引言
MLPerf Inference 基准已发展为衡量人工智能(AI)基础设施性能的行业标准,通过公平的基准平台和多样化工作负载(如视觉、语音和自然语言处理)来实现这一地位。MLCommons 致力于跟上最新 AI 工作负载的步伐,不仅引入了生成式 AI 新模型,还升级了传统工作负载。YOLO 任务组成立,旨在将 Edge 套件中的 RetinaNet 基准升级为 Ultralytics YOLO11,这是一款更现代化的 state-of-the-art 检测模型。
RetinaNet 多年来一直是单阶段检测的可靠学术基准,但升级至更现代的 YOLO(You Only Look Once)变体有充分理由。YOLO 在研究和实际应用中迅猛发展,得益于加速创新、频繁发布和强大社区支持,成为现代目标检测工作负载中最有效且备受关注的模型之一。Ultralytics 于 2024 年 9 月发布的 YOLO11 引入了显著的架构和训练改进,实现更高精度且参数更少,提供从 YOLO11n(nano)到 YOLO11x(extra large)的变体,支持多样化的计算-精度权衡。与之相比,RetinaNet 近年更新较少,开发势头减弱,社区采用率下降。而 YOLO 家族持续快速演进,体现了 AI 行业目标检测领域的 cutting-edge 进展和主流趋势。
模型选择
在 YOLO 之前,state-of-the-art 检测器多为“two-stage”系统,先提出感兴趣区域再分类。YOLO 模型于 2015 年由华盛顿大学的 Joseph Redmon 等首次提出,将目标检测视为单一回归问题——在单次通过中同时预测边界框和类别概率,而以往如 R-CNN 需要每张图像数千次独立通过。这种“single-shot”方法牺牲少量精度换取巨大加速,实现 45 FPS 的实时检测。随后,Ultralytics 等社区驱动的改进进一步提升了版本。
初始挑战在于平衡成熟版本的稳定性与最新发布的 cutting-edge 精度。虽然 Ultralytics YOLOv8 等旧版凭借 anchor-free 设计和广泛社区支持已成为行业标准,但我们最终聚焦 YOLO11,甚至预览了新兴的 Ultralytics YOLO26,以确保基准 future-proof。
技术分析显示,YOLO11 在参数效率和原始精度上实现重大飞跃。对于基准,我们选用 YOLO11l(large)变体,在 COCO 数据集上 mAP 达 53.4%,优于 YOLOv8l 的 52.9%。mAP(Mean Average Precision)作为质量终极指标,平衡了精度(正确检测数)和召回率(发现对象数)。这得益于参数仅 2530 万,通过替换旧 C2f 模块为高效 C3k2 块,并集成 C2PSA(Cross-Stage Partial Spatial Attention),提升对显著区域的关注而无计算成本成比例增加。
除 YOLO 家族外,我们还评估了其他现代架构,如 EfficientDet(凭借 BiFPN 的精度-FLOPs 比)、transformer-based 检测器如 DETR 和 Deformable 后继者(流线型无 NMS 训练和全局上下文)。最终选用 YOLO11 Large,因其无与伦比的生产吞吐量,能严苛测试硬件互连和数据加载管道。选择 YOLO11 使 MLPerf 基准反映真实部署模式,推动厂商优化高效率 attention-augmented 卷积神经网络。
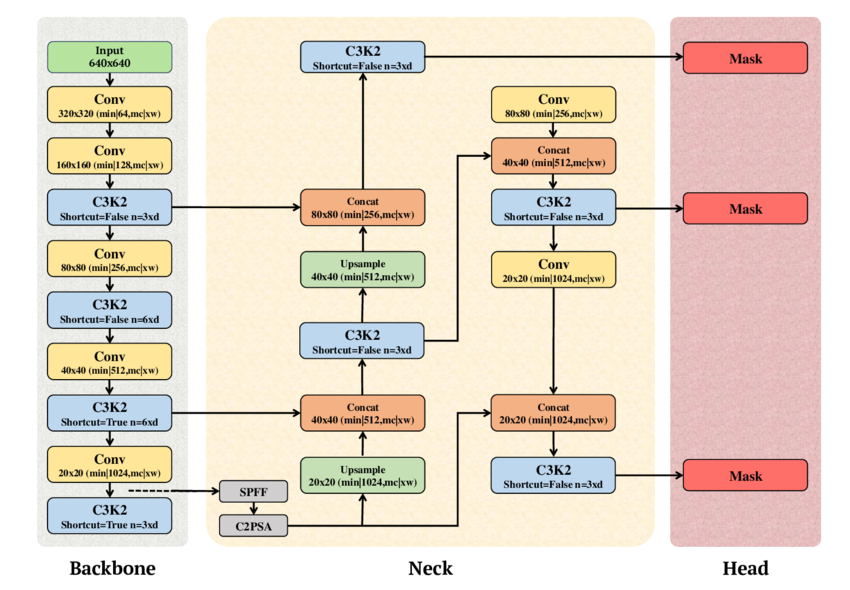
图 1. YOLO11 示意图,显示 Backbone、Neck 和 Head 组件(改编自 A. T. Khan 和 S. M. Jensen 的 LEAF-Net,2024 年 12 月)。
数据集
选择合适数据集是 YOLO Inference 基准集成的关键决策,作为基准有效性的 ground truth。我们选用 COCO 2017(Common Objects in Context),因其用于训练 YOLO 模型,并仍是目标检测金标准。包含 80 个对象类别、超过 150 万实例,确保模型不只是记忆形状,而是真正理解真实图像中的空间关系和隐藏组件。模型未由任务组训练,我们使用 COCO 验证集子集,并验证其保持原始精度。
然而,对于 MLPerf 等开放基准分发大规模数据集存在法律合规挑战,COCO 标注虽开放,但部分图像标注“Non-Commercial”,不符商业基准要求。为此,任务组开发自定义过滤管道,创建全 COCO 2017 的安全子集,确保合作伙伴数据集完全可分发且合法,适用于学术和工业,同时不损害基准统计完整性。
MLPerf 子集
| Dataset | # of classes | # of validation images | Size |
|---|---|---|---|
| COCO Full | 80 | 5000 | ~170 MB |
| COCO MLPerf | 80 | 1525 | ~52 MB |
表 1:COCO MLPerf 子集与完整数据集的安全图像总数对比。
LoadGen 集成
创建 COCO 数据集后,确保 YOLO LoadGen 集成的一致准确率至关重要。MLCommons LoadGen(Load Generator)是一个可复用 C++ 库(带 Python 绑定),通过标准化查询流量模式(如 SingleStream、MultiStream 和 Offline)公平衡量 ML 推理系统性能。LoadGen API 记录所有查询和响应,用于验证,并汇总是否满足延迟约束。它模型无关、不处理准确率评估,但生成模型特定准确率计算所需文件。
最初,YOLO11 实现生成标准 predictions.json 文件,虽适用于一般 COCO 验证,但与 COCO MLPerf Accuracy 脚本不兼容,原因包括:
- 类别映射不一致:YOLO 传统使用 COCO 衍生的 80 类索引(0-79),但 MLPerf 准确率评估需 91 类别映射,ID 非连续。
- 坐标归一化:标准 YOLO 输出常为绝对像素坐标或 XYWH 格式。为准确率评估,需特定序列化负载:7 元 float 数组 [index, ymin, xmin, ymax, xmax, score, class],坐标须相对于原图尺寸归一化(0.0-1.0)。
- 缓冲序列化:不同于标准 JSON,MLPerf LoadGen 要求通过 QuerySamplesComplete API 序列化为字节缓冲。
识别并解决上述问题后,我们的 YOLO LoadGen 实现与 Ultralytics 参考 mAP 匹配。策略包括:
- 类别重新索引:使用官方 COCO 80-to-91 转换数组实现鲁棒映射层,确保 YOLO 每个检测立即转换为准确率脚本认可的类别 ID 空间。
Target ID = COCO80_to_91[Model Class Index] - 坐标转换:重写 Runner.enque 逻辑动态处理图像几何。从 Ultralytics 结果对象提取原高度(H)和宽度(W),实时归一化。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接