动机与架构相关性
随着大型语言模型(LLM)开发日益转向稀疏计算,用于评估训练性能的基准也需要随之演进。MLPerf™ Training v6.0新增了一个基于DeepSeek-V3的大规模预训练基准,该模型采用Mixture-of-Experts(MoE)架构,总参数达671B,其中每token激活37B参数。
这一基准捕捉了行业中已成为标准的关键创新,包括Multi-head Latent Attention(MLA)和无辅助损失的负载均衡。
技术架构与实现
DeepSeek-V3引入了若干独特计算模式,与当前套件中的稠密模型(如Llama 3.1)形成鲜明对比:
- Multi-head Latent Attention (MLA):不同于标准Multi-Head Attention(MHA),MLA通过低秩联合压缩Key-Value(KV)缓存,减少训练和推理中的内存带宽瓶颈。
- 细粒度专家分割:每个专家前馈网络(FFN)被分割为m个更小的专家。虽然典型MoE可能使用top-2路由覆盖16个专家,但DeepSeek-V3扩展至160个路由专家加上共享专家,以捕捉共同知识。
- Multi-Token Prediction (MTP):模型采用2-token预测目标训练。这需要共享主干和两个专用输出头,在反向传播中提高计算与内存比率。
- 无辅助损失负载均衡:为避免路由崩溃而不引入高开销的辅助损失,该方法基于实时负载动态调整每个专家的偏置项。
基准定义与参考设置
任务定义为使用Mixture-of-Experts目标的LLM预训练。
数据集与分词
- 数据集:C4(Colossal Clean Crawled Corpus)
- 分词器:Llama-3兼容分词器(128k词汇表)
- 序列长度:4,096 tokens
收敛与检查点
任务组发现MoE模型在训练早期会处于token不平衡状态。由于基准仅捕捉完整训练的一小部分,这种不平衡状态占基准时间的约50%,这并不代表稳态MoE训练。为确保基准测量稳态硬件效率,任务组采用暖启动方法。
由于基准使用Llama 8B分词器而非原DeepSeek分词器,从Hugging Face检查点初始化会导致显著token不平衡。为解决此问题,任务组对检查点进行50步微调,使专家token分布接近原DeepSeek分词器的结果(如图1所示)。生成的检查点采用HuggingFace格式,由MLCommons托管。这一方法确保基准运行的98%以上处于平衡专家状态,反映长期训练动态。
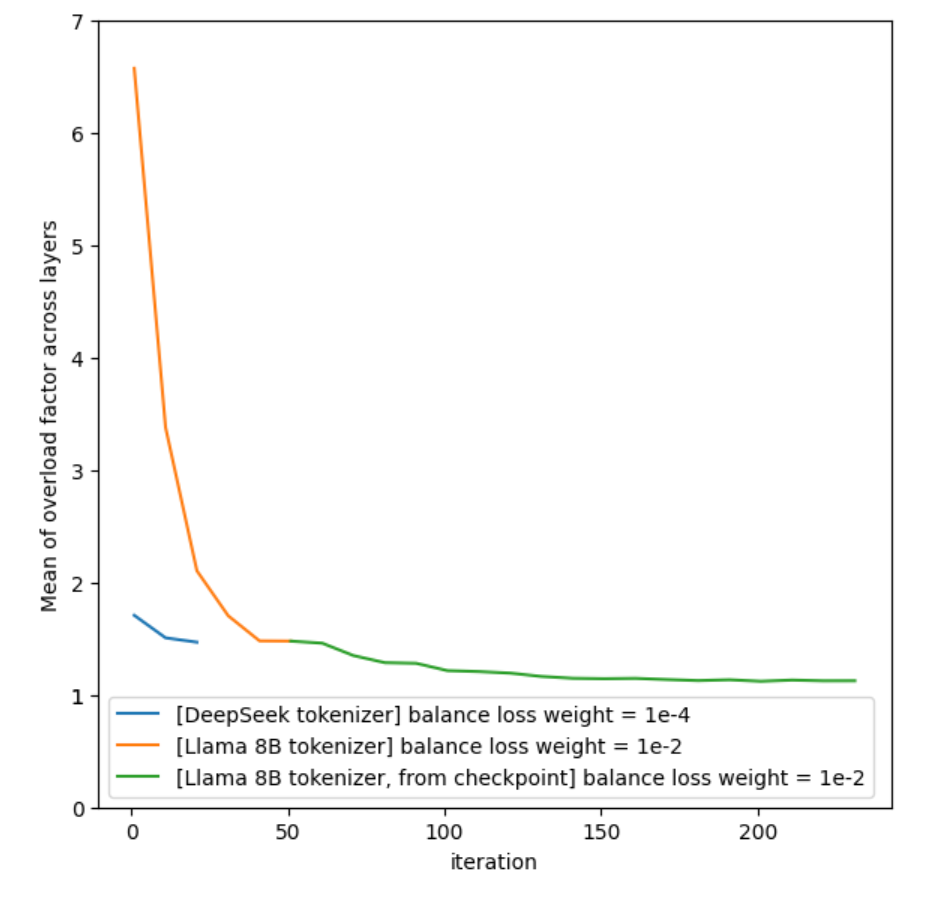
(图1)
全局批大小(GBS)选择
该基准要求GBS至少为15,360。尽管内部测试显示模型在较低批大小(如512、1k或2k)下保持计算效率,但任务组基于三点原因设定更高下限:
- 代表性:原DeepSeek-V3预训练采用批大小调度策略,峰值达15,360。为代表论文所述的真实大规模预训练,基准针对15k-18k范围。
- 基准公平性:设定15k最小GBS确保所有提交者公平竞争,避免在小批大小下的“英雄跑分”,这些不反映生产规模MoE训练。
- 收敛缩放:任务组确立平方根缩放规则以维持大批大小下的学习率稳定性:LR(GBS)=2.4×10^{-5}×√(GBS/16384)
工程挑战与验证
参考实现(使用NVIDIA NeMo Megatron-bridge)的开发突显了收敛的关键要求:
- 专家并行(EP):对于单层,路由专家均匀部署在64个GPU(8个节点)上。实施节点限制路由,每token最多发送至M=4个节点。
- 内存管理:专家容量不得限制,以避免检查点加载后初始步骤中token不平衡引发的内存溢出(OOM)错误,确保基准代表真实训练条件。
- 目标指标:基准针对交叉熵验证损失3.6,变异系数(CV)为1.5%(如图2所示)。
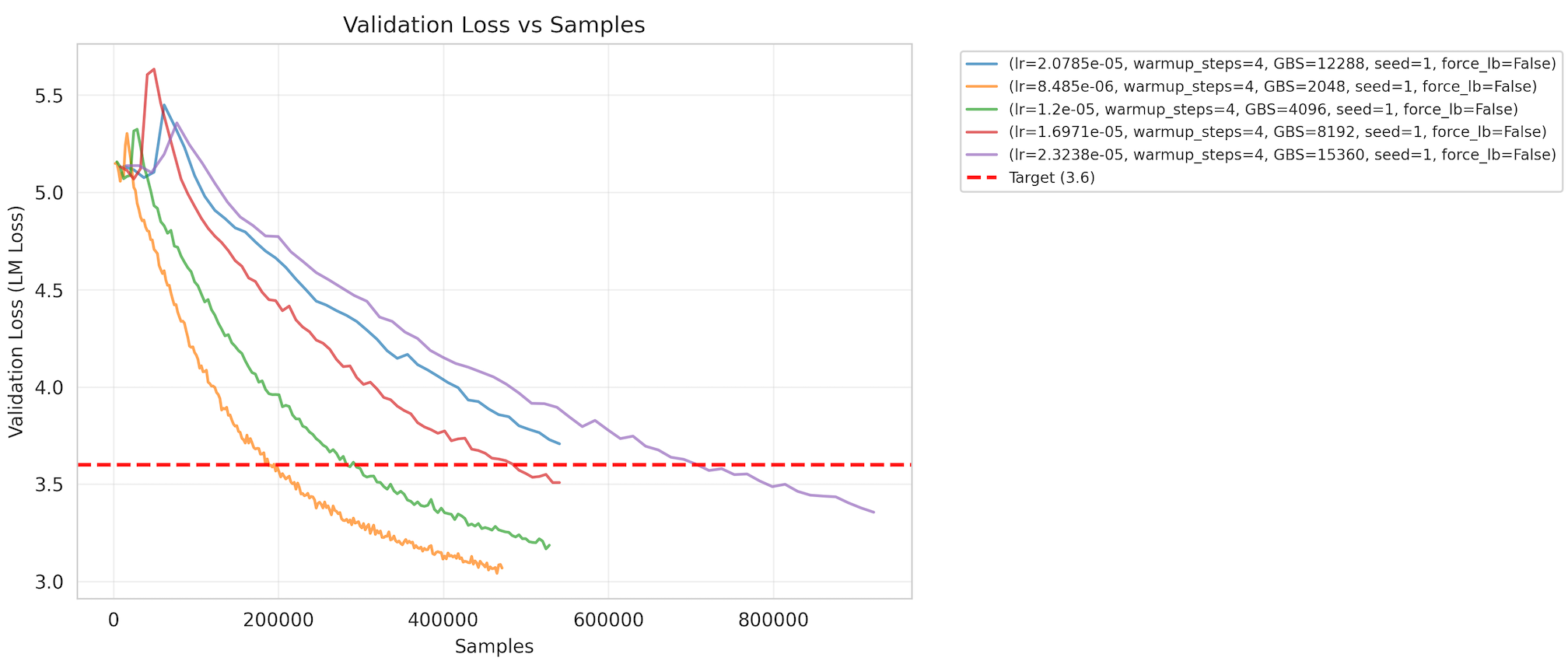
(图2)
结论
这一基准为评估领先开源MoE模型的生产规模训练效率提供标准化平台。通过明确定义收敛、批大小和专家并行要求,DeepSeek-V3基准确保MLPerf Training持续反映当代AI基础设施状态。
参考实现可在MLCommons GitHub仓库获取,任务组欢迎社区提交和反馈。更多MLCommons信息及会员详情,请访问MLCommons.org。
类别
MLPerf Training News
作者
Denys Fridman (NVIDIA) Michal Marcinkiewicz (NVIDIA) Shriya Rishab (NVIDIA) Qinwen Xu (Google) Parmita Mehta (Google)
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接