Introduction
The MLPerf Inference benchmark has evolved into an industry standard for measuring artificial intelligence (AI) infrastructure performance, achieving this status through a fair benchmark platform and diverse workloads such as vision, speech, and natural language processing. MLCommons is committed to keeping pace with the latest AI workloads, not only introducing new generative AI models but also upgrading traditional workloads. The YOLO task force was established to upgrade the RetinaNet benchmark in the Edge suite to Ultralytics YOLO11, a more modern state-of-the-art detection model.
RetinaNet has served as a reliable academic benchmark for single-stage detection for years, but there are strong reasons to upgrade to a more modern YOLO (You Only Look Once) variant. YOLO has developed rapidly in both research and practical applications, becoming one of the most effective and closely watched models in modern object detection workloads, driven by accelerated innovation, frequent releases, and strong community support. YOLO11, released by Ultralytics in September 2024, introduces significant architectural and training improvements, achieving higher accuracy with fewer parameters and offering variants from YOLO11n (nano) to YOLO11x (extra large), supporting diverse compute-accuracy trade-offs. In contrast, RetinaNet has seen fewer updates in recent years, with weakened development momentum and declining community adoption. The YOLO family continues to evolve rapidly, reflecting cutting-edge progress and mainstream trends in the AI industry’s object detection domain.
Model Selection
Before YOLO, state-of-the-art detectors were mostly "two-stage" systems that first proposed regions of interest and then classified them. The YOLO model was first proposed by Joseph Redmon and others at the University of Washington in 2015, treating object detection as a single regression problem—predicting bounding boxes and class probabilities simultaneously in a single pass, whereas previous methods like R-CNN required thousands of independent passes per image. This "single-shot" approach sacrificed a small amount of accuracy for a huge speedup, achieving real-time detection at 45 FPS. Subsequently, community-driven improvements such as those from Ultralytics further enhanced the versions.
The initial challenge was balancing the stability of mature versions with the cutting-edge accuracy of the latest releases. While older versions like Ultralytics YOLOv8 have become industry standards due to their anchor-free design and extensive community support, we ultimately focused on YOLO11, even previewing the emerging Ultralytics YOLO26 to ensure the benchmark is future-proof.
Technical analysis shows that YOLO11 achieves a significant leap in parameter efficiency and raw accuracy. For the benchmark, we selected the YOLO11l (large) variant, which achieves a mAP of 53.4% on the COCO dataset, outperforming YOLOv8l's 52.9%. mAP (Mean Average Precision), as the ultimate quality metric, balances precision (number of correct detections) and recall (number of objects found). This is achieved with only 25.3 million parameters, by replacing the old C2f module with the efficient C3k2 block and integrating C2PSA (Cross-Stage Partial Spatial Attention) to enhance focus on salient regions without proportional increase in computational cost.
Beyond the YOLO family, we also evaluated other modern architectures, such as EfficientDet (with its accuracy-FLOPs ratio from BiFPN), transformer-based detectors like DETR and its deformable successors (streamlining training without NMS and providing global context). Ultimately, we chose YOLO11 Large for its unmatched production throughput, which rigorously tests hardware interconnects and data loading pipelines. Selecting YOLO11 allows the MLPerf benchmark to reflect real-world deployment patterns and drives vendors to optimize efficient attention-augmented convolutional neural networks.
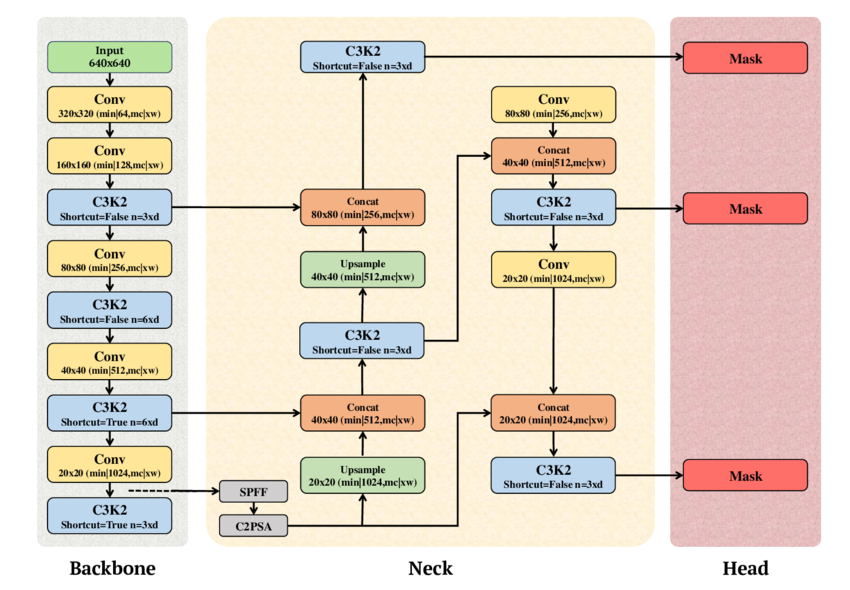
Figure 1. Schematic of YOLO11, showing Backbone, Neck, and Head components (adapted from "LEAF-Net" by A. T. Khan and S. M. Jensen, December 2024).
Dataset
Choosing an appropriate dataset is a key decision for integrating the YOLO Inference benchmark, serving as the ground truth for benchmark validity. We selected COCO 2017 (Common Objects in Context), as it is used for training YOLO models and remains the gold standard for object detection. With 80 object categories and over 1.5 million instances, it ensures the model does not just memorize shapes but truly understands spatial relationships and hidden components in real images. The model was not trained by the task force; we used a subset of the COCO validation set and verified that it maintains original accuracy.
However, there are legal compliance challenges in distributing large datasets for open benchmarks like MLPerf. Although COCO annotations are open, some images are labeled "Non-Commercial," which does not meet commercial benchmark requirements. To address this, the task force developed a custom filtering pipeline to create a safe subset of the full COCO 2017, ensuring that the partner dataset is fully distributable and legally compliant for both academia and industry, without compromising the statistical integrity of the benchmark.
MLPerf Subset
| Dataset | # of classes | # of validation images | Size |
|---|---|---|---|
| COCO Full | 80 | 5000 | ~170 MB |
| COCO MLPerf | 80 | 1525 | ~52 MB |
Table 1: Total safe image counts of the COCO MLPerf subset versus the full dataset.
LoadGen Integration
After creating the COCO dataset, ensuring consistent accuracy in the YOLO LoadGen integration was critical. MLCommons LoadGen (Load Generator) is a reusable C++ library (with Python bindings) that fairly measures ML inference system performance through standardized query traffic patterns such as SingleStream, MultiStream, and Offline. The LoadGen API records all queries and responses for verification and aggregates results to check whether latency constraints are met. It is model-agnostic and does not handle accuracy evaluation, but generates files required for model-specific accuracy computation.
Initially, the YOLO11 implementation produced a standard predictions.json file, which, while suitable for general COCO validation, was incompatible with the COCO MLPerf Accuracy script. The reasons include:
- Inconsistent class mapping: YOLO traditionally uses COCO-derived 80-class indices (0–79), but MLPerf accuracy evaluation requires a 91-class mapping with non-continuous IDs.
- Coordinate normalization: Standard YOLO outputs are often absolute pixel coordinates or in XYWH format. For accuracy evaluation, a specific serialized payload is required: a 7-element float array [index, ymin, xmin, ymax, xmax, score, class], where coordinates must be normalized relative to the original image dimensions (0.0–1.0).
- Buffer serialization: Unlike standard JSON, MLPerf LoadGen requires serialization into a byte buffer via the QuerySamplesComplete API.
After identifying and resolving the above issues, our YOLO LoadGen implementation matched the Ultralytics reference mAP. The strategies included:
- Class reindexing: Using the official COCO 80-to-91 conversion array to implement a robust mapping layer, ensuring each YOLO detection is immediately translated into the class ID space recognized by the accuracy script.
Target ID = COCO80_to_91[Model Class Index] - Coordinate transformation: Rewriting the Runner.enque logic to dynamically handle image geometry. Extracting the original height (H) and width (W) from Ultralytics result objects and normalizing in real-time.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接