自注意力机制由于其计算和内存的二次成本,成为了扩展大型语言模型(LLMs)到长上下文的主要瓶颈。因此,越来越多的人对高效注意力机制产生了兴趣。其中,稀疏注意力尤为引人注目。通过仅关注选定的KV缓存子集,稀疏注意力在保持强大建模能力的同时,避免了随着上下文增长而急剧增加的计算和I/O成本。
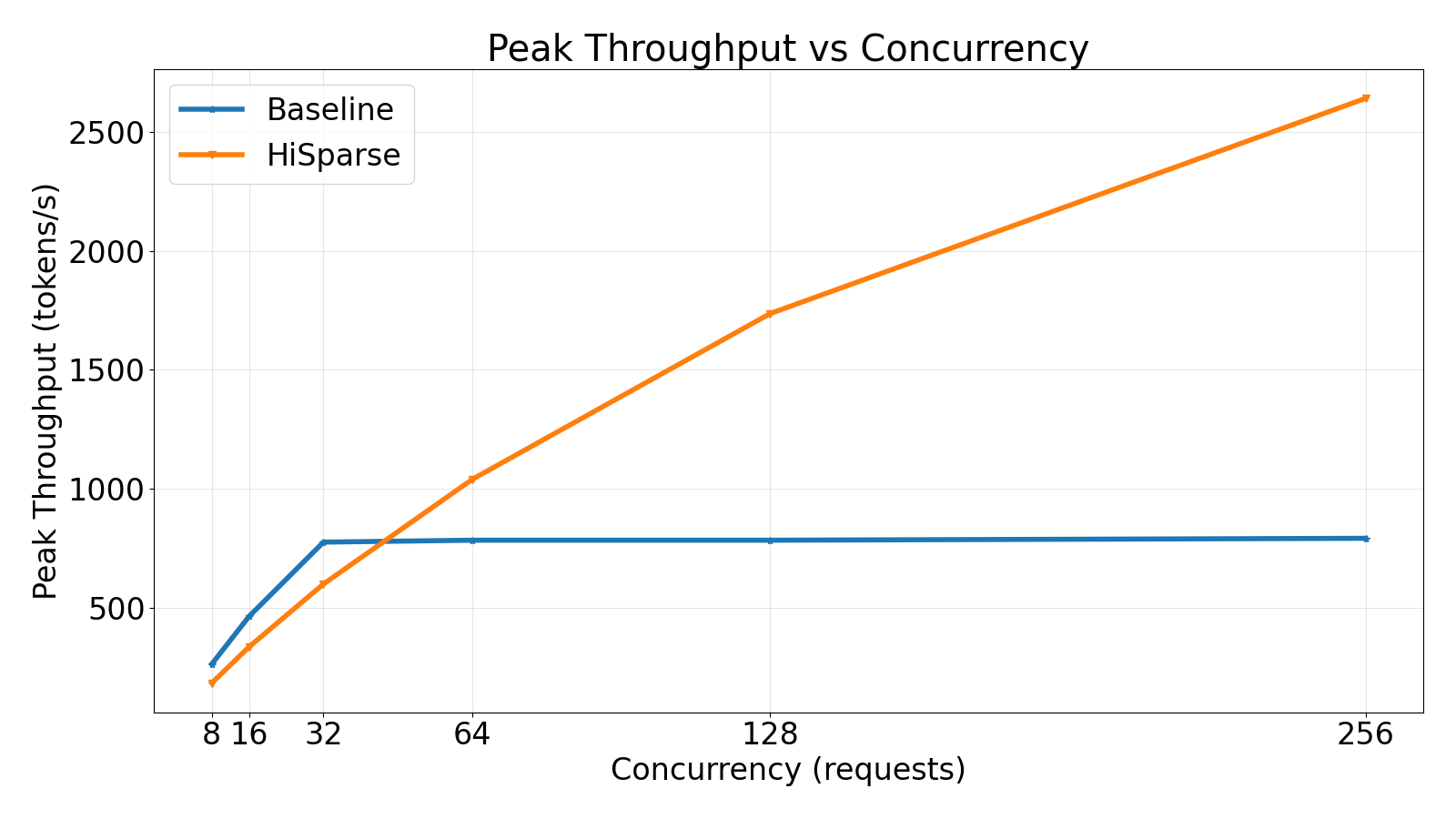
然而,稀疏注意力(通常是top-k选择)并没有消除内存容量瓶颈。在实际应用中,整个上下文的KV缓存必须保留在GPU的HBM中以便快速访问,即使在任何给定的解码步骤中只有一小部分条目是活跃的。因此,稀疏注意力往往受到容量的限制而非计算的限制,限制了可实现的批量大小和整体吞吐量。与之相比,HiSparse在增加并发时实现了接近线性的吞吐量扩展,在256个并发请求时达到基线吞吐量的3倍以上。需要注意的是,在低并发情况下,HiSparse引入了适度的开销,因为稀疏KV加载的额外I/O超过了内存节省。随着并发性的增加和内存压力的主导,这种增益变得显著。
HiSparse的设计
与我们之前的工作HiCache一致,我们提出了HiSparse:一种层次化内存系统,旨在克服这一限制。HiSparse积极地将非活跃的KV缓存条目卸载到主机内存中,显著减少了GPU内存压力,同时在GPU HBM上维护一个用于频繁访问的KV区域的热设备缓冲区,以便在关键路径上最小化数据移动。这使得更大的解码批量成为可能,提高了吞吐量并扩展到更长的上下文。下图展示了HiSparse的工作流程。尽管在一个预填充-解码分离的设置中进行了描绘,该设计同样适用于共址实例。
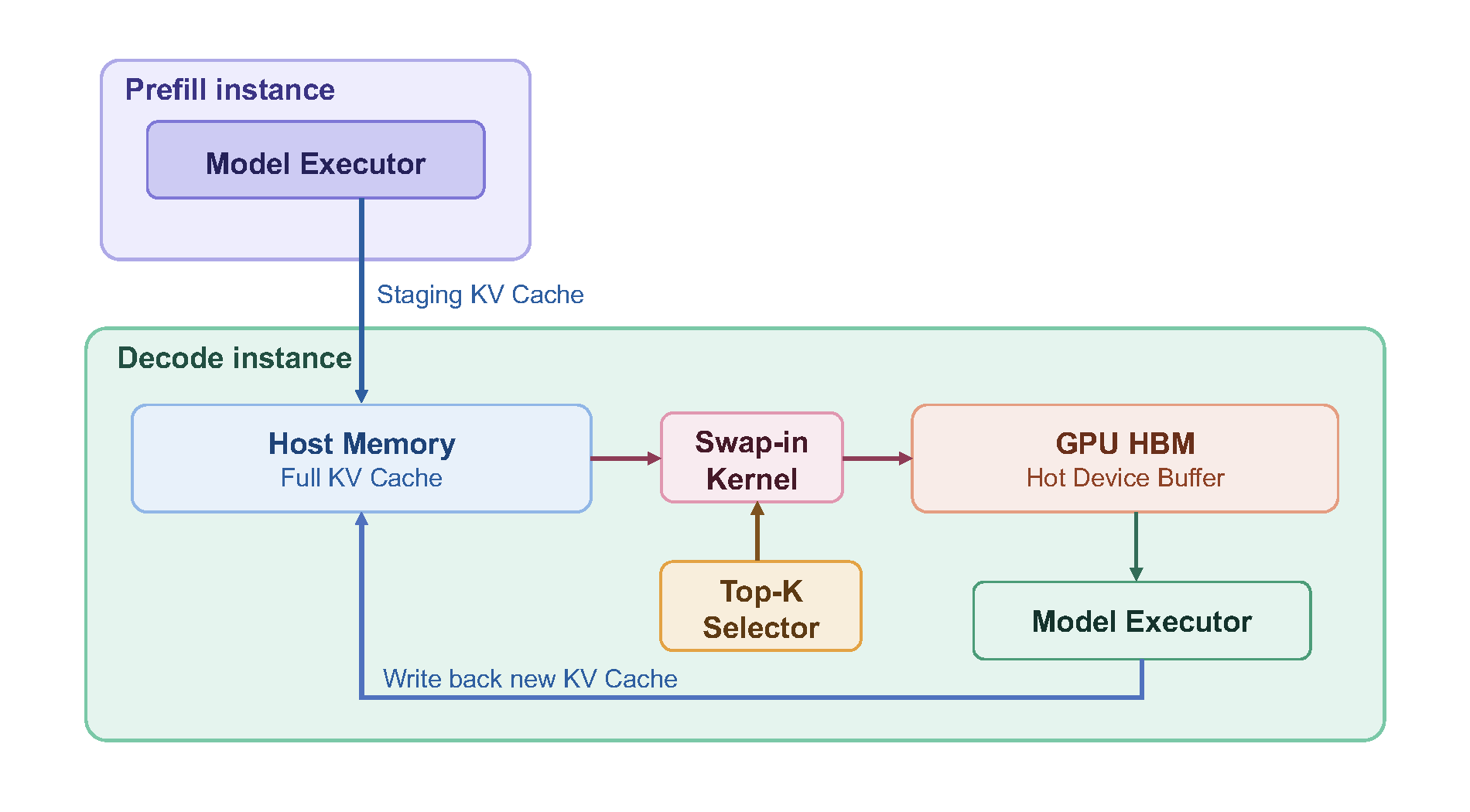
高效的Swap-in内核
该系统的核心是一种专用的CUDA内核,其高效地:
(1)识别设备缓冲区中的top-k缓存未命中,(2)通过LRU策略选择驱逐候选者,(3)更新页表并从主机到设备内存中获取所需的条目。
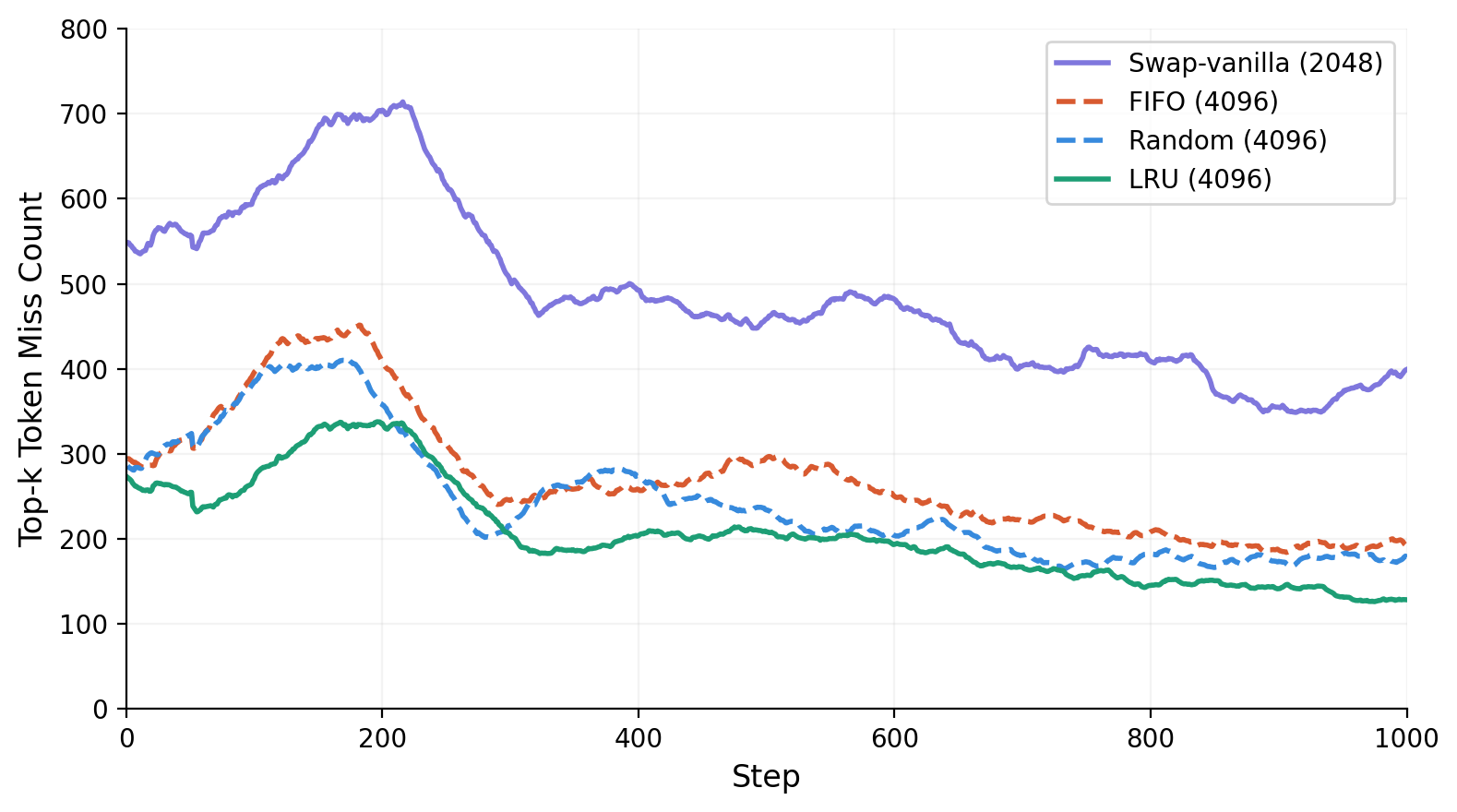
下图展示了热缓冲区大小和逐出策略对未命中率的影响。使用更大的热设备缓冲区(4096 vs. 2048槽)和LRU逐出策略,未命中次数大幅减少,直接转化为关键路径上更低的swap-in延迟。
基准测试
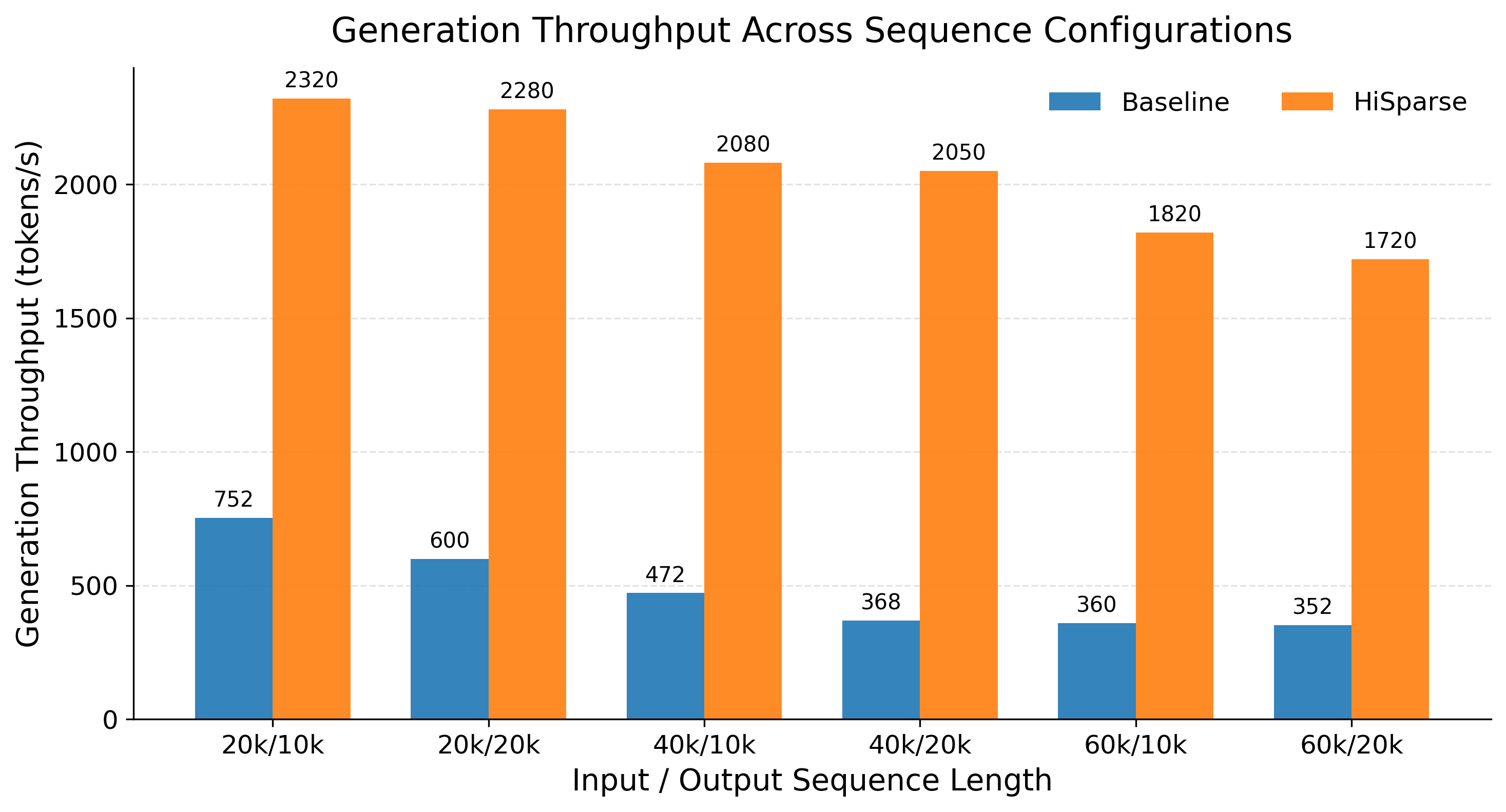
下文中,我们展示了对一款前沿开放模型GLM-5.1-FP8进行的各种序列配置的结果,在长上下文场景下实现了高达5倍的吞吐量提升,更多详细说明请参见这里。
# PD-disaggregation deployment (recommended) on two H20 nodes
# prefill instance:
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.8 \
--tp-size 8 --dp-size 8 --enable-dp-attention --schedule-conservativeness 0.5 \
--disaggregation-mode prefill \
--disaggregation-ib-device mlx5_0,mlx5_1,mlx5_2,mlx5_3 \
--dist-init-addr 127.0.0.1:5757 --nnodes 1 --node-rank 0
# decode instance:
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.85 \
--tp-size 8 --dp-size 8 --enable-dp-attention \
--load-balance-method round_robin --prefill-round-robin-balance \
--kv-cache-dtype bfloat16 --nsa-decode-backend flashmla_sparse \
--disaggregation-mode decode --dist-init-addr 127.0.0.1:5757 \
--disaggregation-ib-device mlx5_0,mlx5_1,mlx5_2,mlx5_3 --nnodes 1 --node-rank 0 \
--enable-hisparse \
--hisparse-config '{"top_k": 2048, "device_buffer_size": 6144, "host_to_device_ratio": 10}'
# PD-colocation deployment on a single 8xH200 instance
python3 -m sglang.launch_server \
--model-path "zai-org/GLM-5.1-FP8" --trust-remote-code --watchdog-timeout 100000 \
--chunked-prefill-size 65536 --max-running-requests 480 --mem-fraction-static 0.85 \
--tp-size 8 --dp-size 8 --enable-dp-attention --disable-radix-cache \
--enable-hisparse \
--hisparse-config '{"top_k": 2048, "device_buffer_size": 4096, "host_to_device_ratio": 8}'
未来工作
HiSparse目前支持使用DeepSeek Sparse Attention (DSA)的模型家族,包括DeepSeek-V3.2和GLM-5.1。作为一个实验性功能,我们期望继续改进其性能和模型覆盖。HiSparse设计用于高并发场景以最大化吞吐量;然而,由于top-k缓存未命中带来的额外I/O,它也引入了一些开销。我们期望通过更好的重叠来减少这种开销,并相信新平台如Grace Blackwell(GB)系统更高的CPU–GPU带宽将进一步缓解这一问题。
展望未来,沿着我们早期HiCache工作的方向,我们计划扩展这种层次化内存管理方法以支持更广泛的新兴架构,包括混合模型。
致谢
我们感谢阿里云TairKVCache团队和蚂蚁集团SCT推理团队的宝贵贡献。我们也感谢来自阿里云的蔡尚明、马腾和凌星宇以及来自SGLang社区的许子艺的慷慨支持。我们还感谢来自斯坦福的Christos Kozyrakis和Kristopher Geda,以及百度百歌AI团队的深刻反馈。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接