我们引入了一种基于RDMA的点对点权重更新机制,用于SGLang中的RL工作负载,作为传统NCCL广播方法的补充。该机制兼容所有主流开源模型。通过利用源端CPU engine replica和Mooncake TransferEngine实现的P2P RDMA transfers,我们将1T参数Kimi-K2模型的权重传输时间加速7倍(从53秒降至7.2秒),仅需额外消耗每个训练rank的32G CPU内存。这些优化最小化了网络冗余,并允许推理服务器显著更快地恢复 rollout 操作。
背景
NVIDIA的NCCL通过自动检测硬件拓扑并协调数据流(如环形或树形算法),优化了像all-gather和broadcast这样的原语。作为PyTorch FSDP、DeepSpeed和Megatron-LM的默认通信后端,它已成为对称训练的行业标准。然而,它依赖集体语义,要求每个rank同时调用相同的操作,并匹配数据形状。虽然在平衡负载中高效,但这种设计在动态环境中成为负担:NCCL以锁步方式运行,单个接收器的“慢启动”可能导致整个组挂起,并使资源闲置。
RDMA(Remote Direct Memory Access)允许机器直接访问远程内存,而完全绕过远程CPU和内核网络栈。其效率源于三个核心特性:
- Kernel Bypass:应用程序直接向NIC提交工作请求,消除昂贵的系统调用和上下文切换。
- Zero Copy:数据通过DMA直接在注册的内存区域和网络之间移动,避免内核缓冲区的中间拷贝。
- One-Sided Operations:RDMA READ/WRITE操作由一方发起,无需远程端活跃CPU参与或中断处理。
与NCCL的全局同步不同,RDMA允许任意两个端点独立并发通信,这使其成为高速权重传输的理想基础。这正是本文所述P2P权重更新机制利用Mooncake TransferEngine实现的RDMA传输作为底层基础的原因。
RL权重传输问题:在大型分布式RL训练中,从训练器到推理引擎的权重传输是关键路径操作:在传输期间,整个RL训练会停滞——训练器和推理均无进展,资源通常闲置。随着模型增长,此传输需扩展到多个主机和机架,所有这些都在争夺有限带宽。现有基于NCCL的开源解决方案(如miles/slime/verl)依赖单个源rank的broadcast原语,这很快成为传输瓶颈。
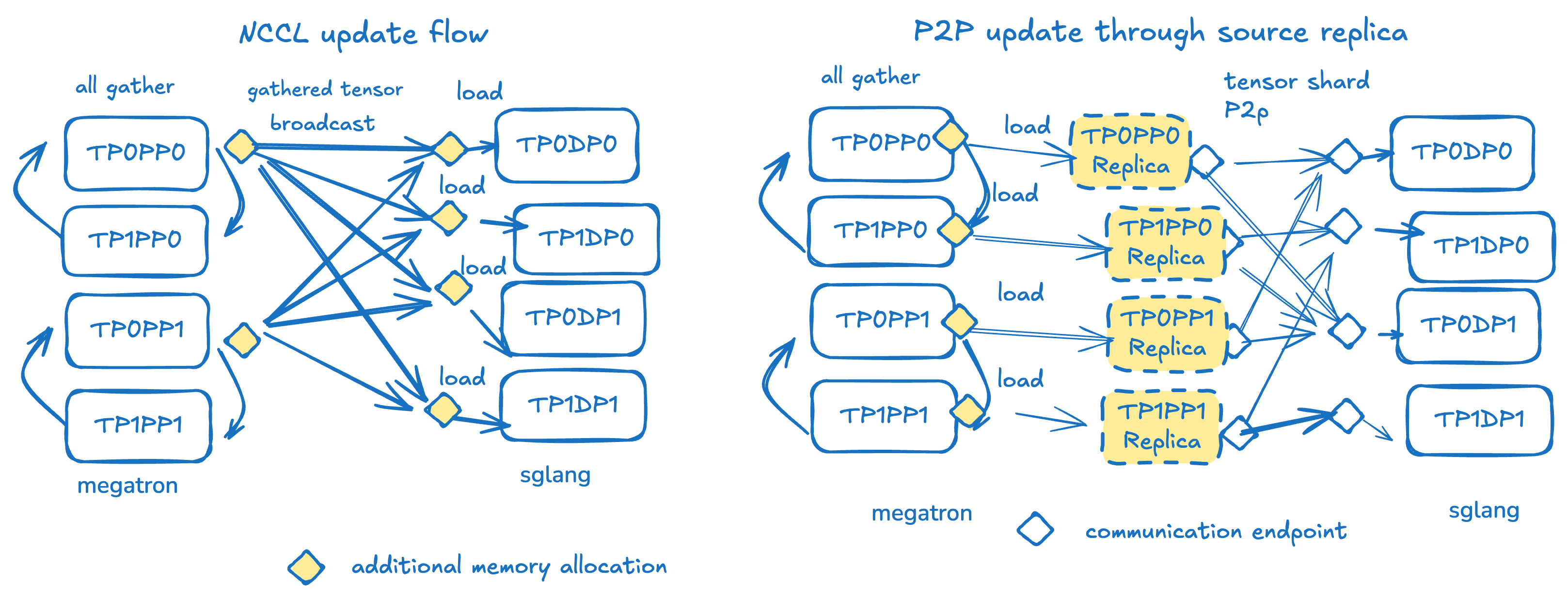
左图:miles分布式训练/推理RL中的当前权重传输工作流。在源端,所有节点在TP和EP维度参与all gather,导致每个PP rank的头rank获得聚集张量。头rank通过update_weight_from_distributed API参与分布式更新组,将完整权重广播到每个引擎rank,其中本地rank加载其对应分片。此过程针对每个PP rank和每个桶化权重张量运行。
右图:P2P更新设计依赖源端引擎副本作为中介。桶化权重更新的第一个all gather步骤与miles相同。但随后,权重加载到CPU内存上的本地sglang引擎分片副本,该副本以正确形状将权重发送到sglang。每个副本的权重可发送到多个sglang rank。每个目标sglang TP rank需从每个PP源接收。
现有NCCL广播的挑战
现有NCCL广播解决方案面临以下挑战:
- 冗余:相同数据多次通过网络发送。
- 不活跃:大多数训练rank在传输期间闲置,只有少数参与广播。
- 刚性:一旦定义,NCCL通信组即固定,因此与新创建的引擎实例动态扩展涉及复杂变更。
此比较评估了传输1T FP8 Kimi K2模型(约1TB)的性能。注意:update_weights_from_tensor接口被排除,因为它仅支持共置场景。
| Strategy | Efficiency | Open Source Support | Dynamic | Training Side Support | System Complexity | Architectural Flexibility |
|---|---|---|---|---|---|---|
| Disk I/O Strategy (`update_weights_from_disk`) | 🆘 ~Several Minutes | ✅ Yes | ✅ Yes | ✅ Megatron FSDP | 😊 Simple | 😊 Single API |
| NCCL Broadcast (`update_weights_from_distributed`) | 🥵 ~50 Seconds | ✅ Yes | 🚫 No (Requires NCCL group rebuild) | ✅ Megatron FSDP | 😊 Simple | 😊 Single API |
| Perplexity [fabric-lib](https://arxiv.org/abs/2510.27656) P2P | ⚡ ~1.2 Seconds | 🚫 No (RDMA lib only) | ✅ Yes | ❓ FSDP2 DTensor only | 🥵 Very Complex | 🥵 Write-only |
| RDMA P2P (Our Implementation) | 😊 ~7 Seconds | ✅ Yes | ✅ Yes | ✅ Megatron FSDP | 😥 Complex | 😀 Multiple APIs |
虽然在传输效率上与Perplexity的方法相比存在权衡,但我们的解决方案比现有SGLang接口提供了显著性能提升。此外,通过将这些能力封装到新API接口中,我们实现了高架构灵活性。请参考[miles](https://github.com/radixark/miles/blob/main/docs/en/advanced/p2p-weight-transfer.md)上的运行说明,以及完整支持模型列表。
设计
我们的设计从集中式广播转向通过RDMA的分布式P2P映射;同时保持与所有现有开源模型和任何并行配置的兼容性,重用现有接口。
- Source-Side Engine Replicas:我们在训练rank的CPU内存中创建模型副本。这避免了浪费GPU VRAM,而无需重复注册和注销。
- P2P Mapping Heuristics:我们实现了训练rank和推理rank之间的点对点映射。每个训练rank通过直接发送其特定分片到目标来参与,而不是少数rank广播一切。
- Zero-Copy Transfer:使用TransferEngine,内存在启动时注册一次,绕过昂贵的CUDA IPC句柄序列化和内核侧拷贝。
实现高度依赖现有基础设施和接口:
- [TransferEngine](https://kvcache-ai.github.io/Mooncake/python-api-reference/transfer-engine.html)作为底层传输层,实现网络上CPU和GPU之间的RDMA零拷贝传输。
- 通过[Rfork](https://www.lmsys.org/blog/2025-12-10-rfork/)重用权重注册信息,这是通过SGLang API暴露的新远程实例权重加载机制。
- 标准SGLang API的
load_weight(huggingface_tensor),支持所有量化和社会分配置。
SGLang侧需要几个新接口:
- 暴露模型并行用于副本创建:[PR #20907](https://github.com/sgl-project/sglang/pull/20907)
- 映射Hugging Face张量与其对应SGLang张量分片:[PR #17326](https://github.com/sgl-project/sglang/pull/17326)
- 后处理权重引擎调用,用于GPU本地处理,如后量化,类似于[PR #15245](https://github.com/sgl-projectვ1st2nd3rd4th5th
这些接口已合并到miles目标的
sglang-miles分支中。在权重更新期间,调用方操作如下:初始化
Step Description get_remote_instance_transfer_engine_info调用SGLang API获取权重注册信息 get_parallelism_info调用SGLang API获取并行定义信息(tp、ep等) build_transfer_plan构建训练到推理rank的映射关系 create_engine_replica创建CPU引擎副本 每次更新期间
Step Description pause_and_register_engine调用SGLang API暂停引擎,并注册副本权重(一次) update_weight(non-expert and expert)桶化权重更新,先非专家权重然后专家权重 post_process_weights调用SGLang API后处理加载的权重,如量化 update_weight_version调用SGLang API更新权重版本 continue_generation调用SGLang API恢复操作 结果是一个通用权重更新设计,能处理任何模型和所有常见量化逻辑,同时实现快速RDMA零拷贝传输,无冗余,并提高带宽利用率。想象一个场景:M个源rank用于训练,N个目标rank用于SGLang推理;源rank有
pp_size的pp,目标rank有ep_size的ep;每个引擎rank有P个参数。我们还分配K作为桶化all gather的内存缓冲区。假设模型仅包含专家权重: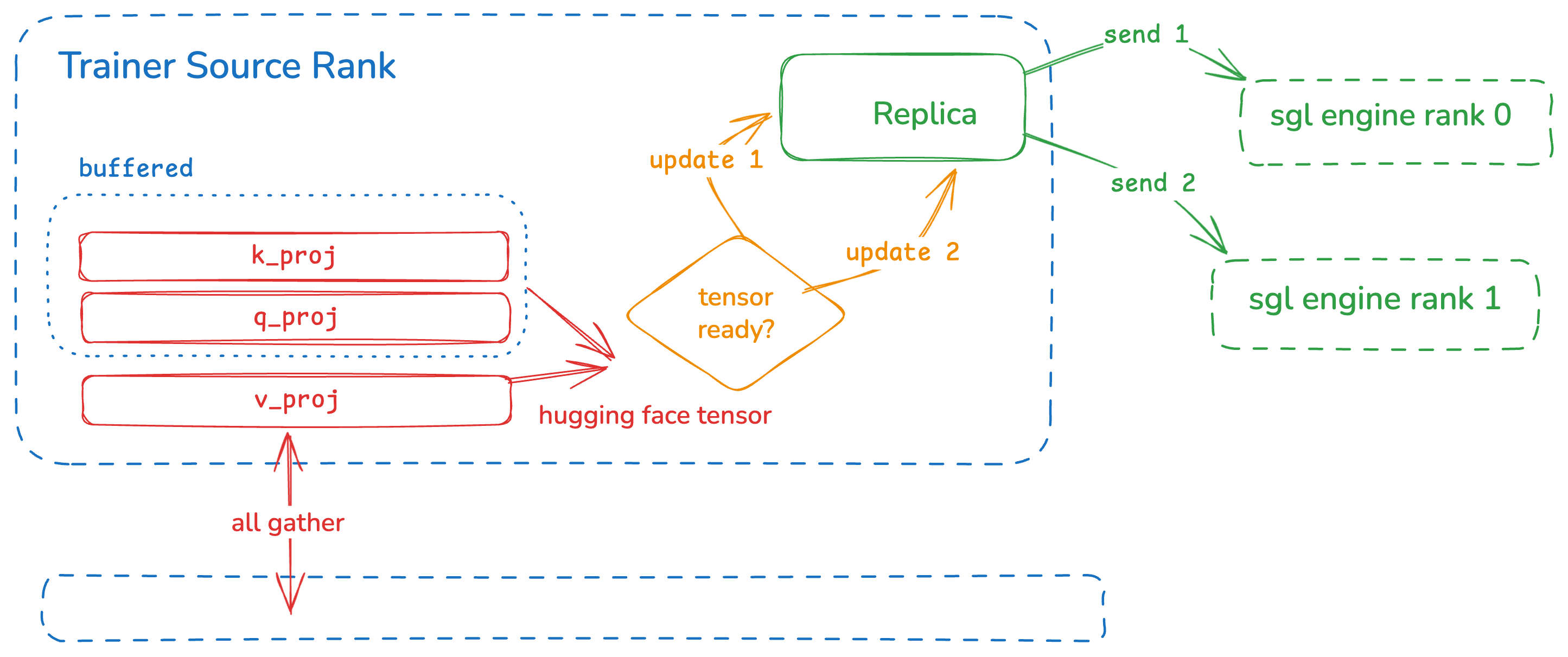
#Participating Source Ranks #Params received per inference rank #Additional buffer allocated on source #Additional buffer allocated on target NCCL Broadcast pp ep * P K K RDMA P2P M P K* + P 0 表格:展示RDMA P2P设计如何通过内存分配权衡实现更少的网络传输和更高利用率。所有源rank参与,而NCCL仅每个管道并行组的头rank参与;仅必要张量跨网络发送,而NCCL需要将完整聚集张量发送到每个rank。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接