大语言模型(LLM)预训练通常意味着巨大的算力投入。过去,MLPerf™ Training 基准套件中的 Llama 3.1 405B、Llama 3.1 8B 等预训练项目主要面向 dense model,往往需要大规模多节点基础设施,这也让不少希望参与基准测试的机构面临较高门槛。
为降低参与难度,同时覆盖当下更具代表性的稀疏架构,MLPerf Training Working Group 在 AMD、NVIDIA 与 NIT University 成员组成的任务组推动下,引入了新的预训练基准:GPT-OSS 20B。这是一个现代化的 Mixture-of-Experts(MoE) 基准,能够评估 MoE 架构中常见的复杂 routing logic 与 sparse computation pattern,并且可在小到单个 8-GPU 节点的硬件配置上运行。
为什么选择 GPT-OSS 20B
任务组认为,GPT-OSS 20B 是适合作为小规模 MoE 预训练基准的候选模型,主要原因有三点:
- 稀疏计算效率:GPT-OSS 20B 拥有约 21B 总参数,但采用 MoE 设计,每个 token 仅激活 3.6B 参数。这使模型能够保留较大的知识容量,同时保持接近更小 dense model 的计算开销。
- 从零开始训练:为了简化基准流程,并避免参与者下载多 GB checkpoint 的额外成本,GPT-OSS 20B 从随机权重开始训练。这让它成为对系统从初始状态优化稀疏模型能力的纯粹测试。
- 参考实现可复用:参考代码基于 AMD 的 Primus 框架构建。Primus 是一个新的通用训练库,支持 AMD 与 NVIDIA 后端。主要验证工作在 AMD Instinct™ MI355X 与 NVIDIA B200 系统上完成。
数据集与 Tokenization
GPT-OSS 20B 使用 C4(Colossal Cleaned Common Crawl) 数据集,并采用与 Llama 3.1 8B 基准相同的预 tokenized 子集和 Llama-3 compatible tokenizer。对于已经为其他 MLPerf Training 基准准备好数据的提交者来说,这降低了额外配置成本。
训练数据包含约 80 GB 预先打乱的 C4 shards,托管在 MLCommons™ storage 上。为保证稳定性,基准要求每训练 12,288 个样本(在 GBS=16 时为 768 次迭代)后,使用验证集前 1,024 个样本进行评估。
统计方差:公平基准的核心挑战
基准测试的核心目标之一是公平性。在大规模训练中,公平性通常通过 Coefficient of Variation(CV) 衡量,即标准差与均值之比:CV = σ / μ × 100%。
高 CV 为什么会破坏公平性
如果一个基准的 CV 很高,就意味着结果中存在显著“统计噪声”。例如,一次运行可能需要 170k samples 收敛,另一次却因为随机性需要 250k samples,那么结果就不再能清晰反映硬件或软件栈的优劣。对于一个可信的行业标准而言,用户必须能够复现结果;过高的方差会让人难以判断成绩提升究竟来自工程突破,还是单纯的运气。
把 CV 从约 15% 降到 5% 以下
降低 CV 的常见方式,是从已经度过早期不稳定阶段的 pretrained checkpoint 开始。但任务组希望保持基准简单,不要求提交者额外下载大型 checkpoint。因此,他们通过三项关键技术干预,将 CV 从约 15% 降至 5% 以下。
1. 消除验证集噪声
早期测试中,团队观察到 evaluation loss 出现大幅且不具代表性的尖峰。
- 问题发现:验证集在每次评估时都会被重新 shuffle。对于 routing 对输入分布高度敏感的稀疏 MoE 模型来说,这会引入人为的 jitter。
- 解决方案:基准现在强制使用 C4 验证集前 1,024 个样本组成的静态、未打乱集合进行评估,确保每次运行、每个评估步骤面对完全一致的测试输入。
2. 稳定 Optimizer
许多现代模型会使用 Adam epsilon(ε)为 10^-8,但任务组发现,在 20B 规模 MoE 从零训练时,这一设置会导致过多发散。通过对齐 Llama 3.1 8B 所采用的标准,将 ε 设置为 10^-5,团队为训练提供了必要的数值稳定性,降低了“倒霉”的梯度更新破坏 sparse experts 的概率。
3. 统一初始化标准
为了确保所有参与者从相同的“统计能量”起跑,任务组严格定义了权重初始化标准:init_method_std = 0.008。这可以避免不同初始点在高维 loss landscape 中带来的额外方差。
技术配置与质量指标
GPT-OSS 20B 的目标精度是验证损失(log perplexity)达到 3.34。这一目标来自在 AMD MI355X 与 NVIDIA B200 硬件上的大量 sweep,代表了一个兼顾稳定收敛与合理运行时间的平衡点;在使用 BFloat16 精度时,收敛时间约为 6.5 小时。
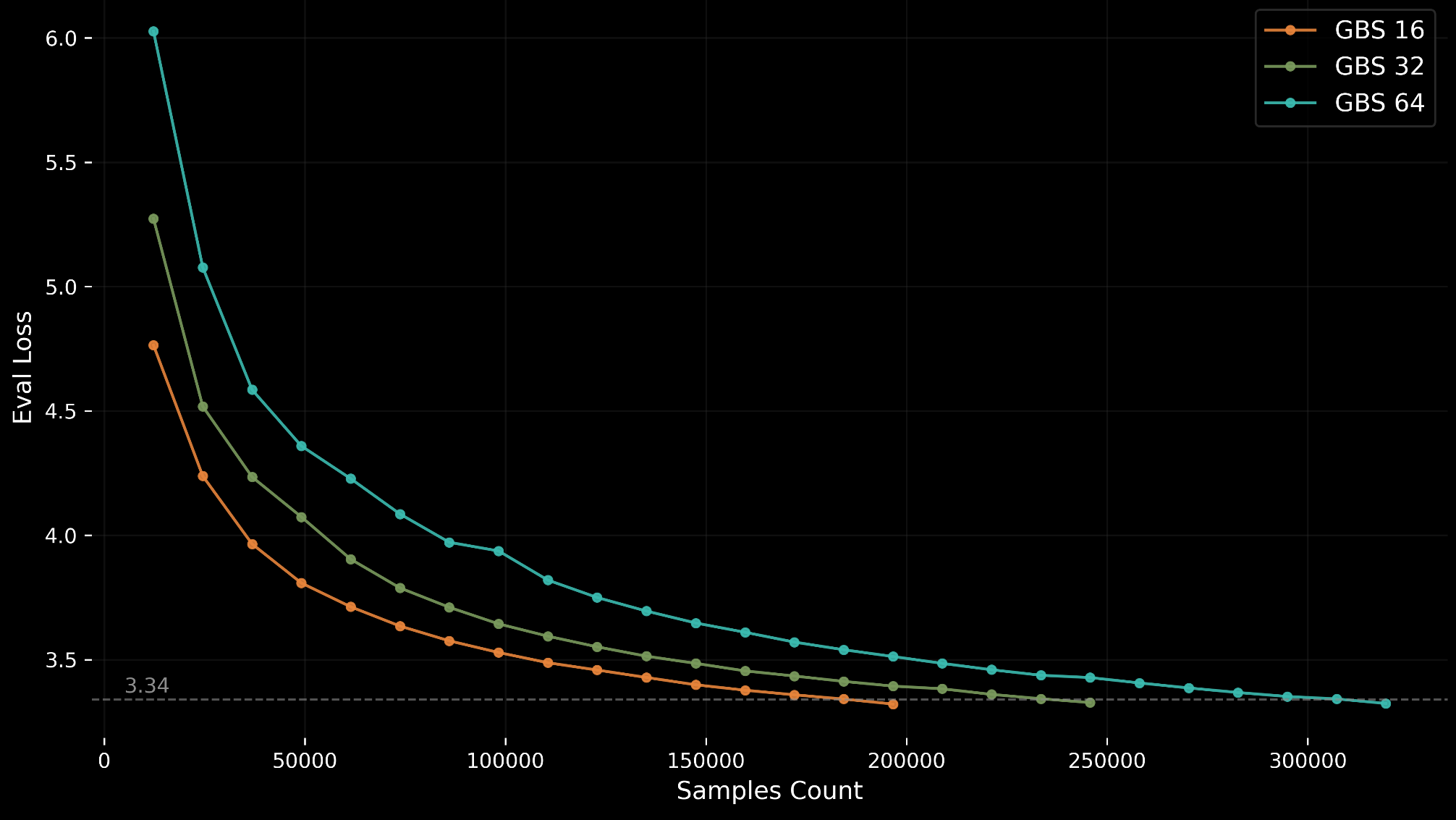
| Feature | Specification |
|---|---|
| Model Type | Mixture-of-Experts(MoE) |
| Active Parameters | 每个 token 激活 3.6B 参数 |
| Sequence Length | 8,192 |
| Expert Parallelism | 8 |
| Target Loss | 3.34 |
| Submission Requirement | 每个配置提交 10 次运行结果,用于平均噪声 |
为了便于针对不同硬件进行优化,提交者允许调节三项超参数:global batch size、learning rate 与 learning rate warmup。
结论:把 MoE 预训练纳入标准化评测
GPT-OSS 20B 将 MoE 预训练正式带入 MLPerf Training 基准套件。通过定位并消除训练方差来源——包括验证集 shuffle、optimizer 不稳定以及初始化不一致——任务组提供了一个稳定、高保真的基准,同时保持了对提交者的可访问性。
这意味着 MLPerf Training v6.0 的成绩将更能反映真实的硬件与软件效率,而不是随机波动。GPT-OSS 20B 也为社区提供了一种标准化方式,用于在现有 dense workload 之外评估 sparse pretraining performance。其参考实现已在 MLCommons GitHub repository 上提供。
本文相关类别为 MLPerf Training News。文章作者包括 Sarthak Arora(AMD)、Su-Ann Chong(AMD)、Ravi Dwivedula(AMD)、Miro Hodak(AMD)、Michal Marcinkiewicz(NVIDIA)与 Shriya Rishab(NVIDIA)。更多 MLCommons 信息可访问 MLCommons.org。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接