Introduction
The release of MLPerf® Inference v6.0 marks a significant expansion in coverage of open-source large language models (LLMs). As the industry shifts toward more specialized and capable open-source models, benchmarks must evolve to reflect changes in deployment strategies and model architectures.
This round, the Reasoning LLM task group introduces two major additions:
- GPT-OSS 120B: A new benchmark based on a popular open-source high-capacity model, excelling in mathematics, scientific reasoning, and coding, featuring a large-scale mixture-of-experts (MoE) architecture with 117B total parameters.
- DeepSeek-R1 Interactive Scenario: Building on the existing DeepSeek-R1 benchmark, a new interactive workload with low-latency constraints is added for real-time inference applications. This is the first standardized speculative decoding in MLPerf.
GPT-OSS 120B New Benchmark
GPT-OSS 120B is a popular open-source high-capacity model, adopting an MoE architecture with 117B total parameters (5.1B active per token). The model natively supports configurable inference effort levels and is deployed in diverse, complex knowledge-intensive workflows, including advanced coding, competition mathematics, and graduate-level scientific reasoning.
Frontier models are often deployed across a wide range of production workloads, from fast routine requests to complex multi-step problem solving. To accurately reflect this duality, we introduce a split-dataset strategy:
- A performance dataset for routine low-effort tasks (e.g., summarization).
- An accuracy dataset for difficult reasoning problems in coding, scientific knowledge, and mathematics.
Both modes use the OpenAI Harmony chat format, directly controlling the model's reasoning effort (low, medium, high) via system prompts.
Dataset Selection
For the first time, MLPerf Inference benchmarks separate performance and accuracy datasets. All previous benchmarks used a single dataset. This separation brings flexibility for future benchmark definitions, and since the two tasks differ, optimal datasets can be selected for each.
The task group ensures consistency between performance and accuracy runs by adding a new compliance test to verify accuracy in performance mode.
Accuracy Mode (High Reasoning Effort)
To ensure a fair accuracy baseline, we curated a composite dataset requiring high reasoning effort:
- Maximum output length: 32,768 tokens.
- Evaluation strategy: Pass@1 with k repetitions.
- Dataset:
- AIME 2024: Advanced mathematics problems. Metric: Exact Match.
- LiveCodeBench v6: Real-time coding tasks. Metric: Pass/Fail.
- GPQA-Diamond: Graduate-level science QA. Metric: Correct/Not Correct.
Evaluation is based on the official OpenAI scripts. We created the feat/mlperf_integration branch to support tokenized input inference (HarmonySampler) and added LiveCodeBench v6 evaluation. Input trajectories were collected via multiple runs of gpt_oss.evals to determine reliable accuracy thresholds for AIME25, LCB_V6, and GPQA_Diamond.
GPT-OSS Accuracy Targets
Submission implementations must meet or exceed the following accuracy dataset targets:
| Dataset | Repeats per Sample | Accuracy Target | Evaluation Metric |
|---|---|---|---|
| AIME 2024 | 8 | 82.92% | Exact Match (MCQ) |
| GPQA-Diamond | 5 | 74.95% | Correct/Not Correct |
| LiveCodeBench v6 | 8 | 84.68% | Pass/Fail (Code Execution) |
Performance Mode (Low Reasoning Effort)
To measure pure inference speed (tokens/second), we use a dataset sampled from ccdv/pubmed-summarization:
- Task: PubMed health article summarization.
- Configuration: Harmony format "low reasoning effort".
- Sequence length: Maximum output 10,240 tokens.
- Metrics: Throughput and latency.
- Average input sequence length: 5,000 tokens
- Average output sequence length: 1,250 tokens
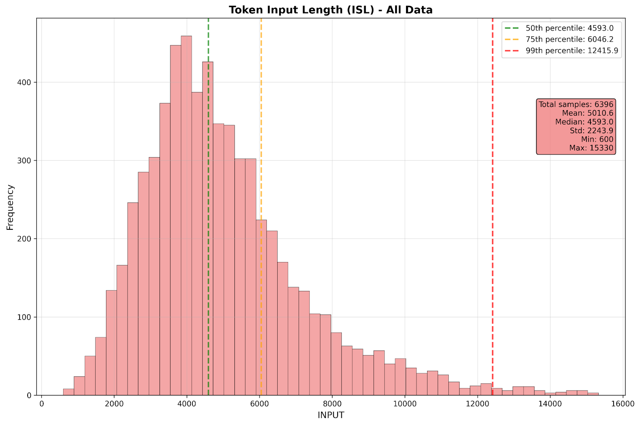
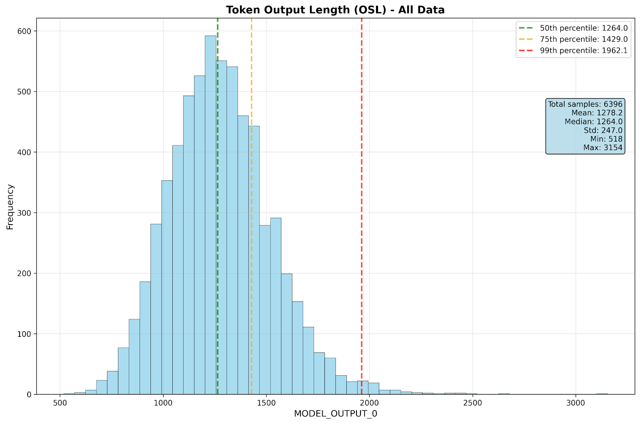
Performance Metrics
Performance metrics evaluate the system under strict latency constraints, depending on the deployment scenario:
GPT-OSS constraints:
- Interactive scenario: 99th percentile TTFT ≤ 2.0s; TPOT ≤ 15ms.
- Server scenario: 99th percentile TTFT ≤ 3.0s; TPOT ≤ 80ms.
Accuracy Metrics
For GPT-OSS, accuracy is strictly evaluated on the accuracy mode datasets: Exact Match for AIME 2024, code execution (Pass/Fail) for LiveCodeBench v6, and Correct/Not Correct for GPQA-Diamond.
Compliance Checks
Due to the use of split datasets, new compliance checks are introduced to ensure accuracy in performance mode:
- TEST07: Verifies accuracy of performance runs using the GPQA dataset (one of the three accuracy datasets). Evaluating all three datasets is computationally prohibitive, so a subset is used.
- TEST09: Verifies that the average output length of the performance dataset is within ±10% of the reference implementation.
Reference Implementation
The official reference implementation for MLPerf Inference v6.0 provides end-to-end evaluation code and instructions.
- GPT-OSS 120B: GitHub link
DeepSeek-R1 Interactive Scenario New Workload
Building on the DeepSeek-R1 benchmark introduced in v5.1, a new interactive scenario is added, representing the need for low-latency responses in advanced reasoning use cases such as mathematics, knowledge reasoning, and complex coding. The datasets (LiveCodeBench, MATH500, AIME, GPQA-Diamond, MMLU-Pro) are the same as in the server scenario, with a minimum query count of 4,388, but with tighter response time constraints.
Performance Metrics
Performance metrics evaluate the system under strict latency constraints:
DeepSeek-R1 Interactive Constraints & Speculative Decoding:
- New Interactive Scenario (Poisson arrival): 99th percentile TTFT ≤ 1.5s; TPOT ≤ 15ms.
- (Existing) Server Scenario (Poisson arrival): 99th percentile TTFT ≤ 2s, TPOT ≤ 80ms.
To meet the stringent latency requirements of the DeepSeek-R1 interactive scenario, speculative decoding is enabled, which must use the official DeepSeek-R1 MTP (Multi-Token Prediction) Head and EAGLE-style decoding:
- Algorithm: EAGLE-style decoding, deepseek-ai/deepseek-r1 MTP head.
- Configuration: speculative-num-steps=3, speculative-eagle-topk=1.0.
- Prohibited: No artificial manipulation of acceptance rates, such as continued pre-training of the MTP head, quantization, or post-training adjustments (fine-tuning, RLHF).
- See official rules for details: mlperf-inference/policies
Accuracy Metrics
DeepSeek-R1 Interactive accuracy metrics are the same as for v5.1 server submissions (exact match for math/QA, code execution for LiveCodeBench), ensuring that speculative decoding does not degrade the model's reasoning capability.
Reference Implementation
The official reference implementation for MLPerf Inference v6.0 provides the necessary code and running instructions.
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接