(12月2日更新)
我们兴奋地宣布,SGLang新增一项重大功能:NVIDIA Model Optimizer的原生量化支持!这一集成优化了整个模型优化与部署流程,让你能在SGLang生态内直接从全精度模型转换为高性能量化端点。
高效服务大型语言模型(LLM)是生产环境中的最大挑战之一。模型量化是减少内存占用并提升推理速度的关键技术。此前,这一过程需要多步工作流和独立工具。现在,通过最新更新(PRs #7149、#9991 和 #10154),我们彻底消除了这些复杂性。
Model Optimizer与SGLang的优化结合,可在NVFP4与FP8推理中实现高达2倍的单GPU吞吐量提升。
新功能:SGLang中的直接ModelOpt API
SGLang现已直接集成NVIDIA Model Optimizer,让你能在SGLang代码中调用其强大的量化API。
这一新功能开启了简化的三步工作流:
- 量化:使用SGLang-ModelOpt接口应用先进量化技术,支持NVFP4、MXFP4、FP8等加速低精度推理。
- 导出:保存优化后的模型文件,完全兼容SGLang运行时。
- 部署:直接在SGLang运行时加载量化模型,在NVIDIA平台上服务,立即享受更低延迟和内存节省。
性能成果
通过新API优化的模型带来显著性能提升。这些优化可与其他NVIDIA软件硬件栈组件叠加,并适用于最新Blackwell架构的各种形式,从DGX Spark到GB300 NVL72。
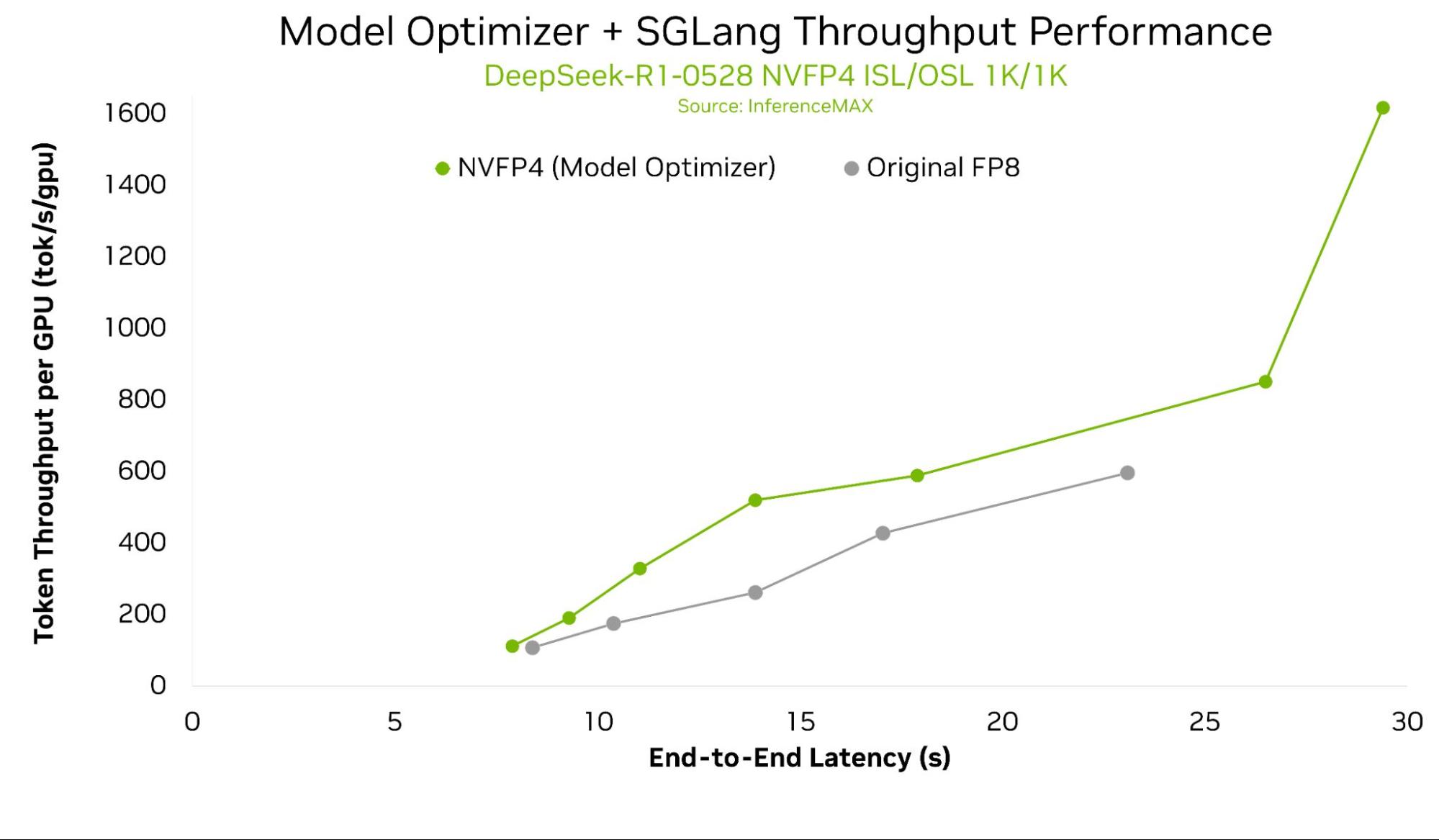
上图展示NVIDIA B200单GPU吞吐量 vs 端到端延迟,针对DeepSeek-R1-0528的多配置,使用Model Optimizer NVFP4量化模型,对比原生FP8和NVFP4。(DeepSeek-R1-0528在本API初始发布中暂不支持)
根据InferenceMAX最新结果,Model Optimizer与SGLang优化相比原生FP8基线,可实现高达2倍单GPU吞吐量。这些性能收益即将通过本博客所述原生集成实现。
快速上手指南
SGLang提供示例脚本,演示完整的Model Optimizer量化与导出流程。确保在SGLang环境中安装nvidia-modelopt和accelerate,然后运行以下代码片段:
import sglang as sgl
from sglang.srt.configs.device_config import DeviceConfig
from sglang.srt.configs.load_config import LoadConfig
from sglang.srt.configs.model_config import ModelConfig
from sglang.srt.model_loader.loader import get_model_loader
# 配置模型,使用ModelOpt量化并导出
model_config = ModelConfig(
model_path="Qwen/Qwen3-8B",
quantization="modelopt_fp8", # 或 "modelopt_fp4"
trust_remote_code=True,
)
load_config = LoadConfig(
modelopt_export_path="./quantized_qwen3_8b_fp8",
modelopt_checkpoint_save_path="./checkpoint.pth", # 可选,伪量化检查点
)
device_config = DeviceConfig(device="cuda")
# 加载并量化模型(导出自动进行)
model_loader = get_model_loader(load_config, model_config)
quantized_model = model_loader.load_model(
model_config=model_config,
device_config=device_config,
)量化导出后,可通过SGLang部署模型:
# 部署导出的量化模型
python -m sglang.launch_server \
--model-path ./quantized_qwen3_8b_fp8 \
--quantization modelopt \
--port 30000 --host 0.0.0.0或使用Python API:
import sglang as sgl
from transformers import AutoTokenizer
def main():
# 部署导出的ModelOpt量化模型
llm = sgl.Engine(
model_path="./quantized_qwen3_8b_fp8",
quantization="modelopt"
)
# 使用Qwen3-8B聊天模板格式化提示
tokenizer = AutoTokenizer.from_pretrained("./quantized_qwen3_8b_fp8")
messages = [
[{"role": "user", "content": "Hello, how are you?"}],
[{"role": "user", "content": "What is the capital of France?"}]
]
prompts = [
tokenizer.apply_chat_template(m, tokenize=False, add_generation_prompt=True)
for m in messages
]
# 运行推理
sampling_params = {"temperature": 0.8, "top_p": 0.95, "max_new_tokens": 512}
outputs = llm.generate(prompts, sampling_params)
for i, output in enumerate(outputs):
print(f"Prompt: {prompts[i]}")
print(f"Output: {output['text']}")
if __name__ == "__main__":
main()结语
这一原生Model Optimizer集成强化了SGLang作为LLM推理简单强大平台的承诺。我们将继续缩小高性能模型优化与部署间的差距。
期待你使用这一新功能取得的性能提升!请访问我们的GitHub仓库拉取最新版本试用。
欢迎加入专用Slack频道#modelopt,讨论modelopt、量化及低精度数值话题!若未加入工作区,请先在此加入。
致谢
NVIDIA团队:Zhiyu Cheng, Jingyu Xin, Huizi Mao, Eduardo Alvarez, Pen Chung Li, Omri Almog
SGLang团队与社区:Qiaolin Yu, Xinyuan Tong