关于NVIDIA DGX Spark有激动人心的更新!在正式发布一周内,我们与NVIDIA密切合作,成功在DGX Spark上为SGLang添加了对GPT-OSS 20B和GPT-OSS 120B的支持。成果令人印象深刻:GPT-OSS 20B约70 tokens/s,GPT-OSS 120B约50 tokens/s,这是目前的最先进水平,完全使在DGX Spark上运行local coding agent成为现实。
本文将指导你如何:
- 在DGX Spark上使用SGLang运行GPT-OSS 20B或120B
- 本地基准性能测试
- 连接Open WebUI进行聊天
- 通过LMRouter完全本地运行Claude Code
1. 准备环境
启动SGLang前,确保安装正确的tiktoken encodings以支持OpenAI Harmony:
mkdir -p ~/tiktoken_encodings
wget -O ~/tiktoken_encodings/o200k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
wget -O ~/tiktoken_encodings/cl100k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"2. 使用Docker启动SGLang
使用以下命令启动SGLang服务器:
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface -v ~/tiktoken_encodings:/tiktoken_encodings \
--env "HF_TOKEN=<secret>" --env "TIKTOKEN_ENCODINGS_BASE=/tiktoken_encodings" \
--ipc=host \
lmsysorg/sglang:spark \
python3 -m sglang.launch_server --model-path openai/gpt-oss-20b --host 0.0.0.0 --port 30000 --reasoning-parser gpt-oss --tool-call-parser gpt-oss将<secret>替换为你的Hugging Face访问令牌。若运行GPT-OSS 120B,只需将模型路径改为openai/gpt-oss-120b(该模型约为20B版本的6倍大,加载时间稍长)。为获得最佳性能和稳定性,建议在DGX Spark上启用swap memory。
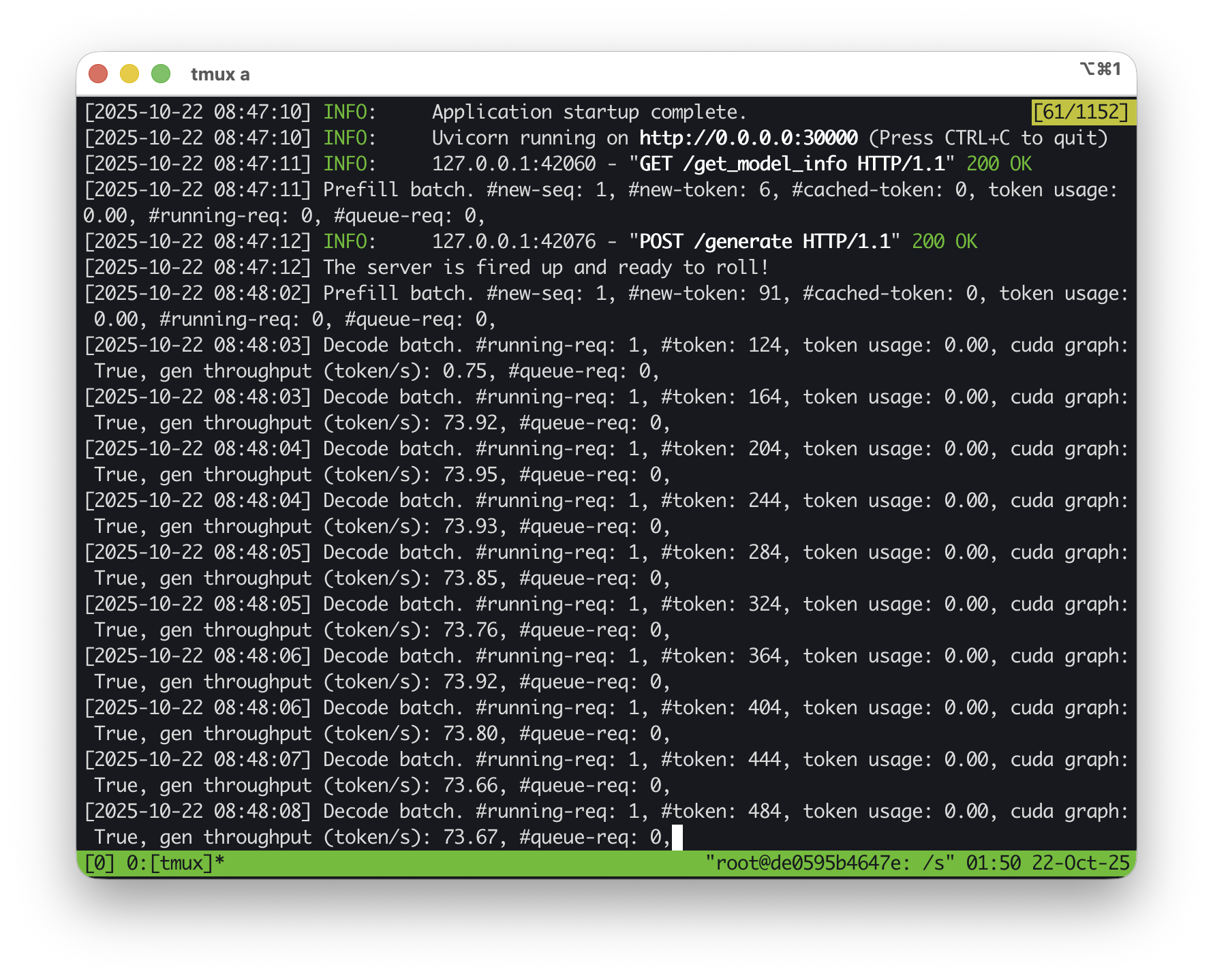
3. 测试服务器
SGLang运行后,可直接发送OpenAI兼容请求测试:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many letters are there in the word SGLang?"
}
]
}'
4. 性能基准测试
快速基准吞吐量的方法是请求长输出,例如:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Generate a long story. The only requirement is long."
}
]
}'在典型条件下,GPT-OSS 20B应达到约70 tokens/s。
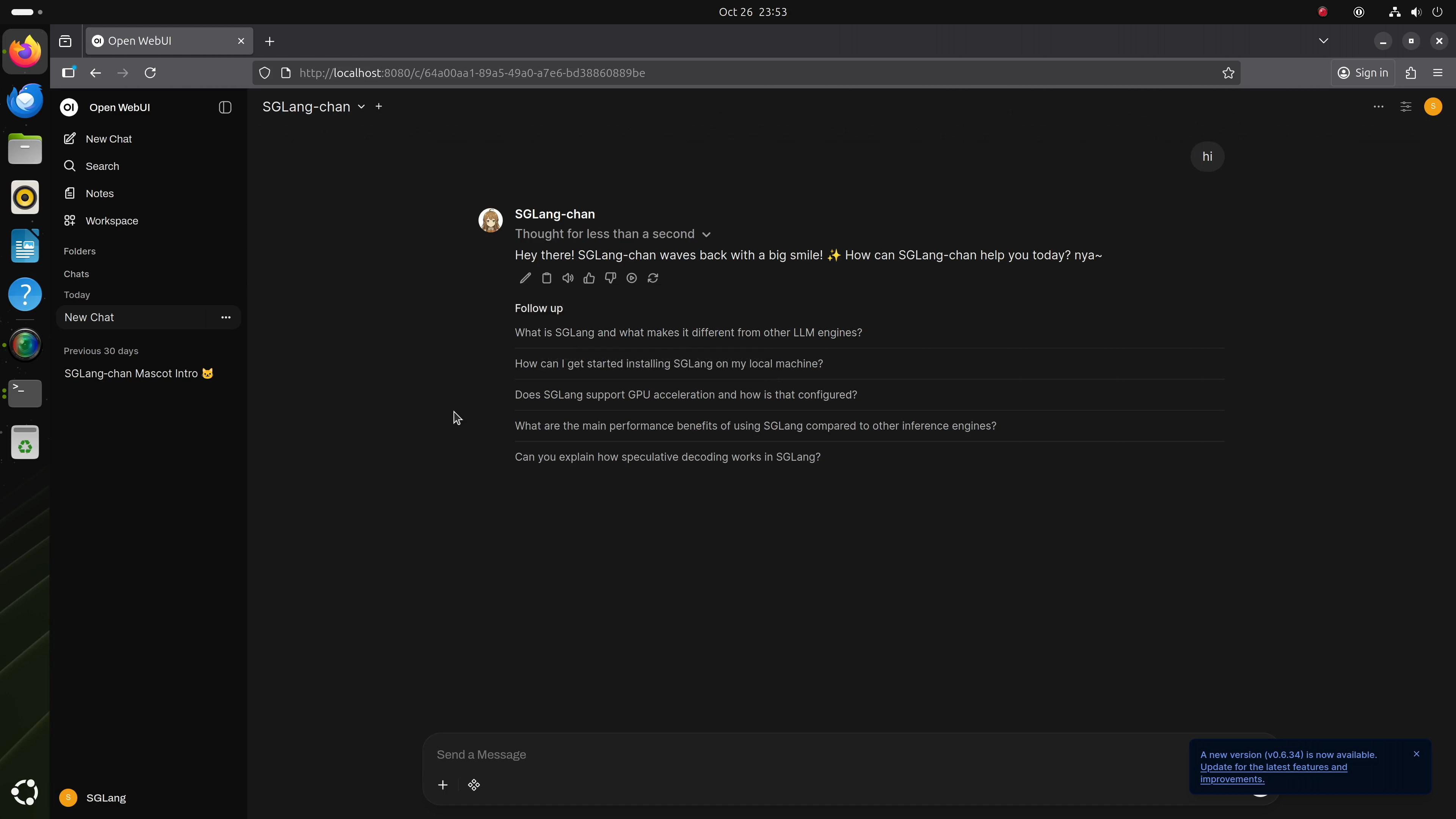
5. 运行本地聊天机器人(Open WebUI)
为设置友好本地聊天界面,可在DGX Spark上安装Open WebUI,并指向运行中的SGLang后端:http://localhost:30000/v1。遵循Open WebUI安装指南即可启动。连接后,即可无缝与本地GPT-OSS实例聊天,无需互联网。
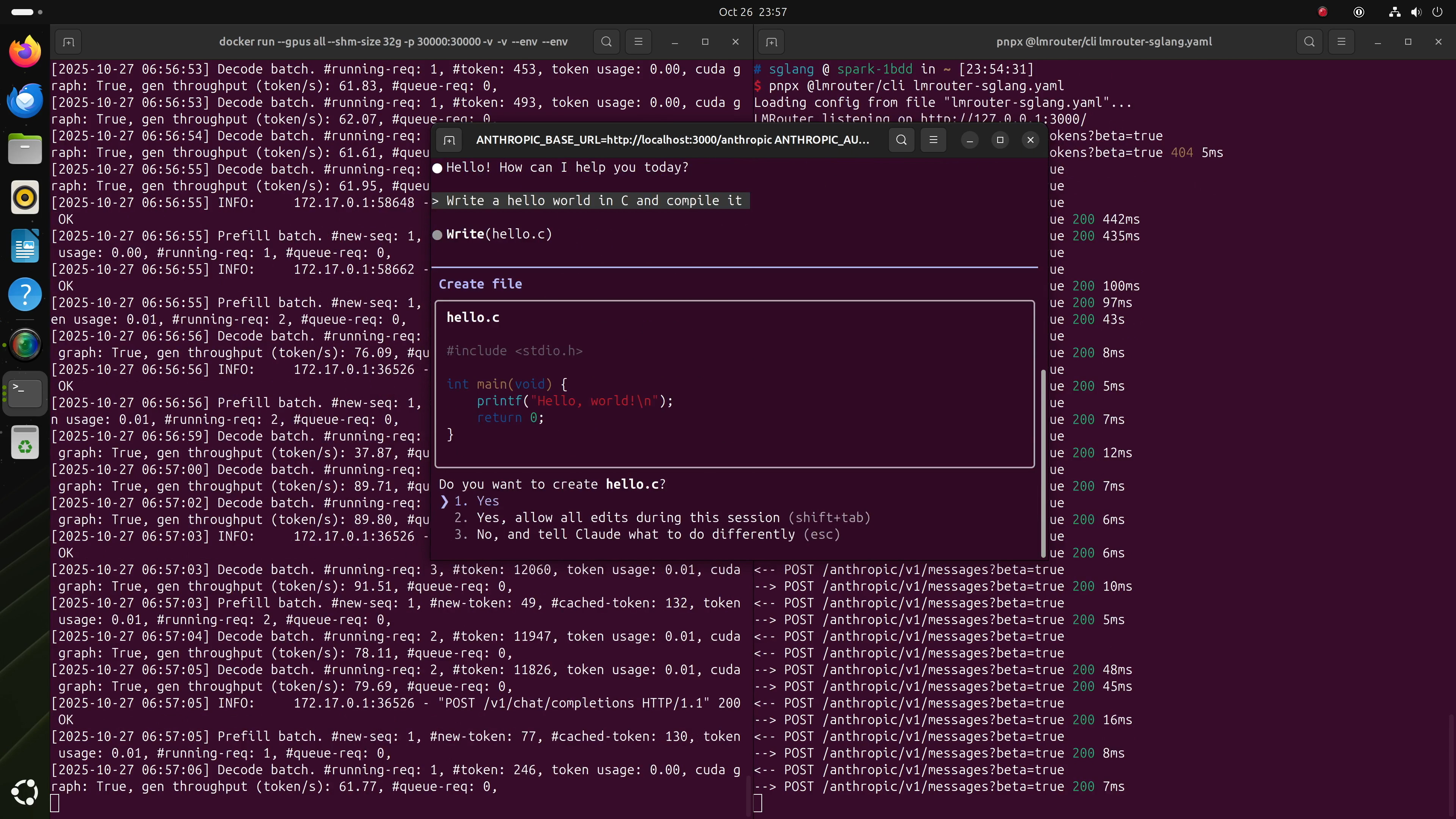
6. 完全本地运行Claude Code
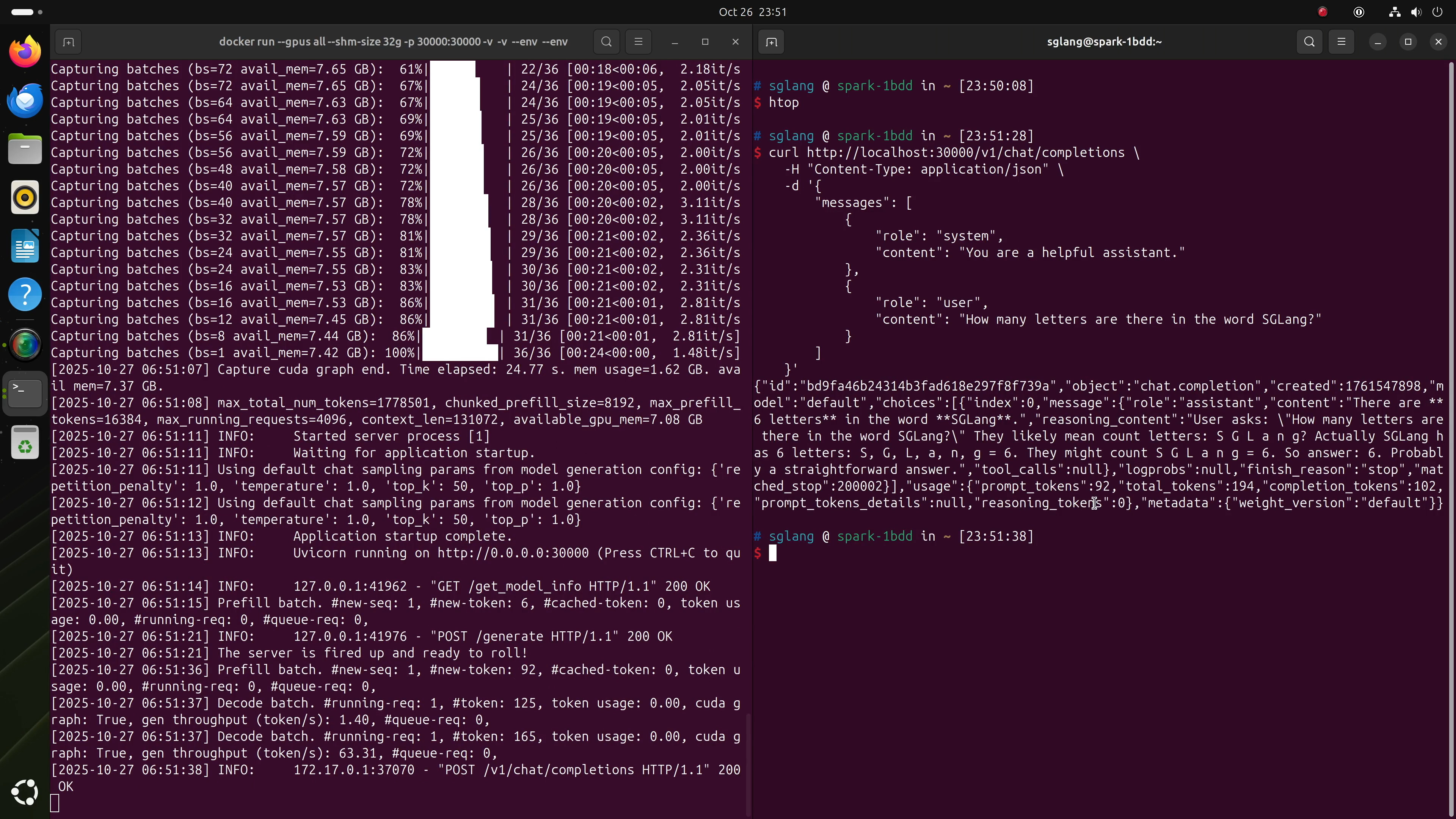
借助本地GPT-OSS模型,你甚至可通过LMRouter连接Claude Code,后者能将Anthropic风格请求转换为OpenAI兼容格式。
步骤1:创建LMRouter配置
将此文件保存为lmrouter-sglang.yaml。
步骤2:启动LMRouter
若未安装,安装pnpm,然后运行:
pnpx @lmrouter/cli lmrouter-sglang.yaml步骤3:启动Claude Code
按照Claude Code设置指南安装,然后按以下方式启动:
ANTHROPIC_BASE_URL=http://localhost:3000/anthropic \
ANTHROPIC_AUTH_TOKEN=sk-sglang claude就是这样!你现在可以使用Claude Code,完全由DGX Spark上的GPT-OSS 20B或120B驱动。
7. 结论
通过这些步骤,你能充分释放DGX Spark潜力,将其转变为可交互运行数十亿参数多模态模型的本地AI powerhouse。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接