引言
MLPerf® Inference v6.0 的发布标志着对开源大语言模型(LLM)领域的覆盖范围显著扩大。随着行业转向更专业化且能力更强的开源模型,基准测试必须演进,以反映部署策略和模型架构的转变。
本轮,Reasoning LLM 任务组引入两大重要新增:
- GPT-OSS 120B:基于热门开源高能力模型的新基准,擅长数学、科学推理和编码,采用117B总参数的大规模混合专家(MoE)架构。
- DeepSeek-R1 交互场景:在现有 DeepSeek-R1 基准基础上,新增低延迟约束的交互工作负载,针对实时推理应用。这是 MLPerf 中首次标准化的 speculative decoding。
GPT-OSS 120B 新基准
GPT-OSS 120B 是热门开源高能力模型,采用 MoE 架构,总参数117B(每 token 活跃5.1B)。该模型原生支持可配置推理努力级别,部署于多样复杂知识密集型工作流,包括高级编码、竞赛数学和研究生级科学逻辑。
前沿模型常部署于从快速常规请求到复杂多步问题求解的广泛生产工作负载。为准确反映这一双重性,我们引入分数据集策略:
- 常规低努力任务的性能数据集(如摘要生成)。
- 编码、科学知识和数学领域困难推理问题的准确数据集。
两种模式均使用 OpenAI Harmony chat 格式,通过系统提示直接控制模型推理努力(低、中、高)。
数据集选择
MLPerf 推理基准首次分离性能与准确数据集。此前所有基准均使用单一数据集。分离带来灵活性,便于未来基准定义,且两任务不同,可选用最优数据集。
任务组确保性能与准确运行一致性,通过新增合规测试验证性能模式下的准确率。
准确模式(高推理努力)
为确保公平准确基线,我们 curation 复合数据集,要求高推理努力:
- 最大输出长度: 32,768 tokens。
- 评估策略: Pass@1,带 k 次重复。
- 数据集:
- AIME 2024: 高级数学问题。指标:Exact Match。
- LiveCodeBench v6: 实时编码任务。指标:Pass/Fail。
- GPQA-Diamond: 研究生级科学 QA。指标:Correct/Not Correct。
评估基于 OpenAI 官方脚本。我们创建 feat/mlperf_integration 分支,支持 tokenized 输入推理(HarmonySampler),并添加 LiveCodeBench v6 评估。通过多次运行 gpt_oss.evals 收集输入轨迹,确定 AIME25、LCB_V6 和 GPQA_Diamond 的可靠准确阈值。
GPT-OSS 准确率目标
提交实现必须达到或超过以下准确数据集目标:
| Dataset | Repeats per Sample | Accuracy Target | Evaluation Metric |
|---|---|---|---|
| AIME 2024 | 8 | 82.92% | Exact Match (MCQ) |
| GPQA-Diamond | 5 | 74.95% | Correct/Not Correct |
| LiveCodeBench v6 | 8 | 84.68% | Pass/Fail (Code Execution) |
性能模式(低推理努力)
为测量纯推理速度(tokens/second),使用从 ccdv/pubmed-summarization 采样的数据集:
- 任务: PubMed 健康文章摘要生成。
- 配置: Harmony 格式“低推理努力”。
- 序列长度: 最大输出 10,240 tokens。
- 指标: 吞吐量与延迟。
- 平均输入序列长度: 5,000 tokens
- 平均输出序列长度: 1,250 tokens
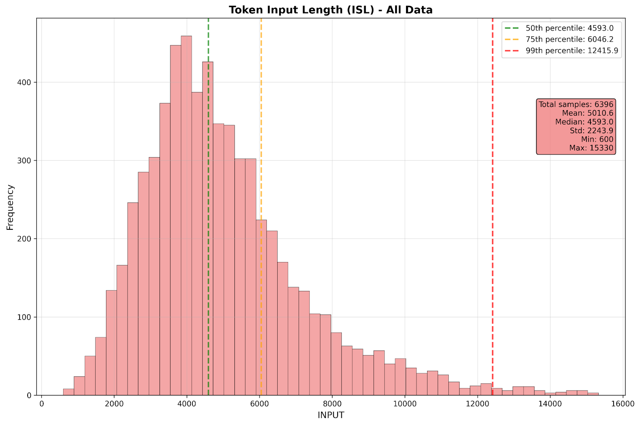
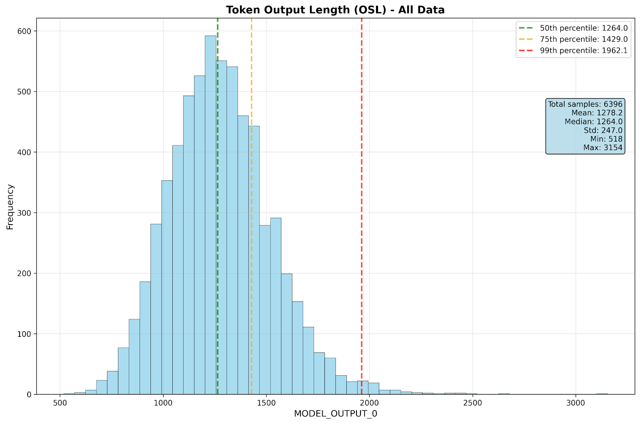
性能指标
性能指标在严格延迟约束下评估系统,根据部署场景:
GPT-OSS 约束:
- 交互场景: 99th percentile TTFT ≤ 2.0s;TPOT ≤ 15ms。
- 服务器场景: 99th percentile TTFT ≤ 3.0s;TPOT ≤ 80ms。
准确指标
对于 GPT-OSS,准确率严格基于准确模式数据集评估:AIME 2024 用 Exact Match,LiveCodeBench v6 用代码执行(Pass/Fail),GPQA-Diamond 用 Correct/Not Correct。
合规检查
因使用分离数据集,引入新合规检查确保性能模式准确率:
- TEST07:使用 GPQA 数据集(三准确数据集之一)验证性能运行准确率。全三数据集计算开销过大,故用子集。
- TEST09:验证性能数据集平均输出长度在参考实现 ±10% 内。
参考实现
MLPerf Inference v6.0 官方参考实现提供端到端评估代码与说明。
- GPT-OSS 120B: GitHub 链接
DeepSeek-R1 交互场景新工作负载
基于 v5.1 引入的 DeepSeek-R1 基准,新增交互场景,代表数学、知识推理与复杂编码等高级推理用例对低延迟响应的需求。数据集(LiveCodeBench、MATH500、AIME、GPQA-Diamond、MMLU-Pro)与服务器场景相同,最小查询数 4,388,但响应时间约束更紧。
性能指标
性能指标在严格延迟约束下评估:
DeepSeek-R1 交互约束 & Speculative Decoding:
- 新交互场景(Poisson 到达): 99th percentile TTFT ≤ 1.5s;TPOT ≤ 15ms。
- (现有)服务器场景(Poisson 到达):99th percentile TTFT ≤ 2s,TPOT ≤ 80ms。
为满足 DeepSeek-R1 交互场景苛刻延迟,启用 speculative decoding,必须使用官方 DeepSeek-R1 MTP(Multi-Token Prediction)Head 与 EAGLE-style decoding:
- 算法: EAGLE-style decoding,deepseek-ai/deepseek-r1 MTP head。
- 配置: speculative-num-steps=3, speculative-eagle-topk=1.0。
- 禁止: 不得人为操纵接受率,如 MTP head 持续预训练、量化或后训练调整(微调、RLHF)。
- 详见官方规则:mlperf-inference/policies
准确指标
DeepSeek-R1 交互 准确指标与 v5.1 服务器提交相同(数学/QA 精确匹配,LiveCodeBench 代码执行),确保 speculative decoding 不降低模型推理能力。
参考实现
MLPerf Inference v6.0 官方参考实现提供必要代码与运行说明。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接