我们兴奋地推出SGLang-Jax,一款最先进的开源推理引擎,完全基于Jax和XLA构建。
它借鉴SGLang的高性能服务器架构,并利用Jax编译模型前向传播。通过结合SGLang和Jax,该项目实现了快速原生TPU推理,同时保留连续批处理(continuous batching)、前缀缓存(prefix caching)、张量并行(tensor parallelism)、专家并行(expert parallelism)、推测解码(speculative decoding)、内核融合(kernel fusion)以及高度优化的TPU内核等高级特性。
基准测试表明,SGLang-Jax的性能匹敌或超越其他TPU推理解决方案。源代码可在GitHub获取。
为什么选择Jax后端?
尽管SGLang最初基于PyTorch构建,但社区一直期待Jax支持。我们开发Jax后端的主要原因包括:
- Jax从设计之初就针对TPU优化,是追求极致性能的不二之选。随着Google扩大TPU公共访问,Jax + TPU组合将获得广泛采用,实现成本高效推理。
- 领先AI实验室如Google DeepMind、xAI、Anthropic和Apple已依赖Jax。统一训练和推理框架可降低维护成本,避免两阶段漂移。
- Jax + XLA是成熟的编译驱动栈,在TPU上表现出色,并适用于多种类似TPU的自定义AI芯片。
架构
下图展示了SGLang-Jax的架构,整个栈纯Jax实现,代码简洁、依赖最小。
输入端支持OpenAI兼容API,利用SGLang高效的RadixCache实现前缀缓存,并采用重叠调度器(overlap scheduler)实现低开销批处理。调度器针对不同批大小预编译Jax计算图。模型端基于Flax实现,使用shard_map支持多种并行策略。核心算子——注意力(attention)和MoE——以自定义Pallas内核实现。
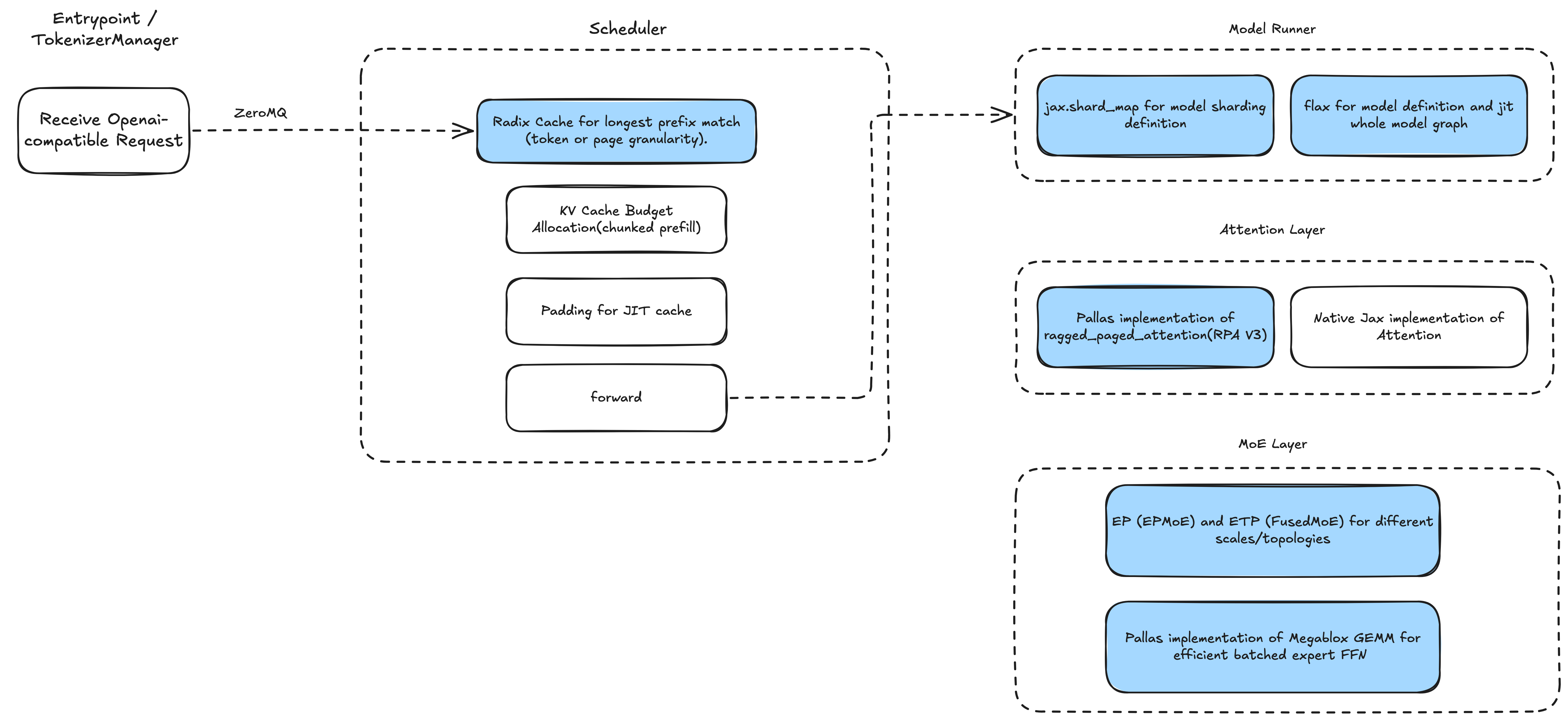
SGLang-Jax架构图
关键优化
集成Ragged Paged Attention v3
我们集成了Ragged Paged Attention v3(RPA v3),并扩展支持SGLang特性:
- 根据不同场景调优内核网格块配置,提升性能。
- 兼容RadixCache。
- 为支持EAGLE推测解码,在验证阶段添加自定义掩码。
降低调度开销
前向传播中CPU和TPU的顺序操作会影响性能。但不同设备操作可解耦,例如TPU启动计算的同时,CPU立即准备下一批次。为提升性能,调度器将CPU处理与TPU计算重叠。
在重叠事件循环中,调度器使用结果队列和线程事件管道化CPU与TPU工作。TPU处理批次N时,CPU准备批次N+1。通过剖析结果优化操作序列,对于Qwen/Qwen3-32B,前填充与解码间隙从约12ms降至38μs,从约7ms降至24μs。详情见前文博客。

启用重叠调度器的剖析图,批次间隙极小。
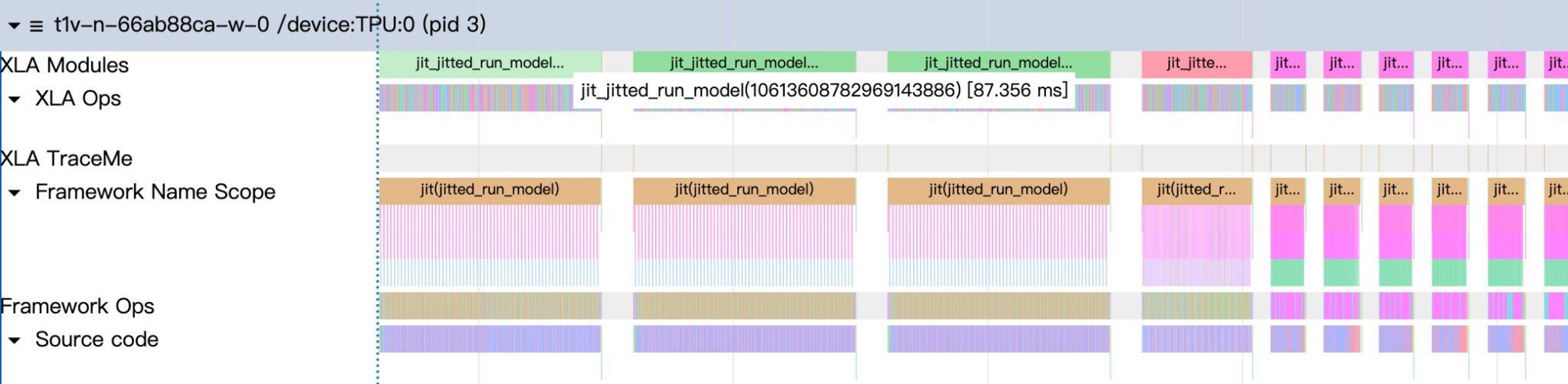
未启用重叠调度器的剖析图,批次间存在明显CPU开销间隙。
MoE内核优化
MoE层支持两种策略:EPMoE和FusedMoE。EPMoE集成Megablox GMM算子,取代之前的ragged_dot实现。Megablox GMM专为MoE设计,高效处理变长专家组,避免不必要计算和非连续内存访问,端到端(e2e)ITL速度提升3–4倍。结合高效令牌置换、ragged_all_to_all专家并行通信及自适应平铺,显著提升吞吐,尤其适合跨设备多专家场景。FusedMoE则融合所有专家计算,使用密集einsum操作,无通信开销,适用于专家个体大但总数少(<64)的场景,也作为轻量调试备选。
推测解码
SGLang-Jax实现基于EAGLE的推测解码,即多令牌预测(Multi-Token Prediction, MTP)。该技术用轻量草稿头预测多令牌,并用单次全模型通过并行验证加速生成。为实现树状MTP-Verify,在Ragged Paged Attention V3上添加非因果掩码支持验证阶段并行解码。目前支持Eagle2和Eagle3,未来将优化内核并扩展注意力后端支持。
TPU性能
经优化后,SGLang-Jax匹敌或超越其他TPU推理方案,与GPU方案相比也极具竞争力。完整基准结果及说明见GitHub issue。
使用指南
安装SGLang-Jax并启动服务器
安装:
# 使用uv
uv venv --python 3.12 && source .venv/bin/activate
uv pip install sglang-jax
# 从源码
git clone https://github.com/sgl-project/sglang-jax
cd sglang-jax
uv venv --python 3.12 && source .venv/bin/activate
uv pip install -e python/启动服务器:
MODEL_NAME="Qwen/Qwen3-8B" # 或 "Qwen/Qwen3-32B"
jax_COMPILATION_CACHE_DIR=/tmp/jit_cache \
uv run python -u -m sgl_jax.launch_server \
--model-path ${MODEL_NAME} \
--trust-remote-code \
--tp-size=4 \
--device=tpu \
--mem-fraction-static=0.8 \
--chunked-prefill-size=2048 \
--download-dir=/tmp \
--dtype=bfloat16 \
--max-running-requests 256 \
--page-size=128通过GCP控制台使用TPU
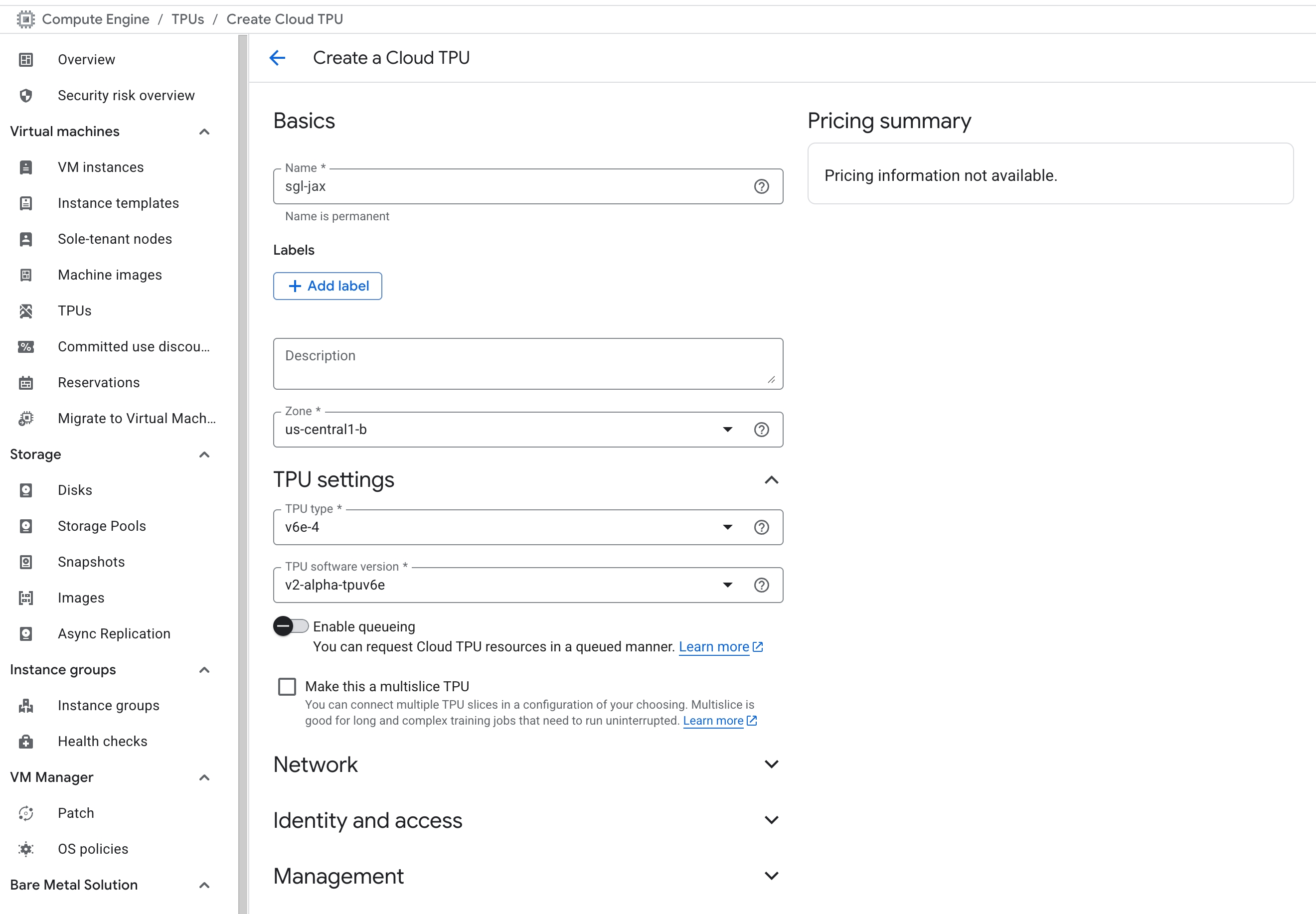
在菜单→Compute Engine中选择创建TPU。注意仅特定区域支持特定TPU版本,并设置软件版本为v2-alpha-tpuv6e。在Compute Engine→Settings→Metadata中添加SSH公钥。创建后,使用控制台显示的外部IP和公钥用户名登录。详见GCP文档。
通过SkyPilot使用TPU
推荐日常开发使用SkyPilot。安装GCP版SkyPilot后,运行仓库中的sgl-jax.sky.yaml:
sky launch sgl-jax.sky.yaml --cluster=sgl-jax-skypilot-v6e-4 --infra=gcp -i 30 --down -y --use-spot该命令自动选择最低成本TPUspot实例,闲置30分钟后关闭,并预装sglang-jax环境。完成后直接ssh cluster_name登录。
未来路线图
社区正与Google Cloud及合作伙伴推进以下计划:
- 模型支持与优化:优化Grok2、Ling/Ring、DeepSeek V3、GPT-OSS;支持MiMo-Audio、Wan 2.1、Qwen3 VL。
- TPU优化内核:量化内核、通信计算重叠内核、MLA内核。
- RL集成与tunix:权重同步、Pathways及多主机支持。
- 高级服务特性:前填充-解码分离、分层KV缓存、多LoRA批处理。
致谢
SGLang-Jax团队:sii-xinglong, jimoosciuc, Prayer, aolemila, JamesBrianD, zkkython, neo, leos, pathfinder-pf, Jiacheng Yang, Hongzhen Chen, Ying Sheng, Ke Bao, Qinghan Chen
Google:Chris Yang, Shun Wang, Michael Zhang, Xiang Li, Xueqi Liu
InclusionAI:Junping Zhao, Guowei Wang, Yuhong Guo, Zhenxuan Pan