在智能体强化学习(agentic RL)中,一次rollout并非单次生成,而是模型调用、工具输出、harness消息和恢复生成的链式过程。Token-In-Token-Out(TITO)是解决该过程中训练-推理不匹配的核心设计原则:训练器必须评估推理引擎在rollout期间实际消费和产生的完全相同的token序列。
TITO的定义
在智能体rollout中,模型反复与外部环境交互。每轮(turn)中,推理引擎接收一个token序列作为prompt并生成新的token序列。若满足TITO原则,对于所有n,第n-1轮的总token序列(prompt + response)必须是第n轮prompt token序列的bit-perfect前缀。
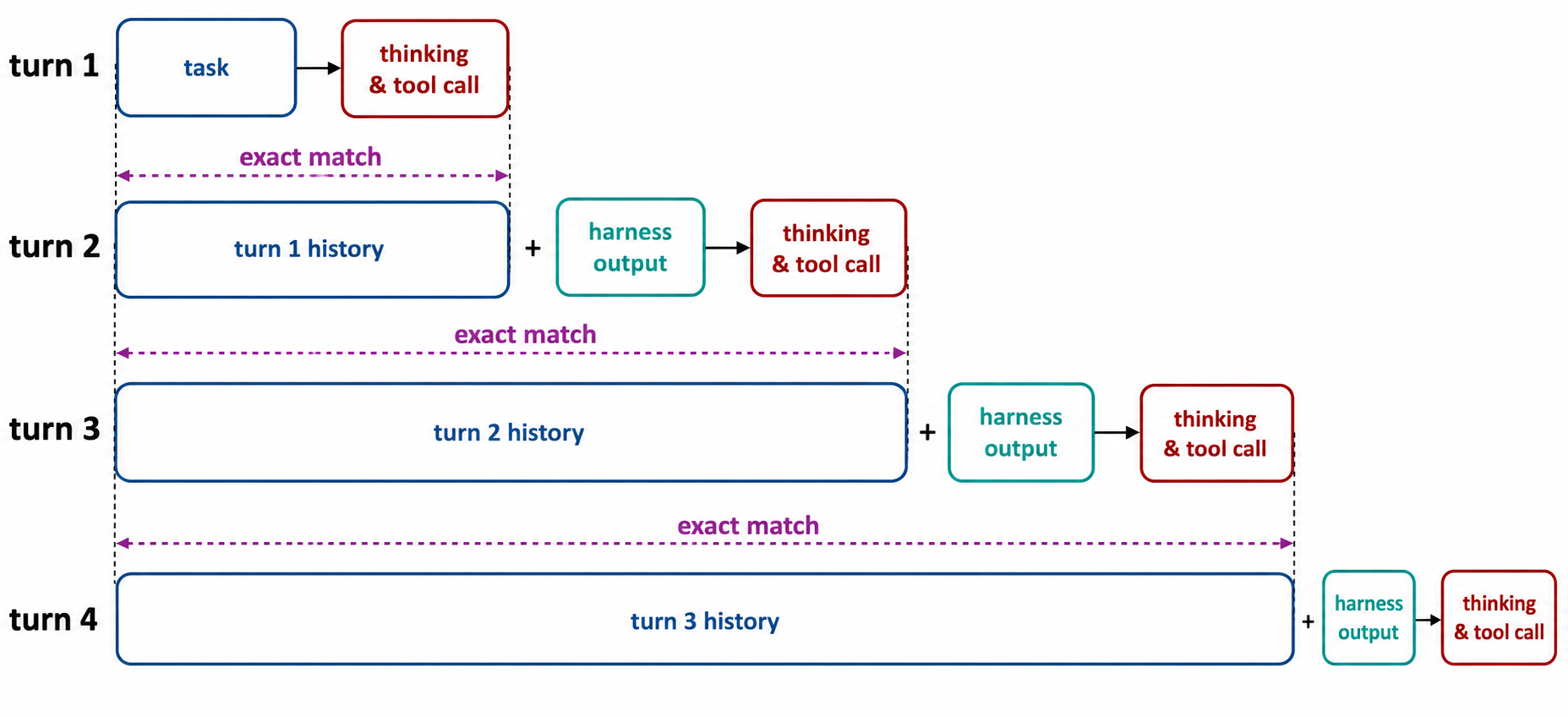
为什么TITO至关重要
训练效率:每个任务仅一个样本
在包含数十轮的智能体任务中,采用“每个任务一个样本”策略可将计算开销降低一个数量级,显著提升训练可扩展性。
数学正确性:保持on-policy
若TITO被违反,训练器与推理引擎对同一token的条件分布可能出现巨大差异,导致不稳定更新。
TITO可能被破坏的场景
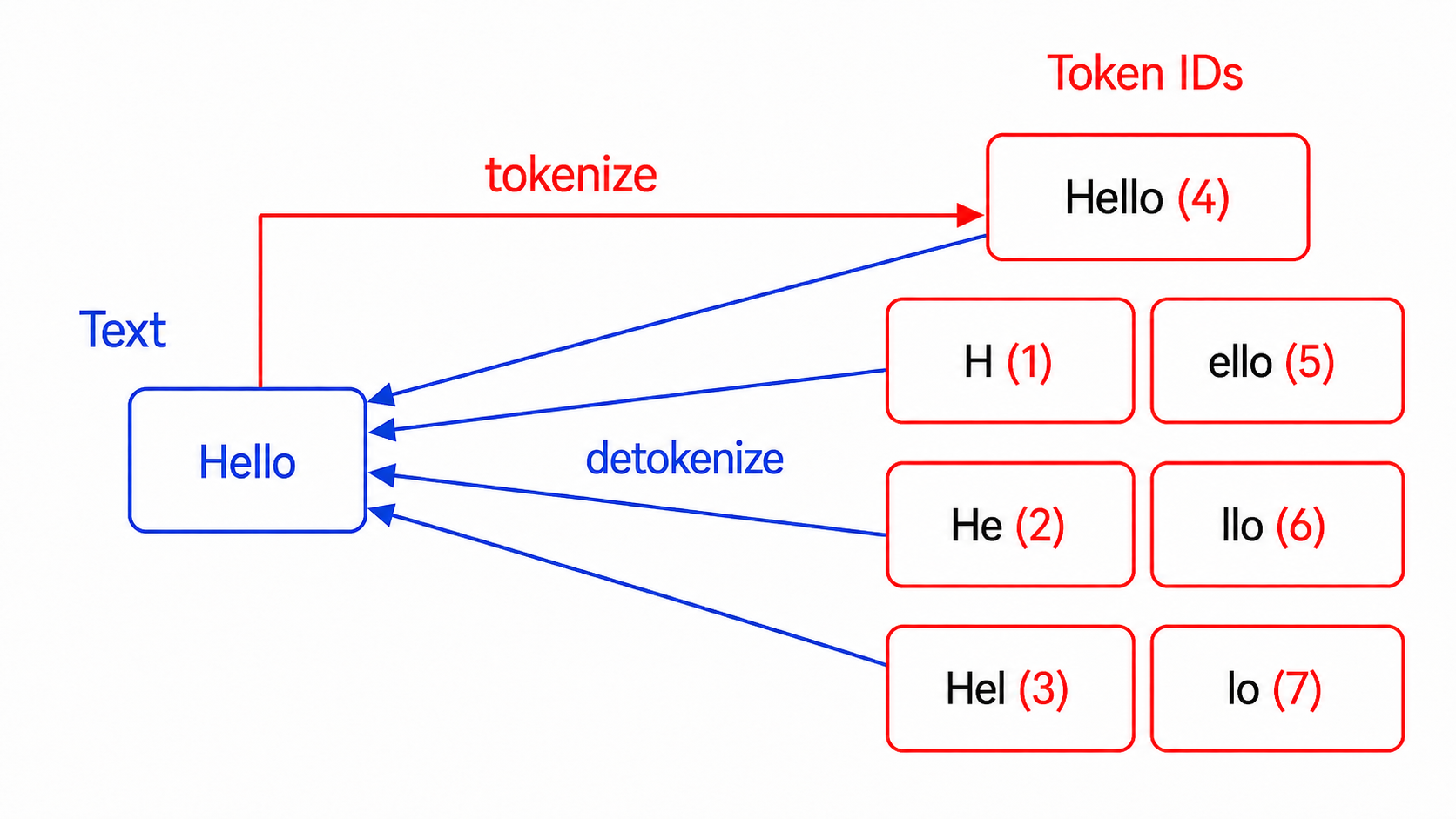
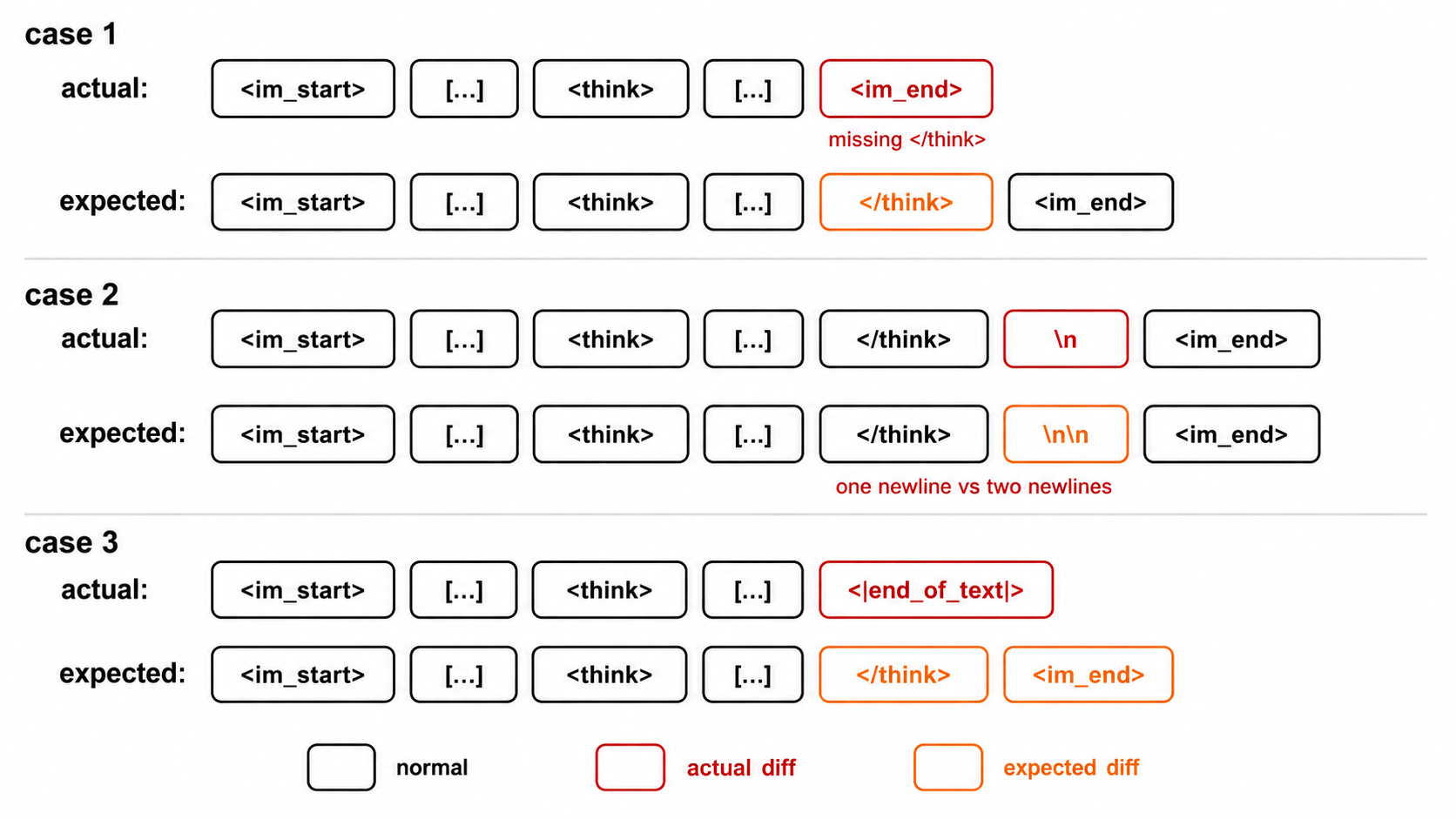
场景1:Detokenize-retokenize不匹配
模型生成的token经解码再编码后可能丢失原始token序列。
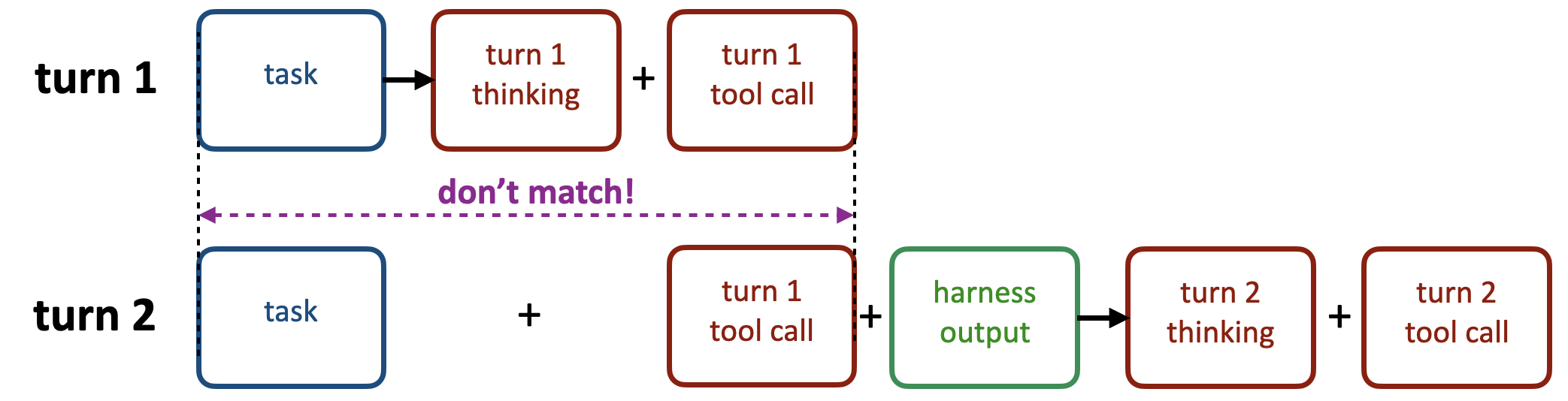
场景2:聊天模板裁剪推理内容
cut-thinking边界随User消息注入而前移,擦除历史推理。
场景3:聊天模板重渲染导致的字节漂移
JSON序列化差异会改变token ID,破坏bit-perfect前缀。
Miles框架中的TITO实现
Miles通过四个组件机械化保障TITO不变性。
(1)推理会话服务器
维护每轨迹的增长token缓冲区,直接传递给训练。
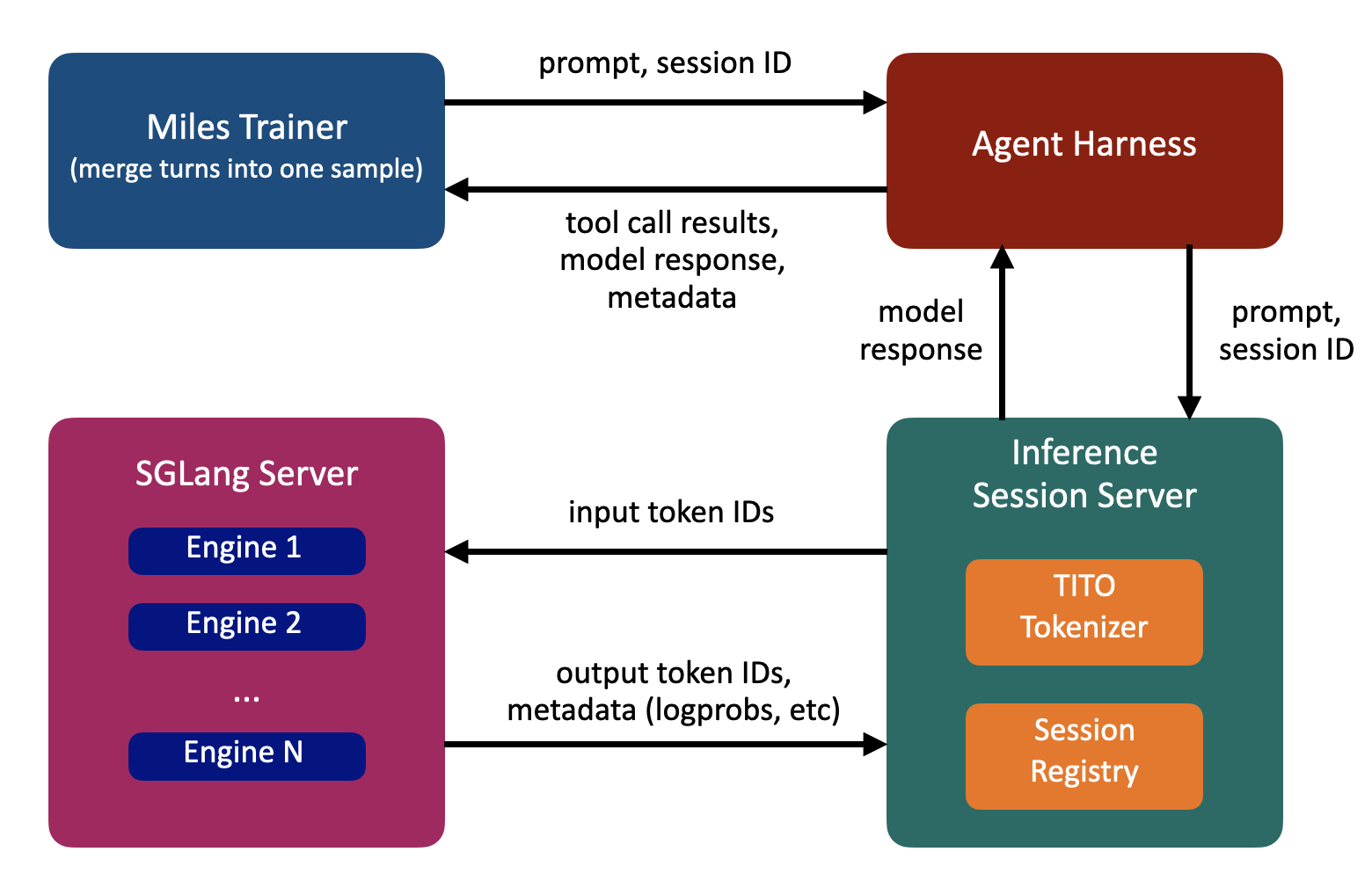
(2)三层追加-only保障
消息列表、聊天模板渲染与token序列均严格追加,避免任何改写。
通过固定Qwen3与GLM-4.7模板,Miles实现了低成本模型接入。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接