
1. 引言
Qwen是由阿里云Qwen团队开发的大型高性能大语言模型(LLM)系列。从初代到最新的第三代旗舰模型,所有Qwen变体均经过专用训练和精细调优,具备强大的指令跟随能力、高效的交互式AI部署性和复杂任务求解性能。作为Qwen3家族旗舰,Qwen3-235B和Qwen3-VL-235B实现了多维度全面提升,并在Qwen APP中大规模部署。
近日,Qwen C端基础设施工程团队与AMD AI框架团队合作,在AMD InstinctTM MI300X系列GPU平台上基于SGLang框架,为Qwen3-235B和Qwen3-VL-235B实施极端延迟优化方案,在性能、精度和稳定性上取得显著突破:
- Qwen3-235B:相比基线,TTFT提升1.67×,TPOT提升2.12×。
- Qwen3-VL-235B:相比基线,TTFT提升1.62×,TPOT提升1.90×。
AMD InstinctTM MI300X系列GPU基于CDNATM 3架构,每卡配备192GB HBM3内存,支持70B+参数模型推理,结合5.3TB/s内存带宽、256MB Infinity Cache及原生FP8和PTPC量化Matrix Core,提供卓越性能和性价比,理想用于大规模LLM集群部署。
本文详述两团队联合探索的性能优化技术,核心聚焦超低延迟推理。所有优化工作已开源:[Tracking][Performance][AMD] Qwen3 & Qwen3-VL Latency Optimization on AMD InstinctTM MI300X Series GPUs。
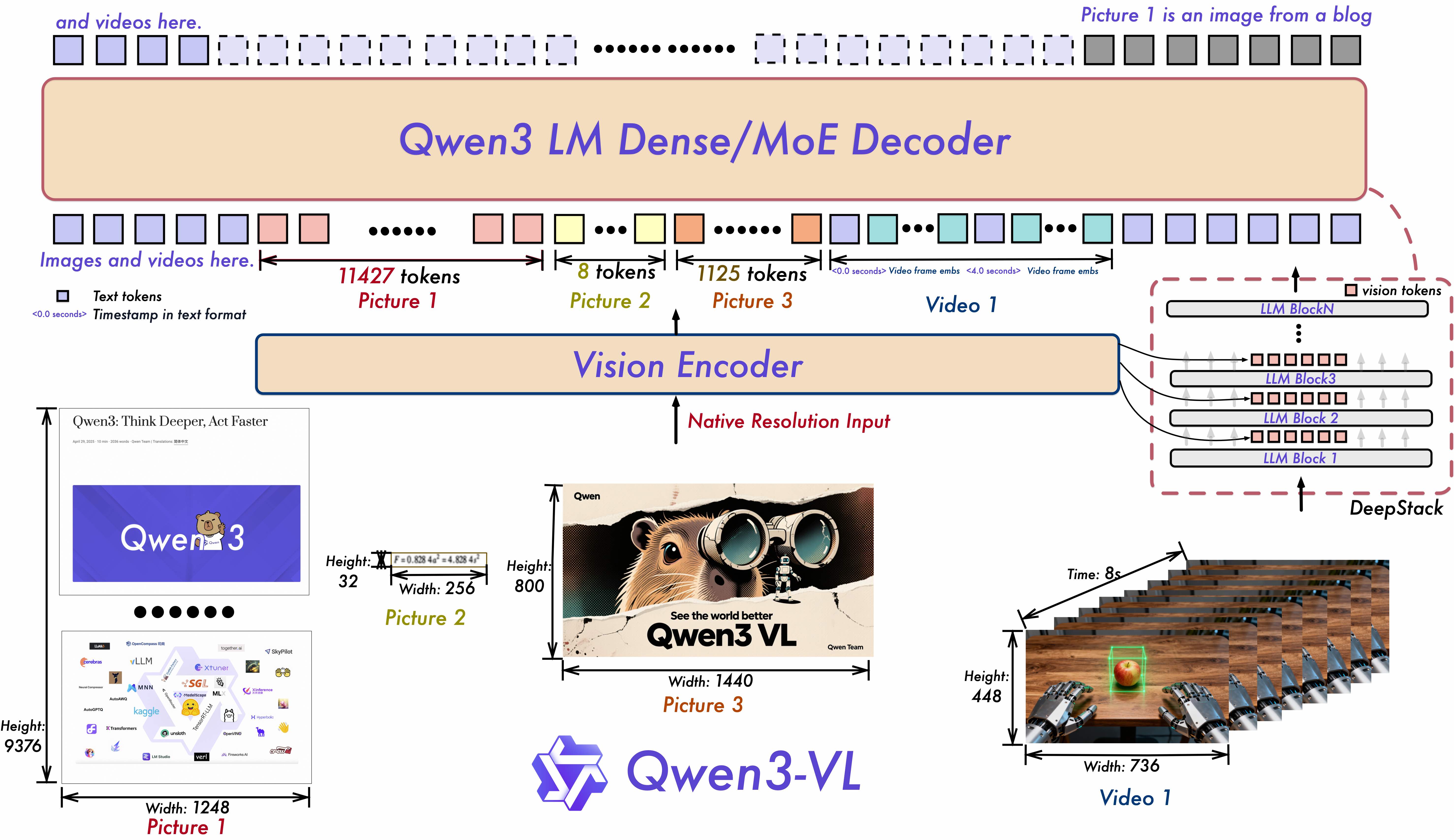
图1. Qwen3-VL模型结构(摘自Qwen3-VL论文)
2. 延迟优化技术
2.1 Qwen3-235B的延迟优化
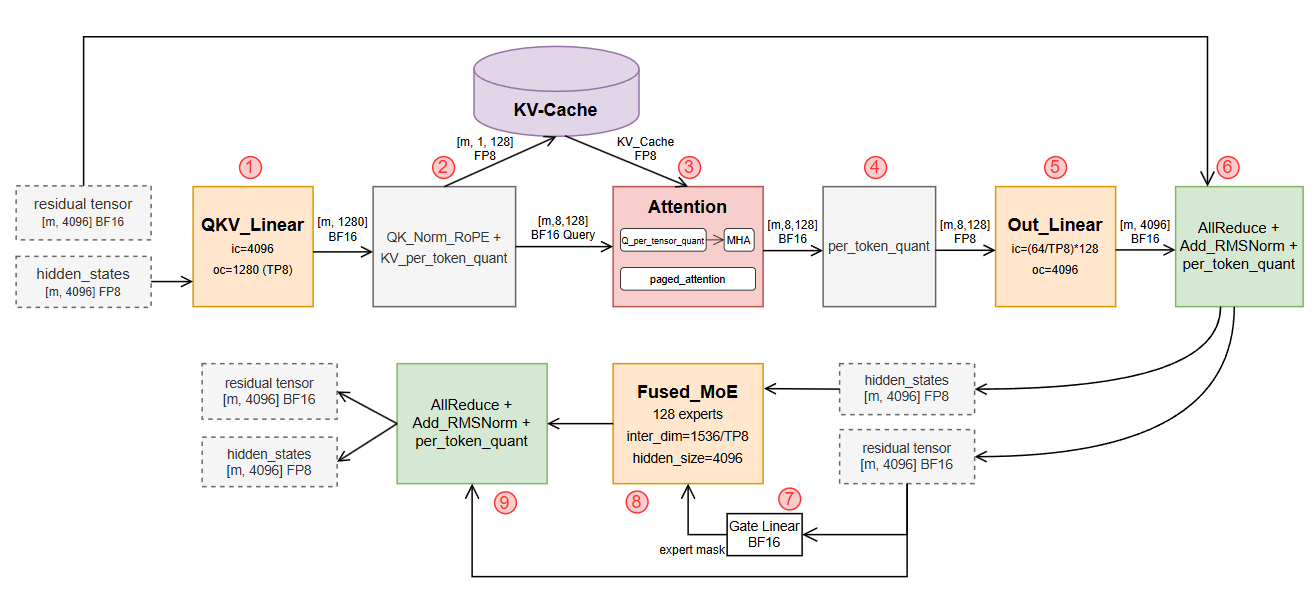
Qwen3-235B推理计算流程如图2所示。以下详述关键组件优化。
图2. Qwen3-235B模型推理计算流程图
2.1.1 GEMM量化策略
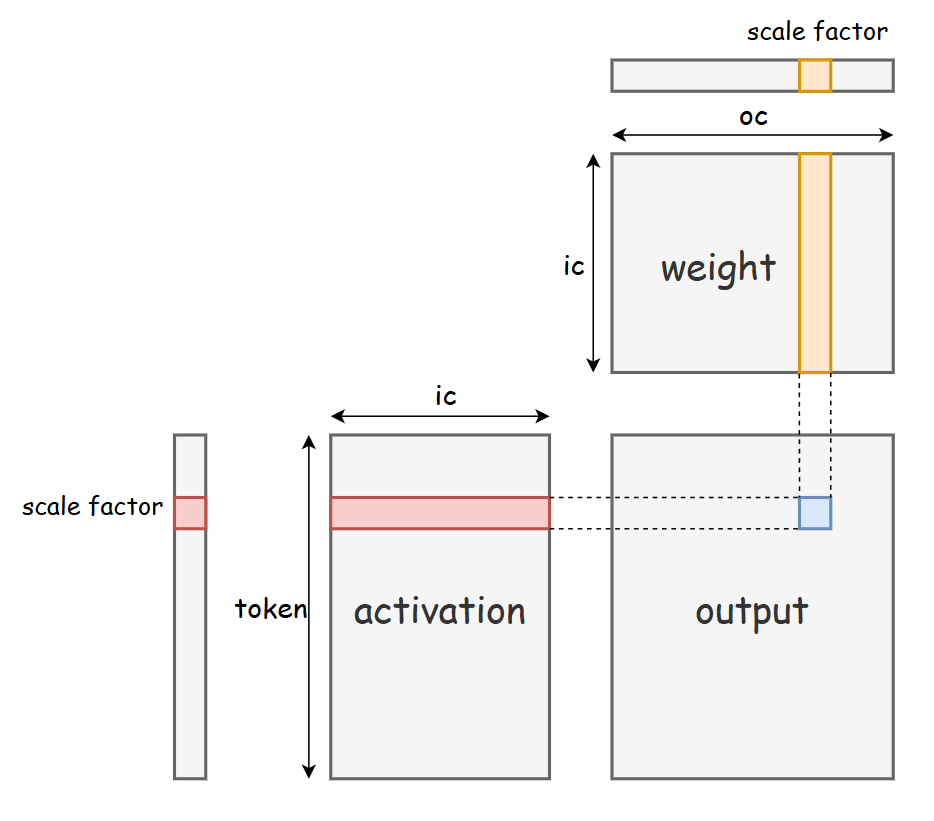
图3. PTPC-FP8:Per-Token激活、Per-Channel权重量化
量化是加速LLM推理的关键。本工作采用PTPC(Per Token Activation, Per Channel Weight)量化方案——一种同时应用于模型权重和激活的FP8量化方法,其核心原理如图3所示。该方案对激活采用per-token量化、对权重采用per-channel量化,相较传统per-tensor FP8量化,实现更高精度和更低信息损失。
与标准BlockScale FP8相比,PTPC保持相当精度同时提供更优计算效率。BlockScale固定块大小常与硬件GEMM单元最优tile大小错位,引入数据拆分重排开销;PTPC细粒设计消除固定块约束,自然对齐硬件GEMM原生计算粒度,其per-channel权重量化也匹配现代加速器通道并行架构。结合低精度计算吞吐提升,PTPC GEMM显著提高硬件利用率。
AMD ROCmTM平台实验显示,PTPC FP8 GEMM较BlockScale FP8提升15%–30%,小矩阵和错位矩阵场景下延迟降低更显著。
2.1.2 并行策略
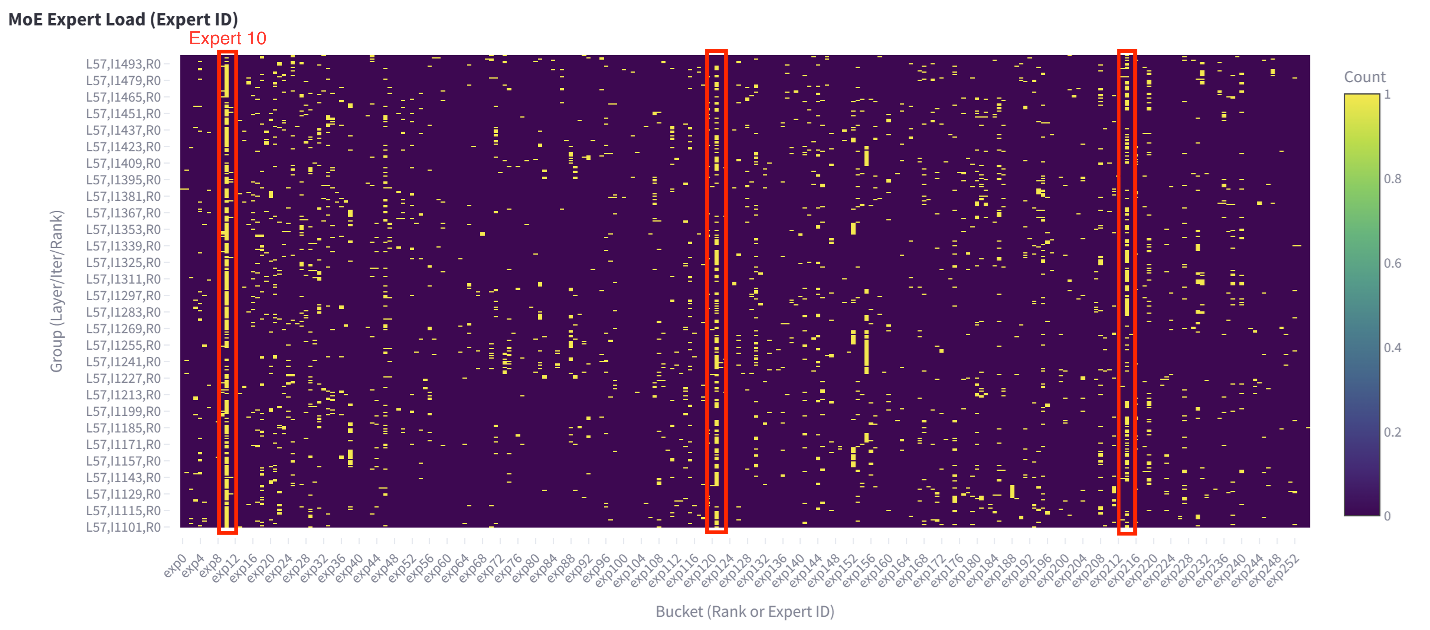
图4. 专家热点分布
在Qwen3-235B Expert Parallelism(EP)实验中,观察到某些数据集专家热点(如图4所示,例如层57,EP ranks 10/120/216频繁访问),导致负载不均衡和推理瓶颈。
Qwen生产场景中,TTFT和TPOT为关键指标。测试证实MoE模型推理通常内存绑定。MI300X高带宽HBM有效缓解Tensor Parallelism(TP)I/O瓶颈,大幅降低延迟。
针对完整Qwen3-235B(含MoE结构),采用TP8张量并行结合PTPC FP8量化实现极低延迟。具体而言,PTPC的192个独立缩放因子使MoE模块无缝兼容TP8,确保大规模并行稳定高效。
低并发极致延迟场景下,TP8将权重分布8张GPU,降低单卡加载和内存延迟;架构上缓解MoE专家负载不均,为超低延迟奠基。
2.1.3 Attention模块优化
(1) 优化的KV-Cache布局
Attention模块集成AMD AITER Library高性能MHA和PagedAttention算子,定制专用KV Cache布局:
- k_cache: [num_blocks, num_kv_heads, head_dim // x, block_size, x]
- v_cache: [num_blocks, num_kv_heads, block_size // X, head_dim, X]
该布局对齐AMD CDNATM 3内存访问模式,大幅提升PagedAttention内存效率。解码阶段无需额外D2D拷贝消除冗余开销(如图5)。相较标准[ num_blocks, num_kv_heads, head_dim, block_size ]布局,解码吞吐提升15%–20%,降低推理延迟。
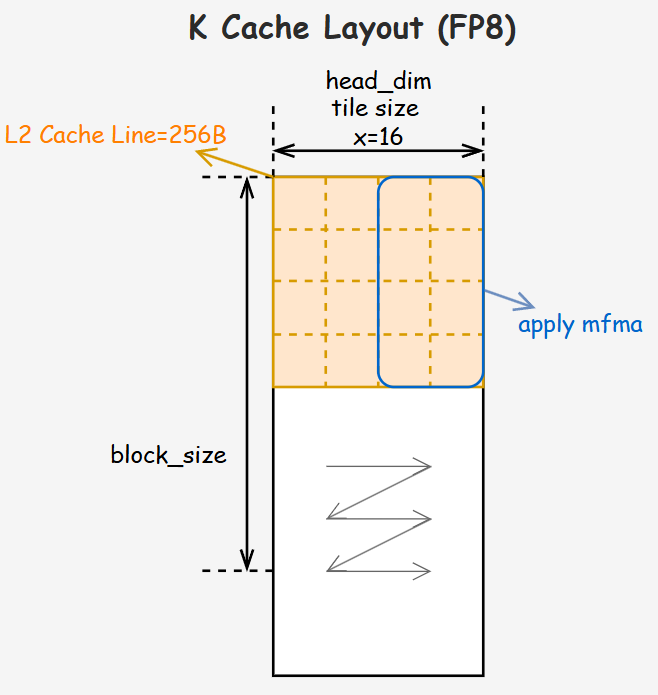
图5. K Cache布局分布
(2) 数据类型优化
- prefill阶段:query、key、value激活采用per-tensor FP8量化应用于MHA。
- decode阶段:query用BF16,KV Cache存per-tensor FP8(与prefill一致)。
混合精度配置降低HBM使用,同时保持精度和性能。
2.1.4 MoE优化
低并发负载下,AITER中MoE算子从四维度深度优化:
- 负载均衡:低并发推理中CU细粒任务调度,实现近同步执行,消除空闲周期,最大化硬件利用。
- 计算效率:K维度硬件感知循环调优,消除冗余操作,提升吞吐。
- 内存效率:优化原子内存访问,提升L2缓存命中率,缓解带宽瓶颈。
- 自动调优:手动优化后,自动工具搜索最优配置,进一步最大化性能。
负载均衡和细粒调度在LLM解码中获益显著,最终MoE模块性能提升2×。
2.1.5 内核融合优化

融合关键算子,包括:
- 模块2:QKNorm + RoPE
- 模块6 & 9:AllReduce + AddRMSNorm + per-token quant
融合减少频繁HBM访问,进一步降低端到端延迟。
| Fusion pattern | Before (us) | After (us) | Speedup Ratio |
|---|---|---|---|
| QKNorm + RoPE | 11.6 | 5.1 | 127% |
| AllReduce + AddRMSNorm + Quant | 35 | 21 | 67% |
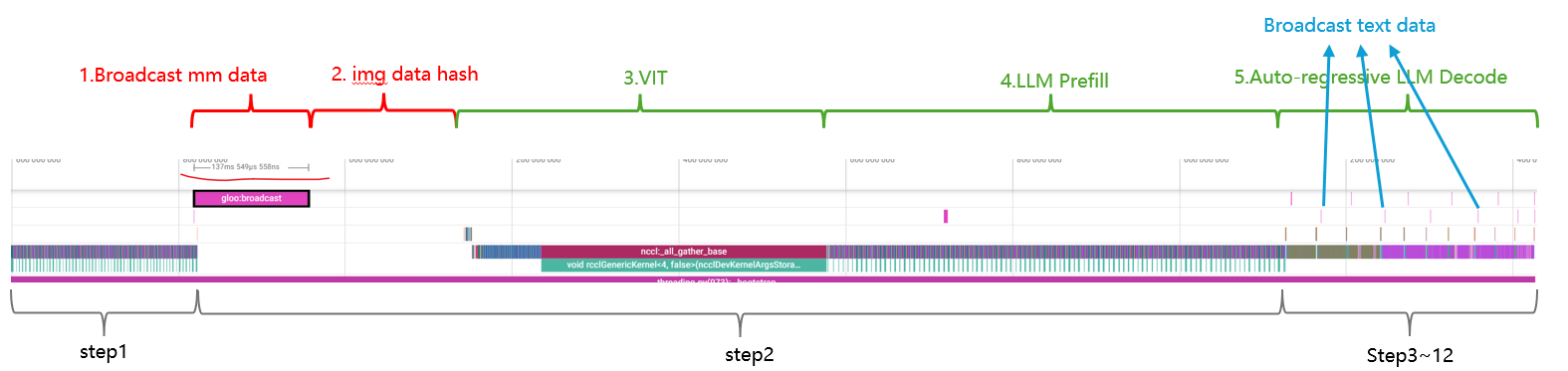
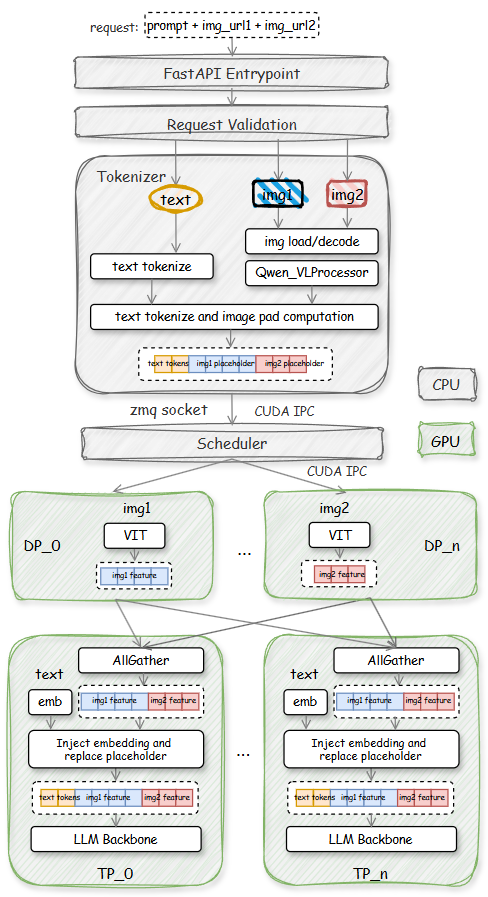
2.2 Qwen3-VL-235B优化
图6. SGLang中Qwen3-VL-235B部署
相较Qwen3-235B,Qwen3-VL-235B引入多模态数据适配、预处理、跨模态对齐、ViT编码器执行、视觉patch嵌入及跨模态特征融合等新推理阶段(如图6全流程)。这些扩展延长推理管线,涉及复杂跨模态协调,大幅增加单请求延迟。
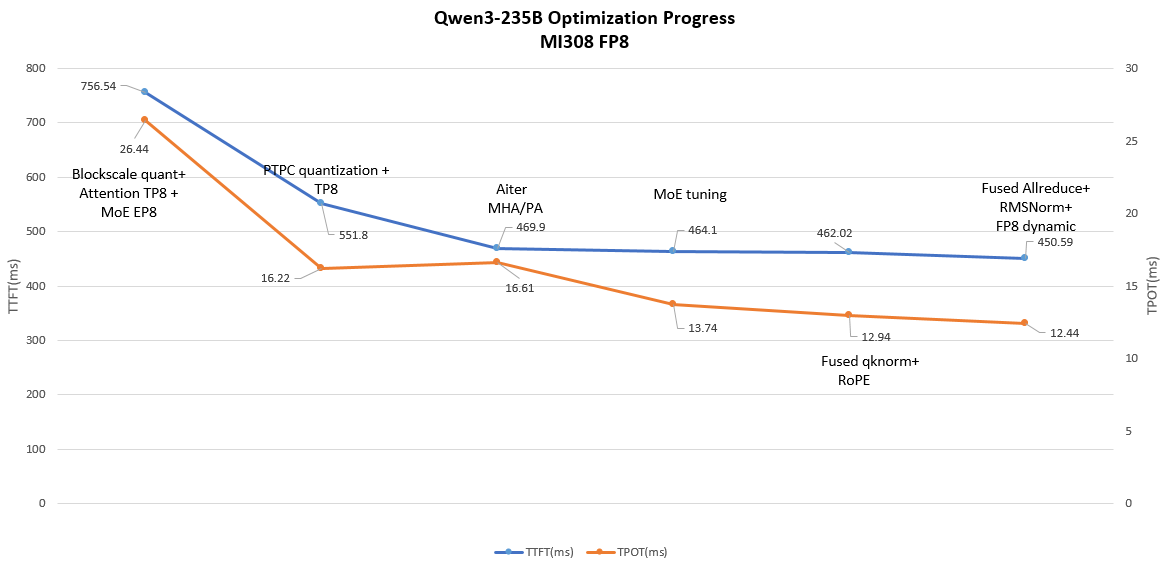
图7-10. 附加优化图示(MoE、融合等性能对比)
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接