
TL;DR
作为Blackwell家族最新成员,GB300 NVL72 是长上下文LLM推理的最强平台。本文分享优化DeepSeek R1-NVFP4在128K/8K ISL/OSL(Input Sequence Length/Output Sequence Length)长上下文服务上的最新进展,采用prefill–decode disaggregation (PD)、chunked pipeline parallelism (PP)预填充、wide expert parallelism (Wide-EP)解码、multi-token prediction (MTP)、overlap scheduling,以及得益于注意力softmax关键指令2x Special Function Unit (SFU)吞吐量提升的更快注意力内核。
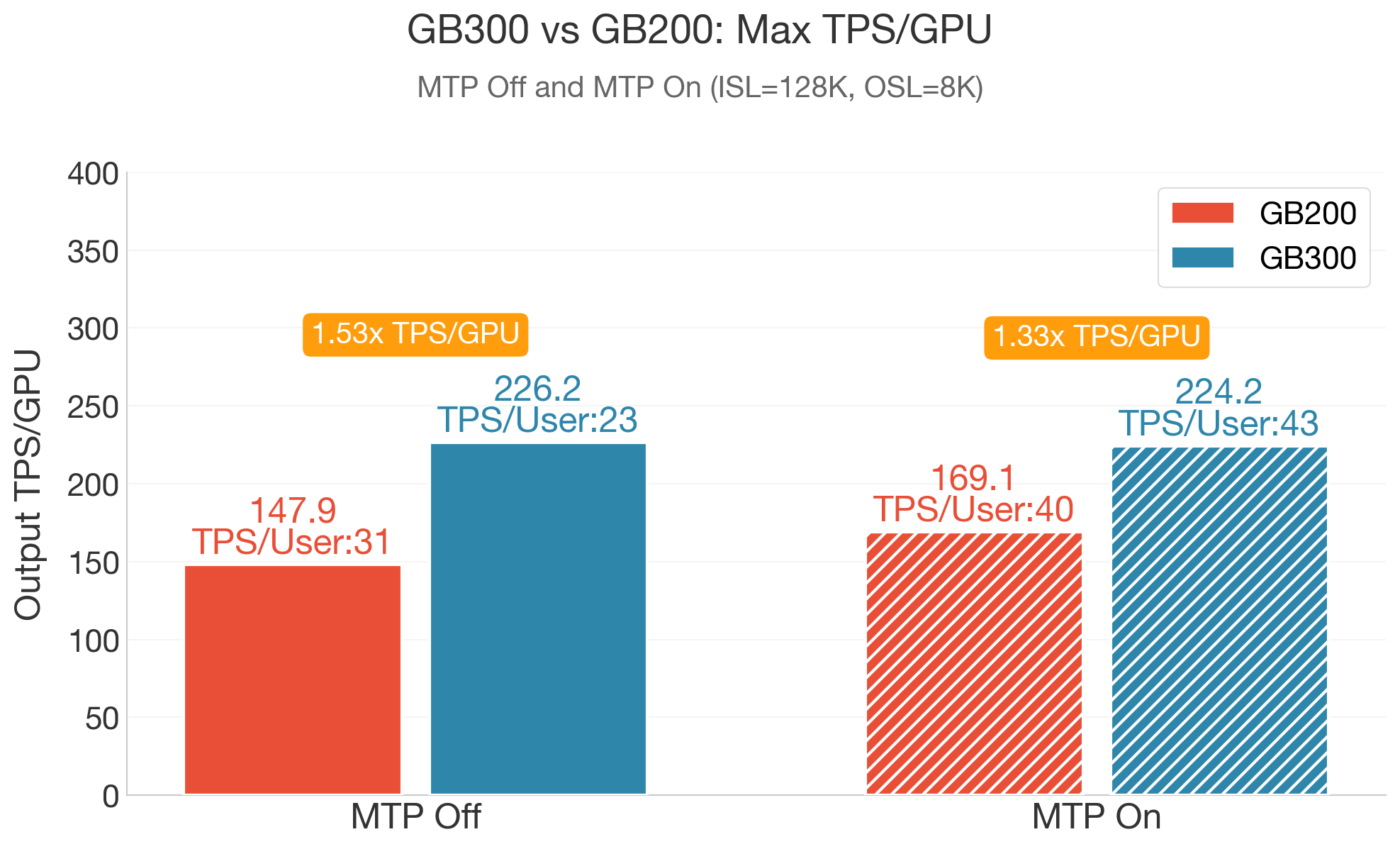
在长上下文负载下,SGLang在GB300 NVL72上实现最高226 TPS/GPU(1.53X 优于GB200),在近似相同GPU吞吐量下,MTP进一步实现1.87X 用户吞吐量(TPS/User)提升。此外,在相同延迟条件下与匹配的GB200 NVL72配置相比,GB300在典型场景中持续提供1.4X–1.6X TPS/GPU。
复现指南详见issue:18703。
亮点
- 长上下文(128K/8K)峰值吞吐量:SGLang在GB300 NVL72上实现226.2 TPS/GPU,较GB200优势1.53X;同等吞吐量下,MTP驱动1.87X TPS/User。
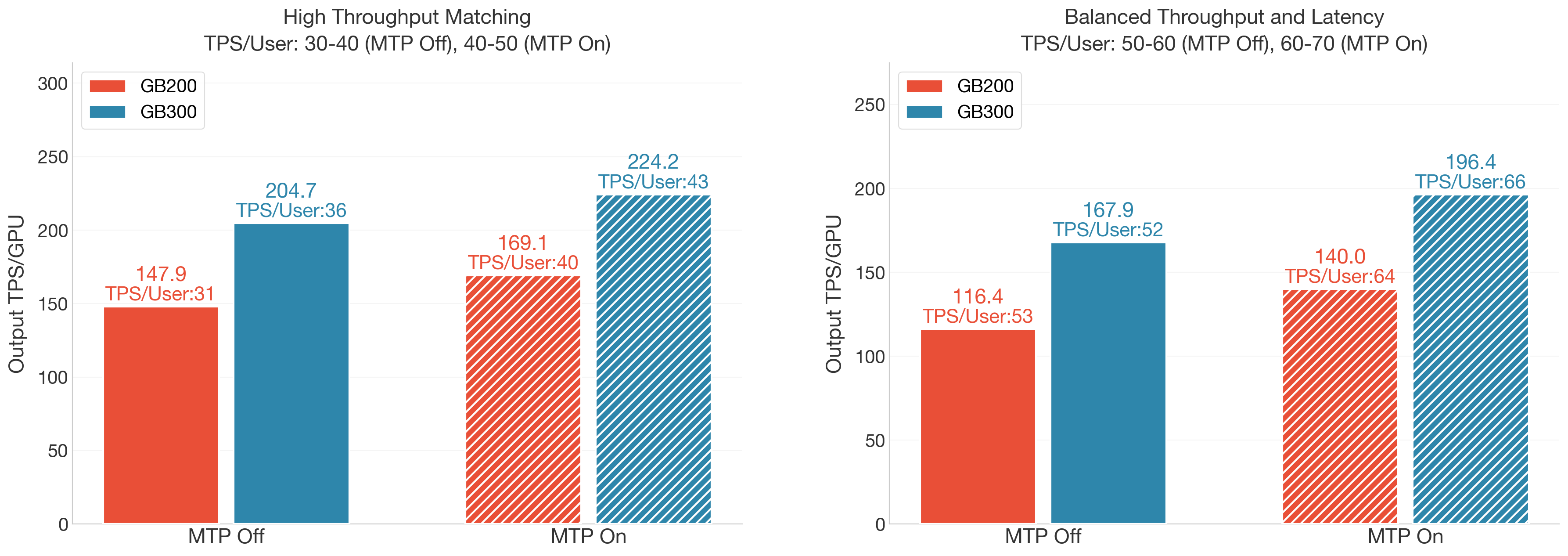
- 同等延迟条件下GB300 vs GB200:GB300在匹配负载下提供1.38X-1.58X TPS/GPU。
- EP解码扩展:GB300的1.5X更大HBM(288 vs 192 GB)支持1.6X更高有效解码批次大小(40 vs 24 req/GPU),DEP8时扩展至288并发请求,几乎无回撤。
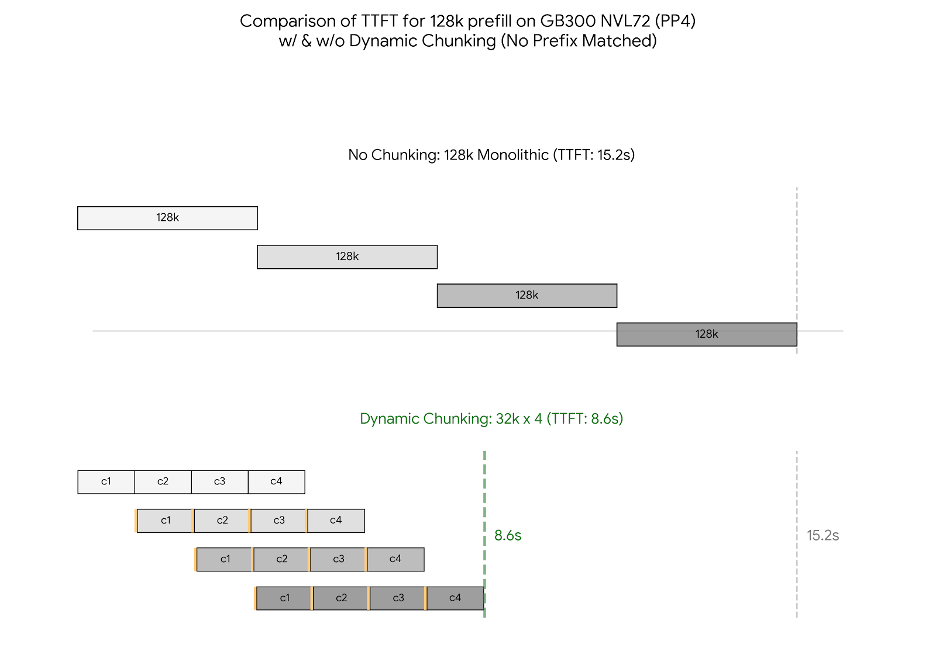
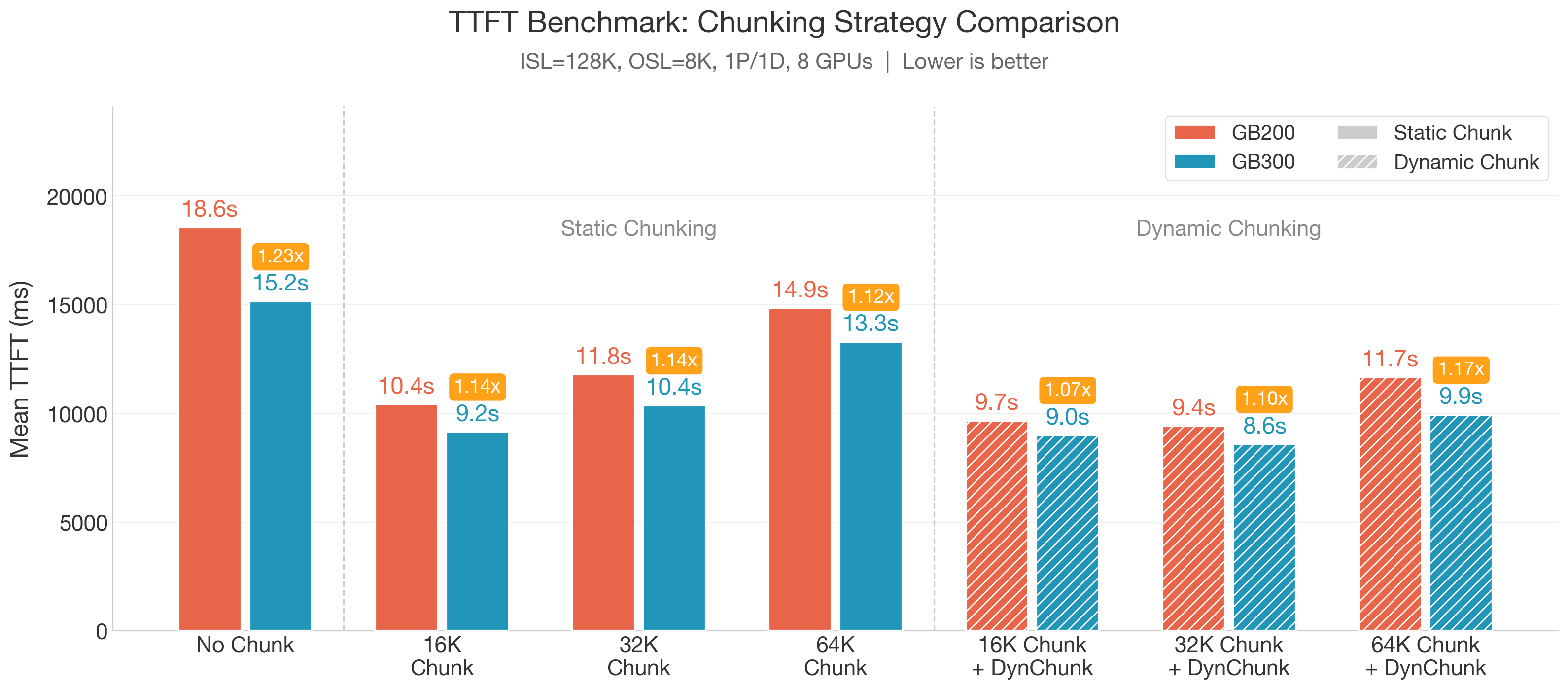
- PP预填充与优化注意力内核:128K预填充TTFT仅8.6s(动态分块,较GB200低1.07X–1.23X),得益于注意力softmax关键指令2x SFU吞吐量提升的1.35X更快FMHA内核。
方法
本节介绍实现GB300长上下文性能提升的主要技术。
1. 与NVIDIA Dynamo的部署与集成
本文中,DeepSeek-R1在GB300 NVL72上的部署使用NVIDIA Dynamo(GitHub)协调,这是一个集群规模prefill–decode (PD)分离推理的高性能控制平面。Dynamo处理异构预填充和解码工作池协调的复杂性,提供KV-cache感知路由、工作协调、生命周期管理和优化的前后处理栈,以维持超高吞吐量。
- 低开销编排:Dynamo的核心优势在于轻量KV-cache感知请求引导和高效元数据管理。在PD协调频繁的长上下文场景中,Dynamo确保调度层引入近零延迟,让SGLang优化内核饱和GB300的HBM3e带宽,而不受编排逻辑瓶颈。
- 生产级扩展:Dynamo为多节点PD部署提供稳健协调,包括动态工作发现、健康跟踪和异构预填充/解码池生命周期管理,确保部署在实例扩展、滚动或重启时保持稳定。
欲在生产环境中部署这些配方,Dynamo Kubernetes栈支持GB200/GB300,具备推理感知自动扩展和集群拓扑感知调度。
2. 预填充路径:PP预填充、长上下文TTFT与更快内核
对于长上下文推理(如128K tokens),TTFT是主要约束,尤其在无前缀匹配时,提升TTFT至关重要。我们采用Chunked Pipeline Parallelism (PP)结合Dynamic Chunking,分布提示计算并改善管道阶段重叠。
基于GB200系列优化,我们全面启用FP8 Attention并引入原生FP8 KV-cache支持(预填充和解码)。关键优势:
- 减少内存流量:相较BF16最小化内存带宽瓶颈,提升吞吐量和稳定性。
- 双倍KV容量:在固定内存中双倍KV-cache容量,支持更大批次或更长序列。
我们还利用GB300专属硬件加速Softmax注意力内核。Blackwell Ultra GPU升级Special Function Unit (SFU),为注意力softmax关键操作提供2x加速吞吐量。对于注意力密集的长上下文预填充,这直接减少计算瓶颈。基准显示,该升级使FMHA内核较GB200加速1.35X,降低整体TTFT。
3. 解码路径:长上下文推理中的内存瓶颈
长上下文解码迅速转为KV主导和内存绑定:每个新token反复读取完整KV历史,因此KV容量(驻留序列数)和HBM带宽成为首要瓶颈。
SGLang采用专用运行时栈和架构策略:
- Wide-EP扩展:EP(Expert Parallelism)结合DP attention将MoE权重和KV cache分布至更多GPU(本工作最多32个),降低每GPU内存压力,支持更大解码批次而无“retraction”(重计算)。
- CuTe DSL nvfp4内核:针对解码期高性能nvfp4 MoE操作定制。
- DeepEP:优化分发和合并内核,实现高效all-to-all通信。
GB300(Blackwell Ultra)每GPU 288 GB HBM3e——GB200的1.5X。以DEP16为例评估最大解码并发,固定mem_fraction_static=0.75公平比较(GB300实际可更高)。按每token KV足迹(35,136 Bytes)和128K+8K负载(~136K缓存token/请求)计算。
SGLang中,mem_fraction_static定义分配给模型权重和KV cache的GPU内存比例,其余留给激活和运行时缓冲。KV足迹计算:(kv_lora_rank + qk_rope_head_dim) × num_layers × num_kv_head * fp8_size = (512 + 64) × 61 × 1 × 1 = 35,136 Bytes/token。| 项目 | 假设/指标 | GB300 (@ mfs=0.75) | GB200 (@ mfs=0.75) |
|---|---|---|---|
| HBM per GPU | HBM3e总容量 | 288 GB | 192 GB |
| Static budget | HBM × mem_fraction_static | ≈ 216 GB | ≈ 144 GB |
| Model weights per GPU | FP4量化DeepSeek-R1, EP16/TP16 | ≈ 40 GB | ≈ 40 GB |
| KV pool budget | Static budget – Model weights | ≈ 176 GB | ≈ 104 GB |
| Workload | 每请求缓存token | 136K (128K+8K) | 136K (128K+8K) |
| KV footprint | 每token cell_size | 35,136 B | 35,136 B |
| KV per req per GPU | 136K × cell_size | ≈ 4.45 GiB | ≈ 4.45 GiB |
| Theoretical cap | KV pool / KV per req | ≈ 40 req/GPU | ≈ 24 req/GPU |
| Practical target | ~85% of cap减少回撤 | ≈ 36 req/GPU | ≈ 20 req/GPU |
| EP16 mapping | req/GPU × 16 GPUs | ≈ 576并发请求 | ≈ 320并发请求 |
表格显示,GB300更大HBM几乎直接转化为更高解码并发——理论上限40 vs 24 req/GPU。实际运行~85%上限避免KV cache全占触发回撤,GB300达36 req/GPU(576并发),GB200为20(320并发)。
4. 由Overlap Scheduler驱动的MTP
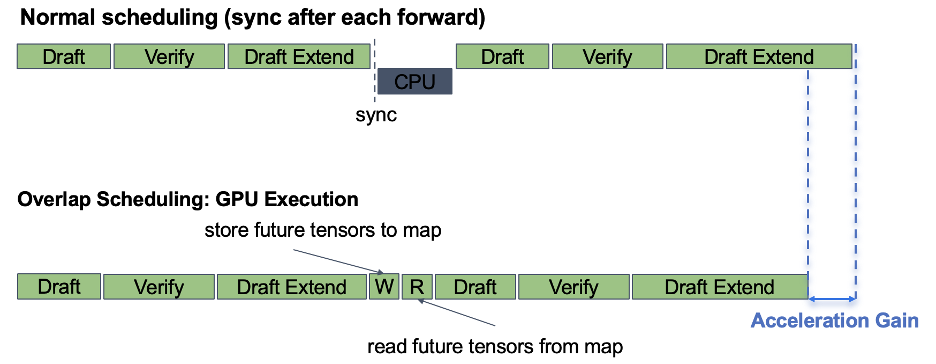
自v0.4起,overlap scheduler成为SGLang默认批调度策略,通过CPU调度与GPU计算重叠实现零CPU开销。同时,Multi-token Prediction (MTP)是最受欢迎的推测解码方法之一,被DeepSeek R1等主流模型广泛采用。SGLang中MTP实现详情见此博客。


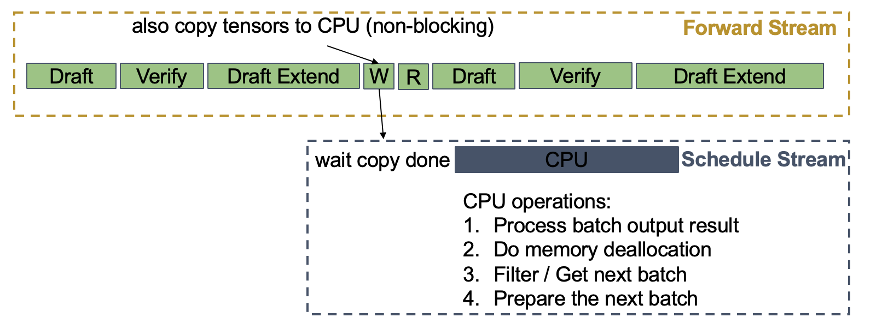
为无缝结合MTP和overlap scheduler,SGLang提出Spec-V2,通过精细消息传递和重叠策略缓解MTP批次同步。具体而言,Spec-V2采用双流设计:前向流处理所有GPU计算,调度流(强调异步性)处理CPU操作,包括结果处理、内存释放、下批准备等。
为避免设备到主机元数据张量传输引起的同步屏障,Spec-V2创建future tensor map:调度流先创建元数据张量引用,直至最后一批实现才读取,从而CPU操作可重叠。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接