我们激动地宣布,SGLang 已实现对 DeepSeek-V3.2 的 Day 0 支持!根据 DeepSeek 的技术报告,DeepSeek-V3.2 通过持续训练为 DeepSeek-V3.1-Terminus 配备了DeepSeek Sparse Attention (DSA),这是一种由 Lightning Indexer 驱动的细粒度稀疏注意力机制,在训练和推理效率上取得显著提升,尤其在长上下文场景中。有兴趣了解即将推出的更多功能?请查看我们的路线图。
安装与快速启动
快速上手,只需拉取容器并按以下方式启动 SGLang:
NVIDIA GPU
docker pull lmsysorg/sglang:v0.5.3-cu129
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --enable-dp-attentionAMD (MI350X/MI355X)
docker pull lmsysorg/sglang:dsv32-rocm
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "aiter"
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "tilelang"
NPU
# NPU A2
docker pull lmsysorg/sglang:dsv32-a2
# NPU A3
docker pull lmsysorg/sglang:dsv32-a3
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --trust-remote-code --attention-backend ascend --mem-fraction-static 0.85 --chunked-prefill-size 32768 --disable-radix-cache --tp-size 16 --quantization w8a8_int8详细说明
DeepSeek Sparse Attention:解锁长上下文效率
DeepSeek-V3.2 的核心是 DeepSeek Sparse Attention (DSA),一种重新定义长上下文效率的细粒度稀疏注意力机制。
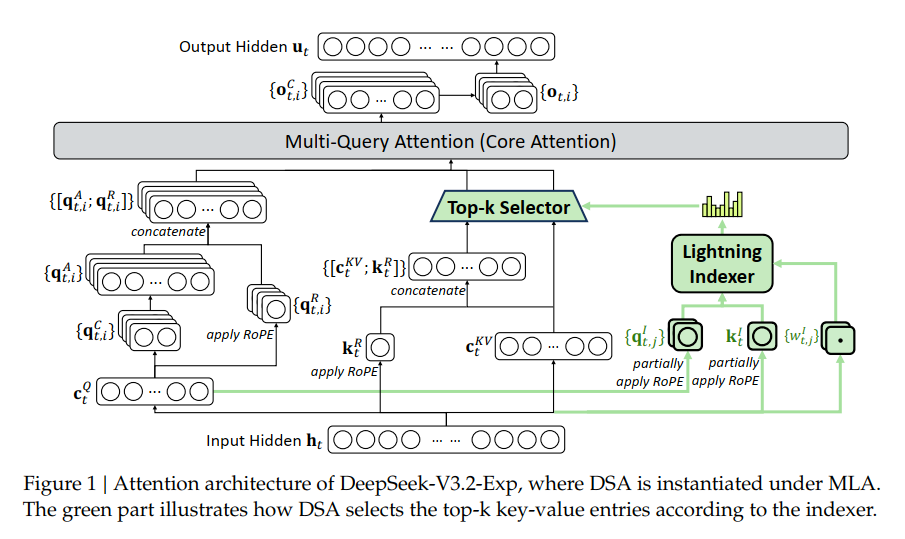
DSA 摒弃了对所有 token 的二次方全注意力计算,转而引入:
- Lightning Indexer(超轻量 FP8 评分器),用于为每个查询识别最具相关性的 token。
- Top-k Token Selection,仅针对最具影响力的 key-value 条目进行计算。
这种设计将核心注意力的复杂度从 O(L2) 降至 O(Lk),在高达 128K 上下文长度下,实现训练和推理的显著效率提升,同时模型质量几乎无损。
为支持这一突破,SGLang 实现了并集成了:
- Lightning Indexer 支持 – 在内存池中专用
key&key_scale缓存,实现超快 token 评分。 - Native Sparse Attention (NSA) 后端 – 专为稀疏负载设计的新后端,包括:
- FlashMLA(DeepSeek 优化的多查询注意力内核)
- FlashAttention-3 Sparse(适配兼容性并最大化内核复用)
- 额外优化:支持同一注意力后端内的不同页面大小:
- Indexer
key&key_scale缓存需页面大小 = 64(来自 DeepSeek 提供的内核) - Token 级稀疏前向运算符需页面大小 = 1
- Indexer
这些创新使 DeepSeek-V3.2-Exp 实现 GPU 优化的稀疏注意力 和 动态缓存管理,大幅降低内存开销,并无缝扩展至 128K 上下文。最终结果是保留最先进推理质量的同时,大幅降低推理成本 — 使长上下文 LLM 部署不仅可行,还具大规模实用性。
未来工作
未来工作将在此处跟踪。具体计划包括:
- Multi-token Prediction (MTP) 支持即将推出:MTP 将加速解码,尤其在批次大小不大时。
- FP8 KV Cache:相较传统 BF16 KV 缓存,可几乎翻倍 KV 缓存中的 token 数量,并 halved 注意力内核的内存访问压力,从而更快服务更长上下文或更多请求。
- TileLang 支持:TileLang 内核有助于灵活开发。
致谢
我们衷心感谢 DeepSeek 团队在开源模型研究方面的杰出贡献,这极大地惠及开源社区,以及他们高效内核的集成至 SGLang 推理引擎。
感谢 SGLang 社区成员 Tom Chen、Ziyi Xu、Liangsheng Yin、Biao He、Baizhou Zhang、Henry Xiao、Hubert Lu、Wun-guo Huang、Zhengda Qin 和 Fan Yin 对 DeepSeek-V3.2-Exp 支持的贡献。
同时感谢 NVIDIA、AMD 和 Nebius Cloud 赞助用于本工作开发的 GPU 机器。