動機とアーキテクチャの関連性
大規模言語モデル(LLM)の開発が疎な計算へとシフトするのに伴い、学習性能を評価するためのベンチマークも進化する必要があります。MLPerf™ Training v6.0では、DeepSeek-V3に基づく大規模事前学習ベンチマークが新たに追加されました。このモデルはMixture-of-Experts(MoE)アーキテクチャを採用し、総パラメータ数は671B、tokenごとに37Bパラメータが活性化されます。
本ベンチマークは、Multi-head Latent Attention(MLA)や無補助損失の負荷分散など、業界標準となった主要な技術革新を捕捉しています。
技術アーキテクチャと実装
DeepSeek-V3は、現行スイートの稠密モデル(Llama 3.1など)とは際立って異なる、いくつかの独自の計算パターンを導入しています:
- Multi-head Latent Attention (MLA):標準的なMulti-Head Attention(MHA)と異なり、MLAは低ランク結合圧縮によってKey-Value(KV)キャッシュを削減し、学習および推論におけるメモリ帯域幅のボトルネックを緩和します。
- 細粒度なエキスパート分割:各エキスパートのフィードフォワードネットワーク(FFN)はm個の小さなエキスパートに分割されます。一般的なMoEではtop-2ルーティングで16個のエキスパートをカバーする場合がありますが、DeepSeek-V3は160個のルーティングエキスパートに拡張し、加えて共通知識を捕捉するための共有エキスパートも備えます。
- Multi-Token Prediction (MTP):モデルは2-token予測目的で学習されます。これには共有バックボーンと2つの専用出力ヘッドが必要であり、逆伝播における計算とメモリの比率を向上させます。
- 無補助損失の負荷分散:ルーティング崩壊を回避しつつ高オーバーヘッドの補助損失を導入しないため、リアルタイムの負荷に基づき各エキスパートのバイアス項を動的に調整します。
ベンチマーク定義と参考設定
タスクは、Mixture-of-Experts目的を用いたLLM事前学習として定義されます。
データセットとトークナイズ
- データセット:C4(Colossal Clean Crawled Corpus)
- トークナイザ:Llama-3互換トークナイザ(128k語彙)
- シーケンス長:4,096 tokens
収束とチェックポイント
タスクグループは、MoEモデルが学習初期段階でtoken不均衡状態にあることを発見しました。ベンチマークは完全な学習のごく一部のみを捕捉するため、この不均衡状態がベンチマーク時間の約50%を占めることになり、これは定常状態のMoE学習を代表していません。ベンチマークが定常状態のハードウェア効率を測定することを保証するため、タスクグループはウォームスタート手法を採用しました。
本ベンチマークはオリジナルのDeepSeekトークナイザではなくLlama 8Bトークナイザを使用するため、Hugging Faceチェックポイントから初期化すると顕著なtoken不均衡が生じます。この問題を解決するため、タスクグループはチェックポイントに対して50ステップのファインチューニングを実施し、エキスパートのtoken分布をオリジナルDeepSeekトークナイザの結果に近づけました(図1参照)。生成されたチェックポイントはHuggingFace形式を採用し、MLCommonsがホスティングしています。この手法により、ベンチマーク実行の98%以上がエキスパートのバランスが取れた状態となり、長期的な学習動態を反映します。
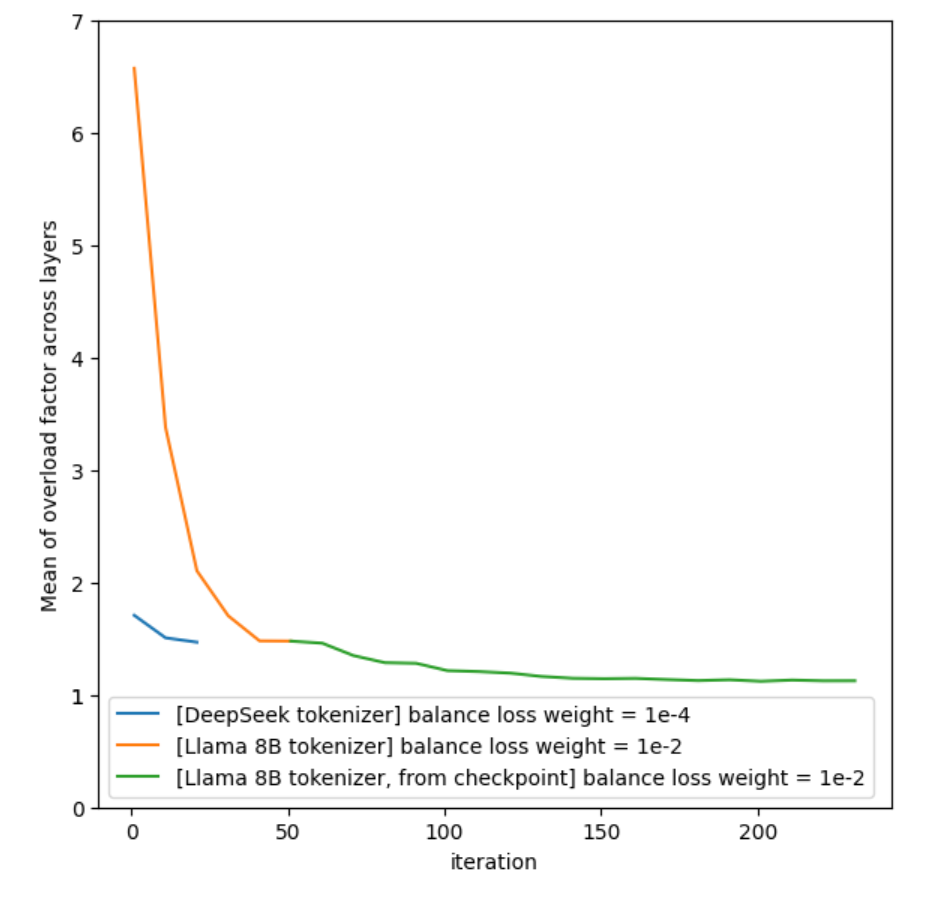
(図1)
グローバルバッチサイズ(GBS)の選択
このベンチマークではGBSが少なくとも15,360であることが要求されます。社内テストでは、より小さなバッチサイズ(512、1k、2kなど)でもモデルが計算効率を維持することが示されましたが、タスクグループは以下の3点の理由から高めの下限を設定しました:
- 代表性:オリジナルのDeepSeek-V3の事前学習はバッチサイズスケジューリング戦略を採用し、ピーク時に15,360に達します。論文に記述された実際の大規模事前学習を代表するため、ベンチマークは15k〜18kの範囲を対象としています。
- ベンチマークの公平性:15kの最小GBSを設定することで、全提出者の公平な競争が保証され、生産規模のMoE学習を反映しない小バッチサイズでの「ヒーロースコア」を回避します。
- 収束スケーリング:タスクグループは大バッチサイズでの学習率の安定性を維持するため、平方根スケーリング則を確立しました:LR(GBS)=2.4×10^{-5}×√(GBS/16384)
エンジニアリング上の課題と検証
参考実装(NVIDIA NeMo Megatron-bridgeを使用)の開発により、収束に関する重要な要件が浮き彫りになりました:
- エキスパート並列(EP):単一レイヤにおいて、ルーティングエキスパートは64個のGPU(8ノード)に均等に配置されます。ノード制限ルーティングを実装し、各tokenは最大M=4ノードまで送信されます。
- メモリ管理:エキスパート容量は制限してはなりません。これは、チェックポイント読み込み後の初期ステップにおけるtoken不均衡によるメモリオーバーフロー(OOM)エラーを回避し、ベンチマークが現実の学習条件を代表することを保証するためです。
- 目標指標:ベンチマークは交差エントロピー検証損失3.6を目標とし、変動係数(CV)は1.5%です(図2参照)。
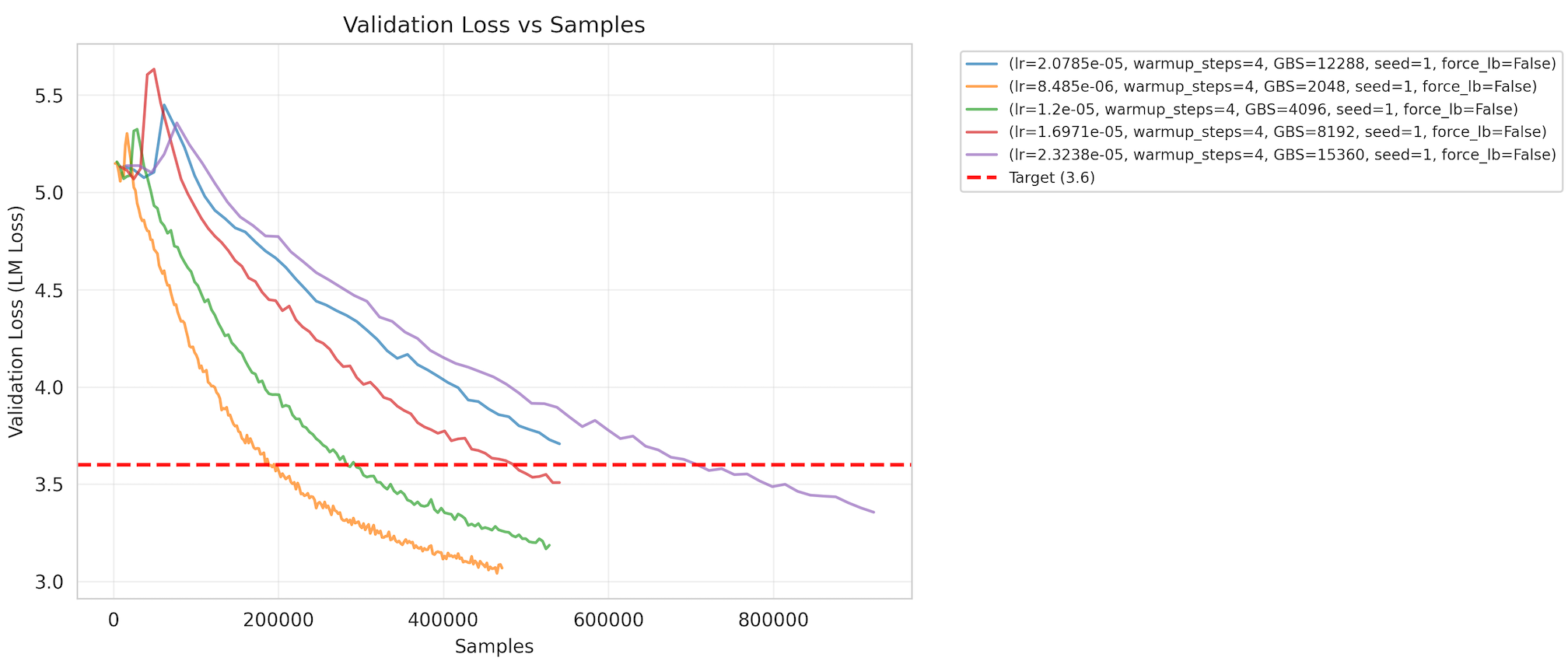
(図2)
結論
このベンチマークは、主要なオープンソースMoEモデルの生産規模での学習効率を評価するための標準化されたプラットフォームを提供します。収束、バッチサイズ、エキスパート並列の要件を明確に定義することにより、DeepSeek-V3ベンチマークはMLPerf Trainingが現代のAIインフラストラクチャの状況を継続的に反映することを保証します。
参考実装はMLCommons GitHubリポジトリから入手可能であり、タスクグループはコミュニティからの提出とフィードバックを歓迎します。MLCommonsの詳細情報および会員情報については、MLCommons.orgをご覧ください。
カテゴリ
MLPerf Training News
著者
Denys Fridman (NVIDIA) Michal Marcinkiewicz (NVIDIA) Shriya Rishab (NVIDIA) Qinwen Xu (Google) Parmita Mehta (Google)
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接