TL;DR:本文分享SGLang实现确定性推理的努力,以及与slime合作推动可重现RL训练的进展。
近日,Thinking Machines Lab发布了一篇博客,详述其研究发现。此后,业界反响热烈,期待开源推理引擎实现稳定、实用的确定性推理,甚至进一步实现完全可重现的RL训练。如今,SGLang与slime联手提供了解决方案。
基于Thinking Machines Lab的batch-invariant算子,SGLang实现了完全确定性推理,同时保持与chunked prefill、CUDA graphs、radix cache和non-greedy sampling的兼容性。启用CUDA graphs后,SGLang带来2.8x加速,性能开销降至34.35%(对比TML的61.5%)。
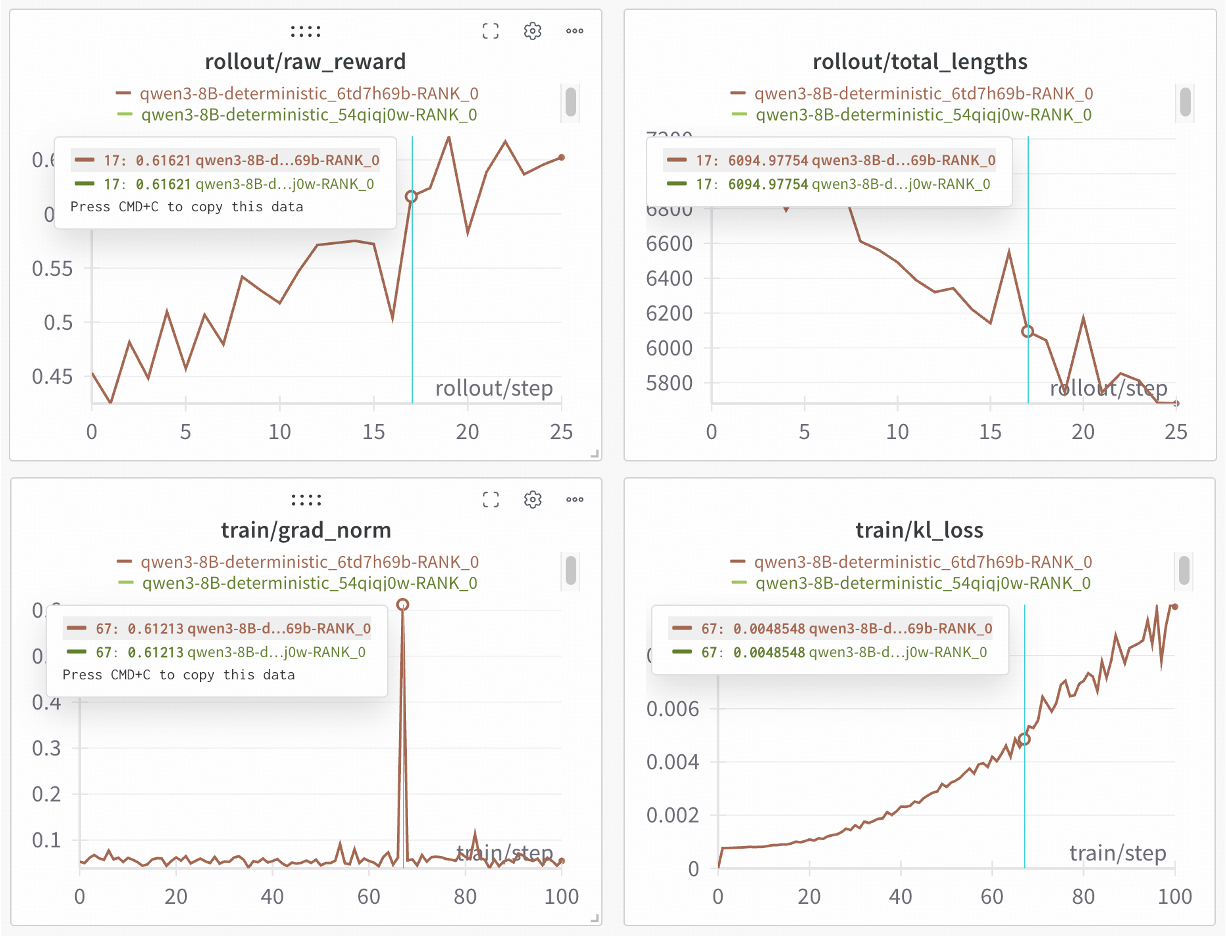
在此基础上,SGLang与slime团队合作,进一步解锁100%可重现RL训练——仅需少量代码修改即可实现。在Qwen3-8B上的验证实验显示,两轮独立训练产生完全相同的曲线,为严谨的科学实验提供可靠保障。
为什么确定性推理如此重要
大型语言模型(LLMs)推理的一致性输出能力日益重要。例如,推理结果的不确定性可能将on-policy强化学习(RL)隐式转化为off-policy RL(如研究者指出)。即使在SGLang中将temperature设为0,采样仍非确定性,因为动态批处理和radix cache的影响(过去讨论见此处)。
如TML博客所述,最大不确定性来源是批次大小变化:用户重复提交相同prompt时,因与其他请求批处理,批次大小差异导致非确定性输出。具体而言,不同批次大小影响内核的reduction splitting,导致reduction block顺序和大小变化,由于浮点运算非结合性,产生非确定输出。为解决此问题,他们用batch-invariant实现替换了reduction内核(RMSNorm、矩阵乘法、注意力等),并以伴生库形式开源。
He, Horace and Thinking Machines Lab, "Defeating Nondeterminism in LLM Inference", Thinking Machines Lab: Connectionism, Sep 2025.
基于TML工作,SGLang提供高吞吐量的确定性LLM推理解决方案,结合batch-invariant内核、CUDA graphs、radix cache和chunked prefill,性能高效。通过全面测试和RL训练实验验证确定性。
关键增强包括:
- 集成TML的batch-invariant内核,包括mean、log-softmax和矩阵乘法内核。
- 实现batch-invariant注意力内核,固定split-KV大小,支持FlashInfer、FlashAttention 3和Triton等多种后端。
- 完全兼容常见推理特性,如chunked prefill、CUDA graph、radix cache,在确定性模式下均支持。
- 暴露per-request seed,允许temperature > 0时启用确定性推理。
- 性能优化:对比TML博客的61.5% slowdown,SGLang在FlashInfer和FlashAttention 3后端平均仅34.35%,CUDA graphs下达2.8x加速。
实验结果
验证确定性行为
我们引入确定性测试套件,验证不同批处理条件下推理结果一致性。测试覆盖三个子测试,从简单到复杂:
- Single:相同prompt在不同批次大小下运行,检查输出一致。
- Mixed:同一批次混入短/长prompt,验证一致性。
- Prefix:从同一长文本派生不同前缀长度prompt,随机批处理,测试可重现性。
50次采样试验结果,数字表示每个子测试的唯一输出计数(越低越确定)。
| Attention Backend | Mode | Single Test | Mixed Test (P1/P2/Long) | Prefix Test (prefix_len=1/511/2048/4097) |
|---|---|---|---|---|
| FlashInfer | Normal | 4 | 3 / 3 / 2 | 5 / 8 / 18 / 2 |
| FlashInfer | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| FA3 | Normal | 3 | 3 / 2 / 2 | 4 / 4 / 10 / 1 |
| FA3 | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| Triton | Normal | 3 | 2 / 3 / 1 | 5 / 4 / 13 / 2 |
| Triton | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
*测试于QWen3-8B。启用CUDA graph和chunked prefill,FlashInfer和Triton禁用radix cache(支持开发中)。
CUDA Graph加速
CUDA graphs通过合并多个内核启动为单一启动加速推理。评估16个请求(输入/输出各1024 tokens)的总吞吐量,结果显示所有注意力内核至少2.79x加速。
| Attention Backend | CUDA Graph | Throughput (tokens/s) |
|---|---|---|
| FlashInfer | Disabled | 441.73 |
| FlashInfer | Enabled | 1245.51 (2.82x) |
| FA3 | Disabled | 447.64 |
| FA3 | Enabled | 1247.64 (2.79x) |
| Triton | Disabled | 419.64 |
| Triton | Enabled | 1228.36 (2.93x) |
*配置:QWen3-8B, TP1, H100 80GB。所有性能基准禁用radix cache。
离线推理性能测量
使用三种常见RL rollout工作负载(256请求,不同输入/输出长度)测量端到端延迟。确定性模式开销25%-45%,FlashInfer和FA3平均34.35%。主要开销来自未优化的batch-invariant内核,优化空间大。
| Attention Backend | Mode | Input 1024 Output 1024 | Input 4096 Output 4096 | Input 8192 Output 8192 |
|---|---|---|---|---|
| FlashInfer | Normal | 30.85 | 332.32 | 1623.87 |
| FlashInfer | Deterministic | 43.99 (+42.6%) | 485.16 (+46.0%) | 2020.13 (+24.4%) |
| FA3 | Normal | 34.70 | 379.85 | 1438.41 |
| FA3 | Deterministic | 44.14 (+27.2%) | 494.56 (+30.2%) | 1952.92 (+35.7%) |
| Triton | Normal | 36.91 | 400.59 | 1586.05 |
| Triton | Deterministic | 57.25 (+55.1%) | 579.43 (+44.64%) | 2296.60 (+44.80%) |
*配置:QWen3-8B, TP1, H200 140GB。禁用radix cache。
确定性推理虽较正常模式慢,建议用于调试和可重现性。未来工作聚焦加速,目标开销降至20%以下或与正常模式持平。
使用方法
环境设置
安装SGLang ≥0.5.3版本:
pip install "sglang[all]>=0.5.3"
启动服务器
SGLang支持多模型确定性推理。例如Qwen3-8B仅需添加--enable-deterministic-inference标志:
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-8B \
--attention-backend <flashinfer|fa3|triton> \
--enable-deterministic-inference
技术细节
Chunked Prefill
SGLang的chunked prefill技术用于处理长上下文请求,但默认分块策略违反注意力内核的确定性要求。如图所示,考虑两个长度6000的序列seq_a和seq_b,最大chunk大小8192,确定性注意力所需split-KV大小2048。每个序列可被分块处理...