLO达成率。如图5所示,PD-Multiplexing...