MLCommons has officially released Croissant 1.1, the latest evolution of the community-built machine learning dataset metadata format. Croissant 1.0 established a standardized machine-readable dataset metadata structure, while version 1.1 further introduces machine-operable provenance tracking, vocabulary interoperability to link domain ontologies, structured usage policies for automated license enforcement, and enhanced modeling for complex multidimensional datasets.
These new features are tailored for the AI "agentic era," including machine-operable provenance tracking, extended schema types, and governance labels, enabling datasets to be fully interpreted and reused by autonomous systems.
Machine-Operable Provenance Tracking: Complete Data Lineage
Version 1.1 adds chain-of-custody verification and auditing capabilities for data-centric AI systems. It adopts the W3C PROV-O model to record the provenance of datasets, files, or individual records, linking source data and processing steps while attributing responsible agents (people or software).
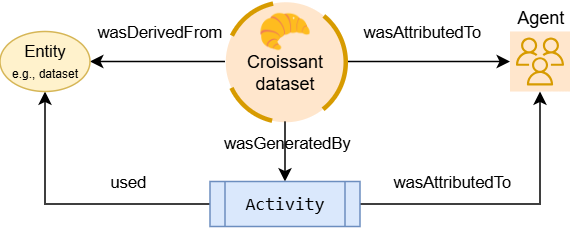
Figure: Croissant captures machine-readable data provenance tracking
The chain-of-custody approach provides transparency for systems and auditors, enabling traceability of a dataset's complete path through entities, activities, and agents, as well as evaluation of its origin and processing history. This detailed audit trail embedded in metadata helps verify data quality and compliance. For example, the widely used Common Crawl dataset has already adopted Croissant 1.1 metadata, demonstrating large-scale embedding of machine-readable provenance and processing semantics.
Flexible Vocabulary Framework: Enhanced Interoperability
Croissant 1.1 introduces a flexible vocabulary framework that supports linking external vocabularies or identifiers at multiple levels (dataset, field, or data type), enabling reuse of domain semantics without reinvention. For example:
- Dataset level: Can reference Wikidata or ontology IDs (e.g., diseases or events) to classify content, supporting cross-repository discovery.
- Field level: Columns can point to controlled vocabulary terms (e.g., environmental or phenotypic concepts), clarifying meaning or referencing sources.
- Data level: Field values can be annotated with semantic classes (e.g., linking a "location" field to a geographic concept).
These conventions allow Croissant metadata to integrate directly into existing standards. Its modular extensible design means that if data already follows an ontology, it can simply be referenced. This interoperability is crucial for portability and compatibility.
Enhanced Data Governance: Automated License Enforcement
Version 1.1 strengthens data governance support by encoding usage permissions and restrictions using standard policy vocabularies. For detailed consent requirements, it integrates the Data Use Ontology (DUO), allowing tags for permitted use categories such as "General Research Use" or "Non-Commercial Use." These DUO tags make consent constraints machine-discoverable.
For finer-grained control, it can embed W3C ODRL (Open Digital Rights Language) policies to express usage rules. Agents can automatically verify whether a proposed use is allowed based on embedded DUO codes or ODRL terms. These features make Croissant an active data governance enforcer in automated workflows.
Optimized Complex Dataset Description
Croissant 1.1 improves the description of complex ML datasets. Fields can now represent multidimensional arrays, with new attributes supporting semantic types, example values, or validation rules. Each row of data can carry explicit semantic meaning—for instance, one field as an image and another as a numerical label.
With these capabilities, Croissant 1.1 becomes the ML dataset metadata standard for the current AI ecosystem. It combines schema.org's broad coverage with extensible vocabularies to generate fully machine-operable metadata graphs that holistically capture provenance, semantics, and governance.
As AI systems move toward open models and autonomous agents, self-describing metadata embedding provenance and governance becomes critical. Every dataset comes with its own audit trail and usage policies, supporting trust building. Community adoption is strong: now 700,000 datasets carry Croissant metadata, with major tools and frameworks (such as TensorFlow and PyTorch for machine learning, Dataverse and CKAN for data publishing platforms) natively loading it. Major repositories like Hugging Face, Kaggle, and OpenML embed Croissant metadata. Similar interest in provenance standards is also emerging among data companies like HumanSignal and CommonCrawl, whose services generate dataset collections.
We encourage dataset creators to adopt Croissant 1.1 to make their data more discoverable and usable. Embedding rich interoperable metadata in every dataset helps build an AI ecosystem where agents can autonomously discover and use data while fully respecting provenance, privacy, and licenses.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接