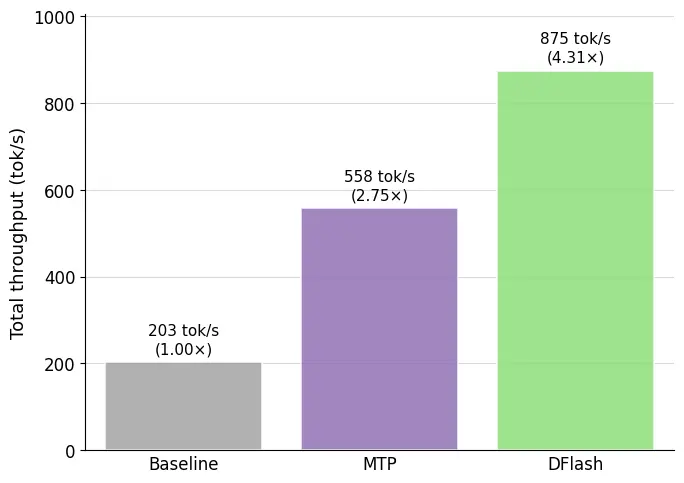
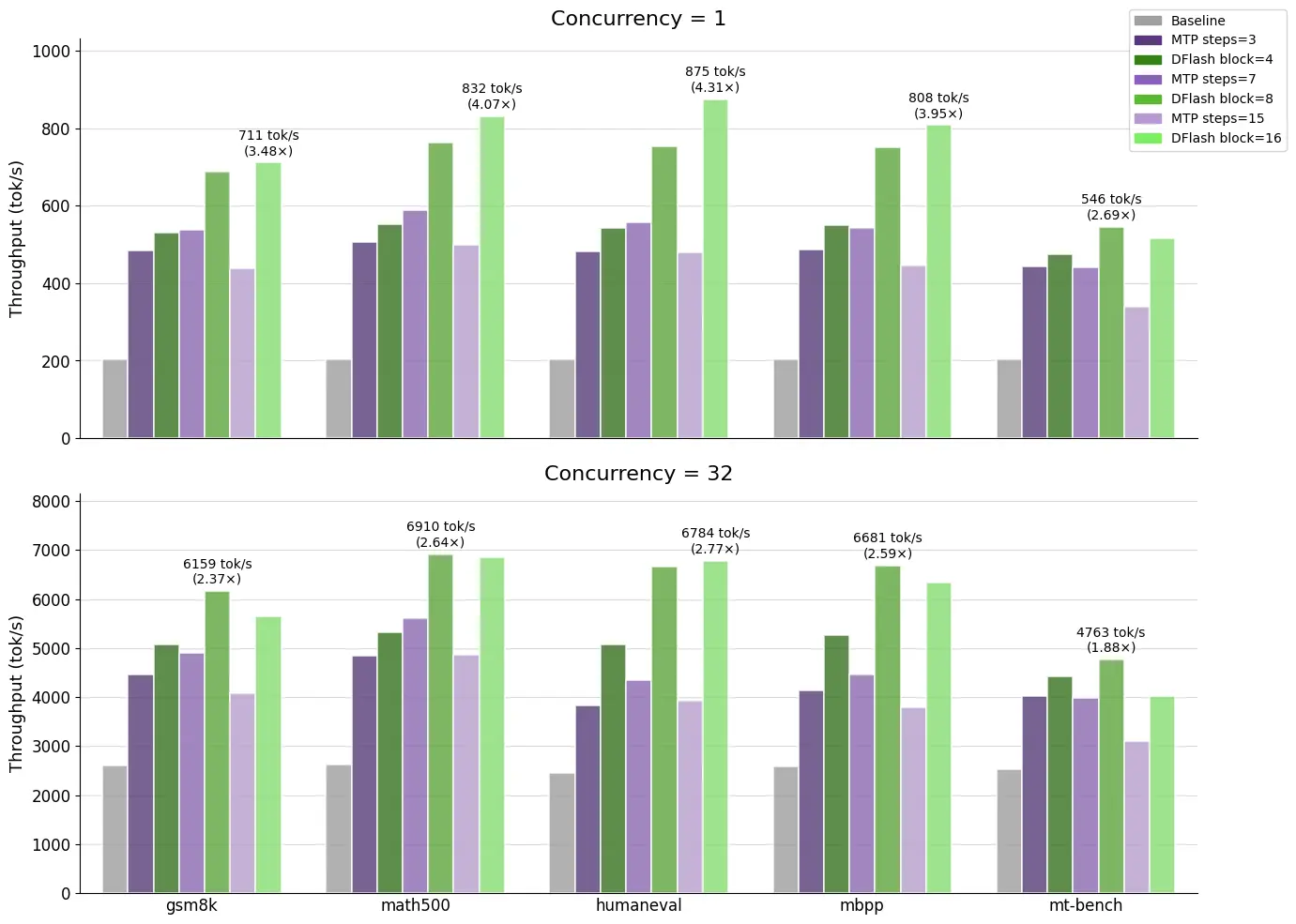
Modal、Z Lab与SGLang团队联合推出DFlash推测解码模型,搭配SGLang全新默认Spec V2引擎,可实现LLM推理服务的最优延迟。新发布的Qwen 3.5 397B-A17B专用DFlash模型在全部基准测试中,吞吐量均超越基线模型与原生MTP。
在HumanEval编码数据集、并发1、贪婪解码设置下,其吞吐量达到基线的4.3倍以上、MTP的1.5倍。
三平台同步开源模型
为庆祝此次合作,模型已在Hugging Face三家组织同步发布:z-lab/Qwen3.5-397B-A17B-DFlash、modal-labs/Qwen3.5-397B-A17B-DFlash及lmsys/Qwen3.5-397B-A17B-DFlash。
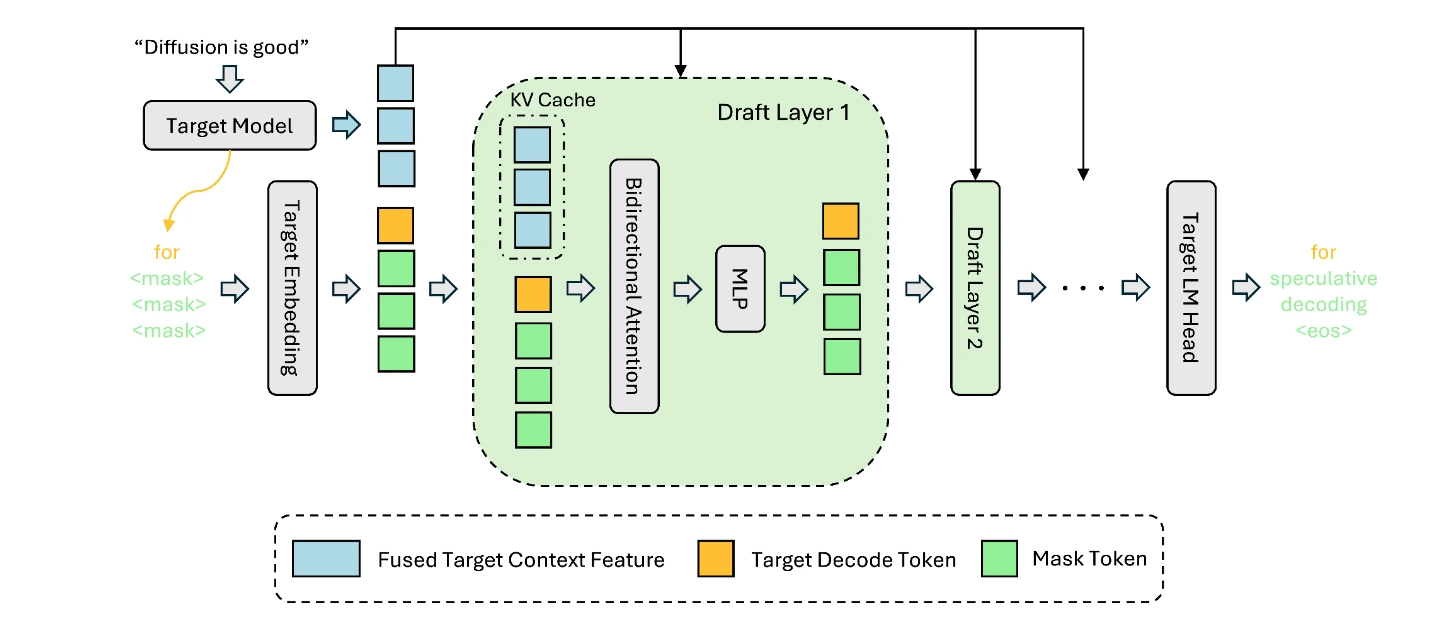
DFlash核心技术:块扩散+KV注入
传统自回归解码效率低下,推测解码通过小草稿模型并行提出多个token再由目标模型验证,可在不损失质量的前提下大幅加速。但EAGLE系列与原生MTP仍依赖顺序生成,限制了加速上限。
Z Lab开发的DFlash采用轻量块扩散草稿模型,可一次性并行生成整块token,完美匹配GPU/TPU特性。关键创新在于将目标模型的隐藏表示直接注入草稿模型KV缓存,使草稿模型无需从头建模上下文,专注预测下一token块。
DFlash为何更快?
加速效果取决于接受长度与草稿开销。DFlash同时优化两者:扩散草稿降低成本,KV注入提升接受长度。5层DFlash在GSM8K、HumanEval、MT-Bench上均显著超越EAGLE-3。
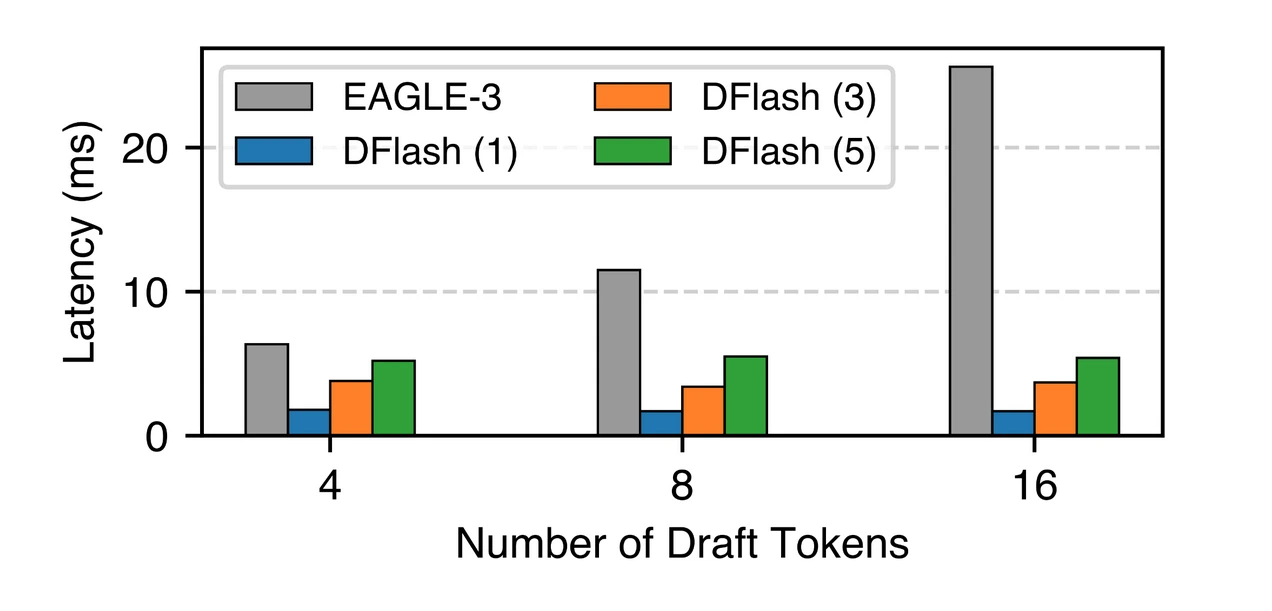
SGLang Spec V2集成
SGLang团队将DFlash从研究原型优化至生产级引擎,先集成至V1引擎实现KV缓存共享,再迁移至V2引擎,通过减少主机同步进一步提升性能。用户可通过指定参数一键启动高性能服务。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接