SGLang 与 AMD 团队紧密协作,在 AMD Instinct™ MI355X GPU 上实现了大规模 DeepSeek-R1 分离式推理的竞争性总体拥有成本(TCO)。借助 SGLang 服务框架与 AMD MoRI 通信库,AMD 在关键运行点上达到甚至超越 NVIDIA B200(Dynamo + TRT-LLM)的 TCO 表现,结果已通过 SemiAnalysis 的 InferenceX 平台验证。
核心结果一览
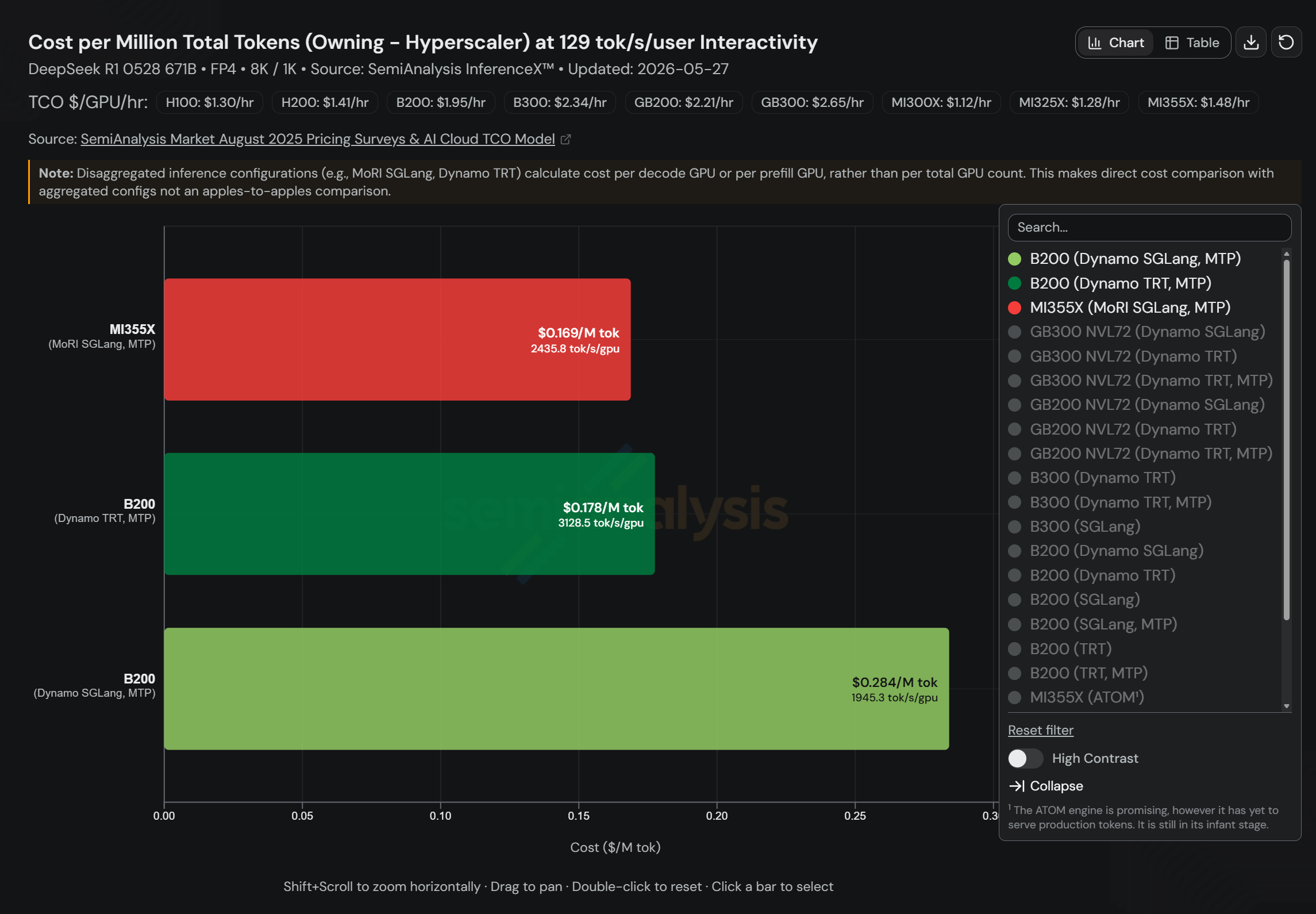
在典型生产级编码助手与交互式聊天机器人场景(129 tok/s/user 交互性)下:
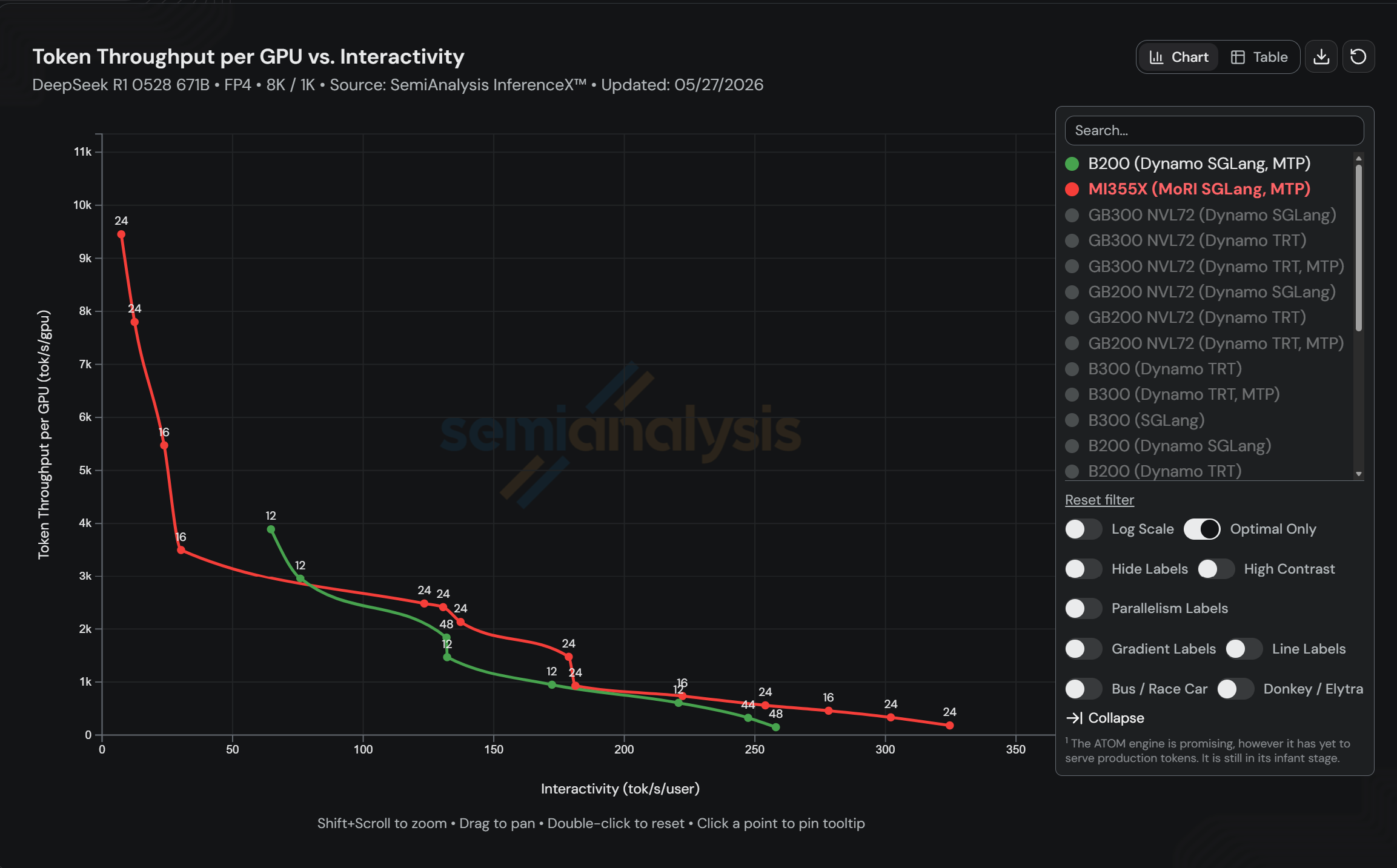
- AMD Instinct™ MI355X(MoRI SGLang MTP):每百万 token 成本 0.169 美元,每 GPU 吞吐 2436 tok/s(24 张 GPU)
- NVIDIA B200(Dynamo TRT-LLM MTP):每百万 token 成本 0.178 美元
- NVIDIA B200(Dynamo SGLang MTP):每百万 token 成本 0.284 美元
MI355X 成本分别比 B200 TRT-LLM 低 5%、比 B200 SGLang 低 40%,同时每 GPU 吞吐高出 B200 SGLang 1.25 倍。
关键优化技术
MoRI 量化 All-to-All
通过 FP4 dispatch + FP8 combine 混合量化,实现 2.56 倍带宽缩减,同时保持精度。Blockwise 量化与自适应内核选择进一步降低延迟。

MoRI-IO KV 缓存后端
支持无锁内联传输与多架构状态迁移,吞吐比 Mooncake 高约 10%。
Two-Batch Overlap 与 SDMA
通过双微批次流水线隐藏通信延迟,SDMA 实现零计算开销数据移动,显著提升整体吞吐。

© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接