SGLang RL 团队受 Kimi K2 启发,成功落地 INT4 Quantization-Aware Training (QAT) 端到端方案。通过训练阶段的 fake quantization 与推理阶段 W4A16 真实量化结合,实现与 BF16 全精度相当的训练-推理一致性与稳定性。
引言
近期 SGLang RL 团队在 RL 训练稳定性、效率及应用场景上取得多项进展,包括 INT4 QAT 端到端训练、统一多轮 VLM/LLM 训练、Rollout Router Replay、FP8 端到端训练及 RL 中的投机解码等。在此基础上,团队在 slime 框架上复现并部署了完整的 INT4 QAT 解决方案。
该方案深度借鉴 Kimi 团队 K2-Thinking 的 W4A16 QAT 实践,旨在提供兼顾稳定性和性能的开源参考。
技术概览
整体 Pipeline
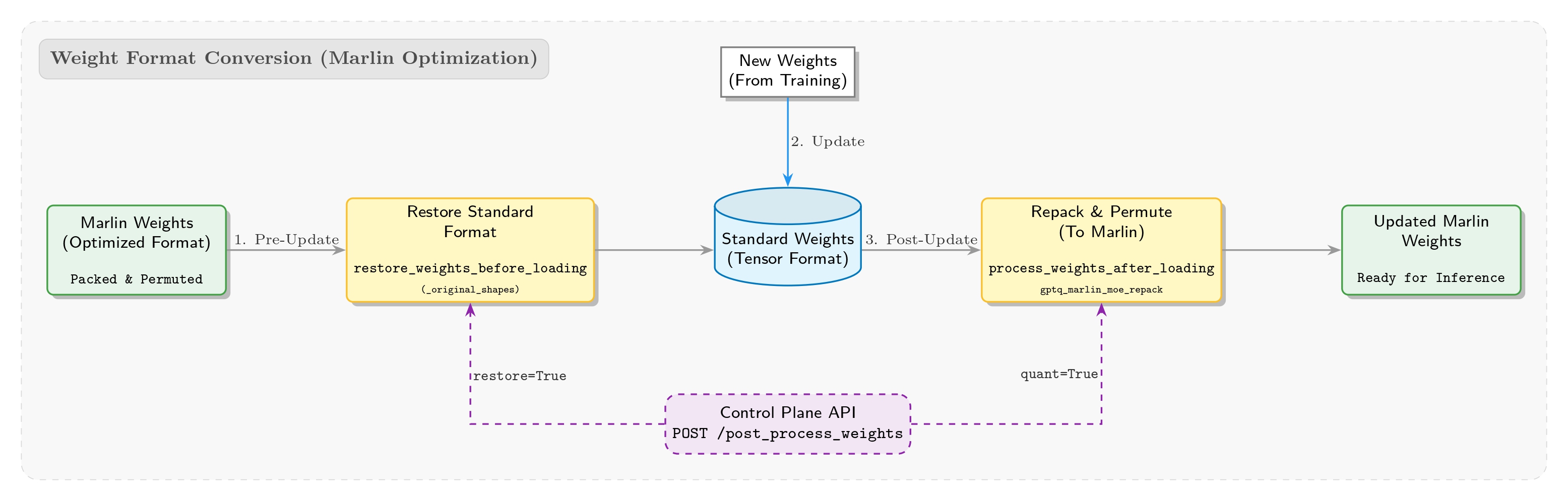
团队实现了从训练到推理的完整 INT4 QAT 闭环,如下图所示:
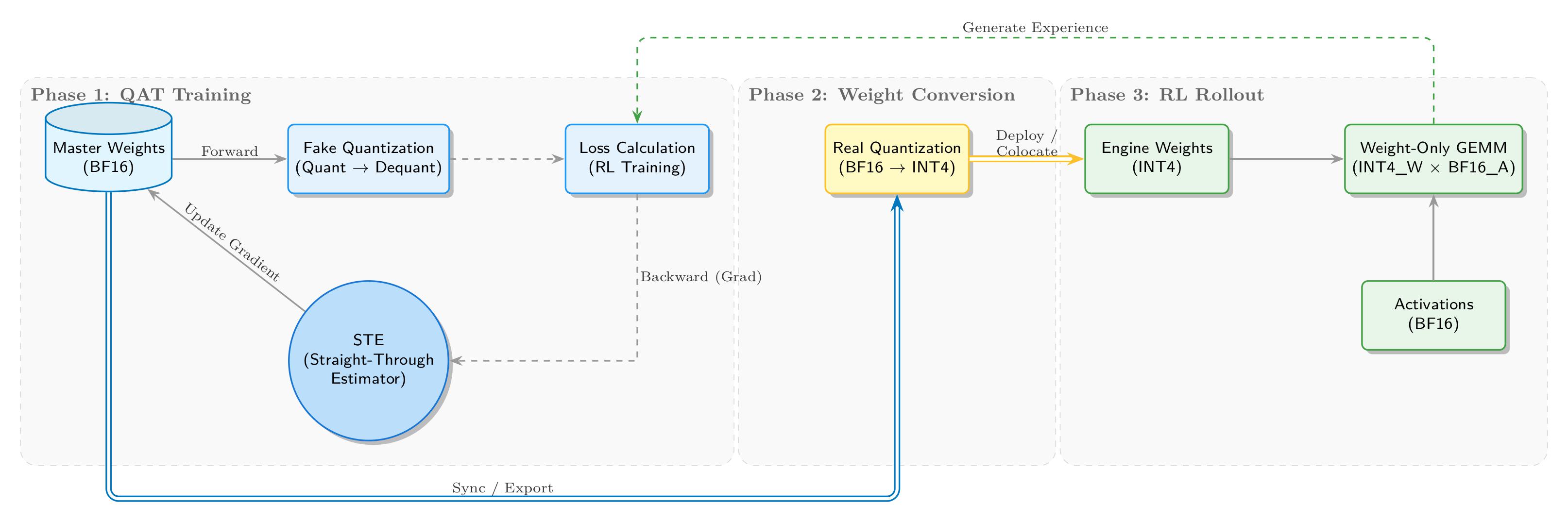
训练阶段维护 BF16 master weights,前向通过 fake quantization 注入量化噪声;反向使用 STE 绕过不可导问题。权重转换阶段导出 INT4 格式供推理引擎使用,RL rollout 阶段 SGLang 执行 W4A16 推理,形成自洽闭环。
关键策略选择
量化格式选用 INT4 (W4A16),兼顾硬件支持与成熟 Marlin 内核生态。训练采用 fake quantization + STE 经典组合,最大化低精度训练收敛稳定性。
训练侧:在 Megatron-LM 中集成 Fake Quantization
实现 Fake Quantization 与 STE
核心目标是在训练中实时模拟量化误差,迫使模型适应低精度表示。实现位于 megatron/core/extensions/transformer_engine.py 中的 _FakeInt4QuantizationSTE 类,基于 per-group 最大绝对值动态量化,模拟 INT4 范围并在 BF16 中注入误差,反向通过 STE 保持梯度直通。
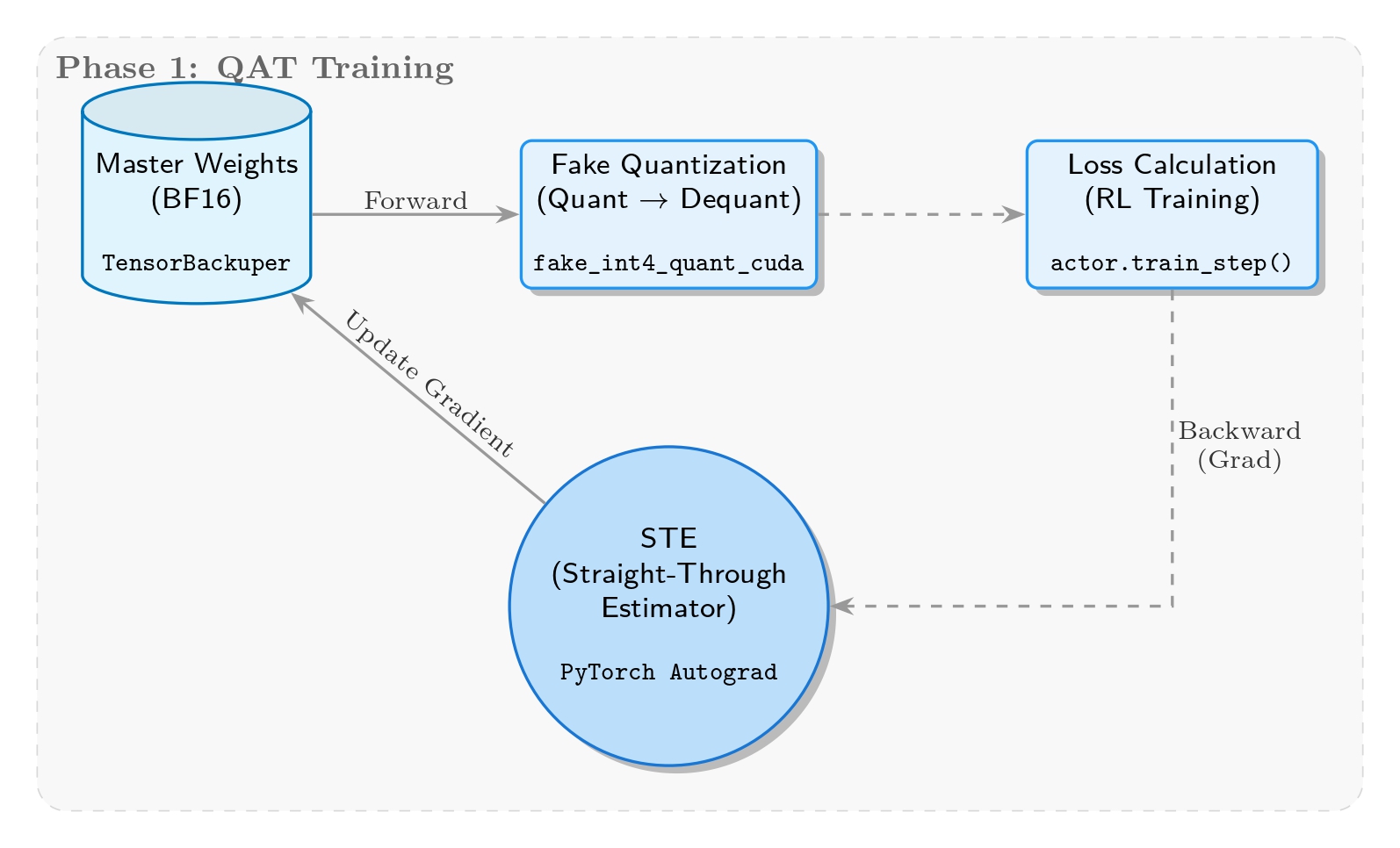
Fake Quantization 消融实验
为验证 QAT 必要性,设计了两组不对称场景消融:QAT INT4 训练 + BF16 rollout,以及无 QAT 直接 INT4 rollout。通过 Logprob Abs Diff 衡量训练-推理不一致性。
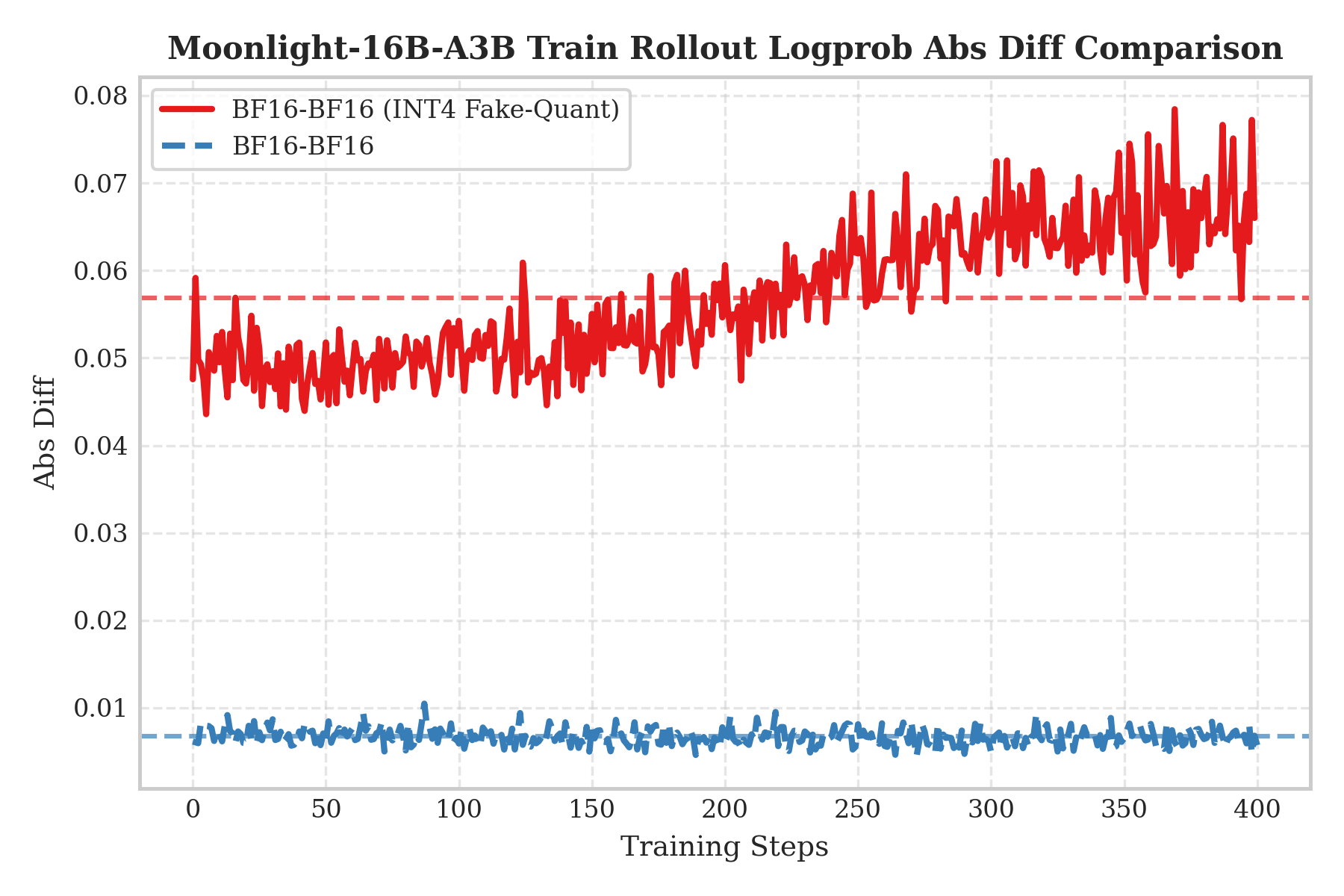
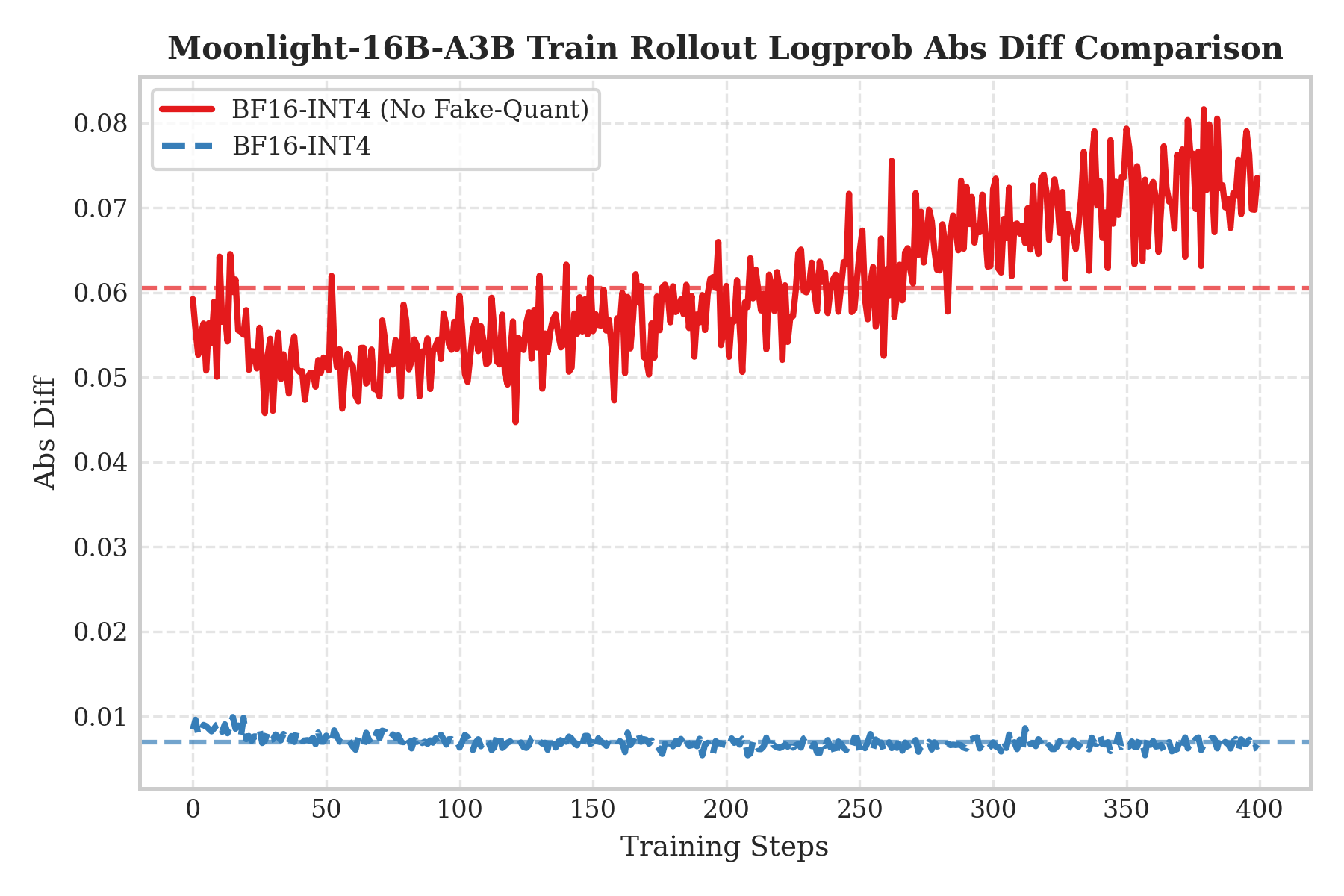
实验表明,QAT 训练后的权重已适应 INT4 噪声,移除量化会导致分布偏移;而无 QAT 直接 INT4 rollout 则误差显著更高。
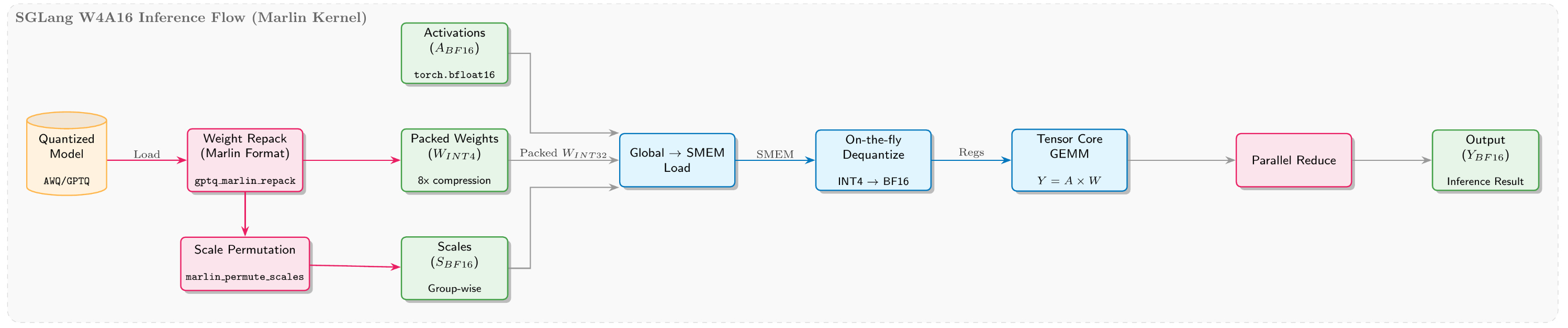
推理侧:SGLang W4A16 流水线
SGLang 侧权重处理流水线如下:

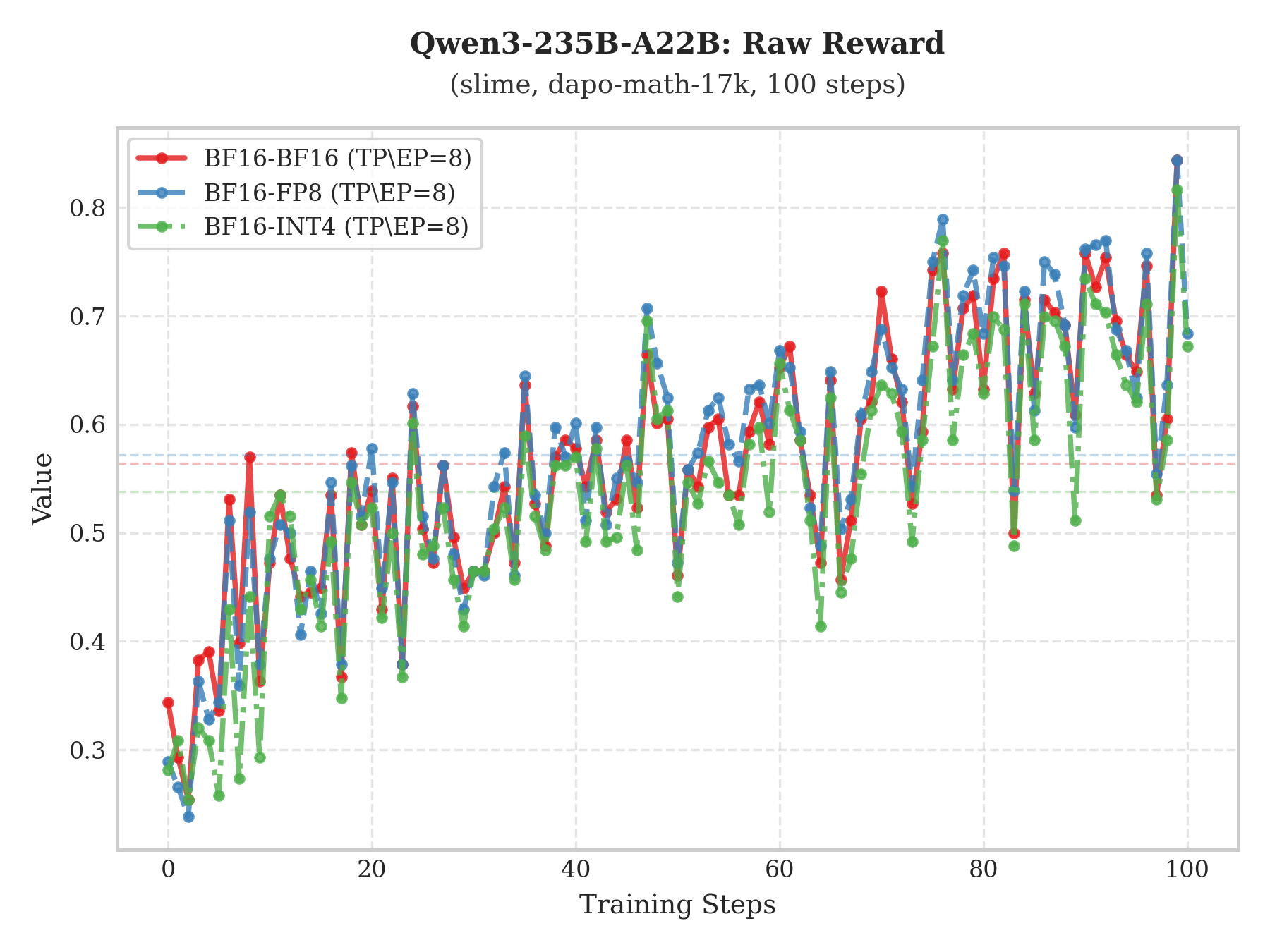
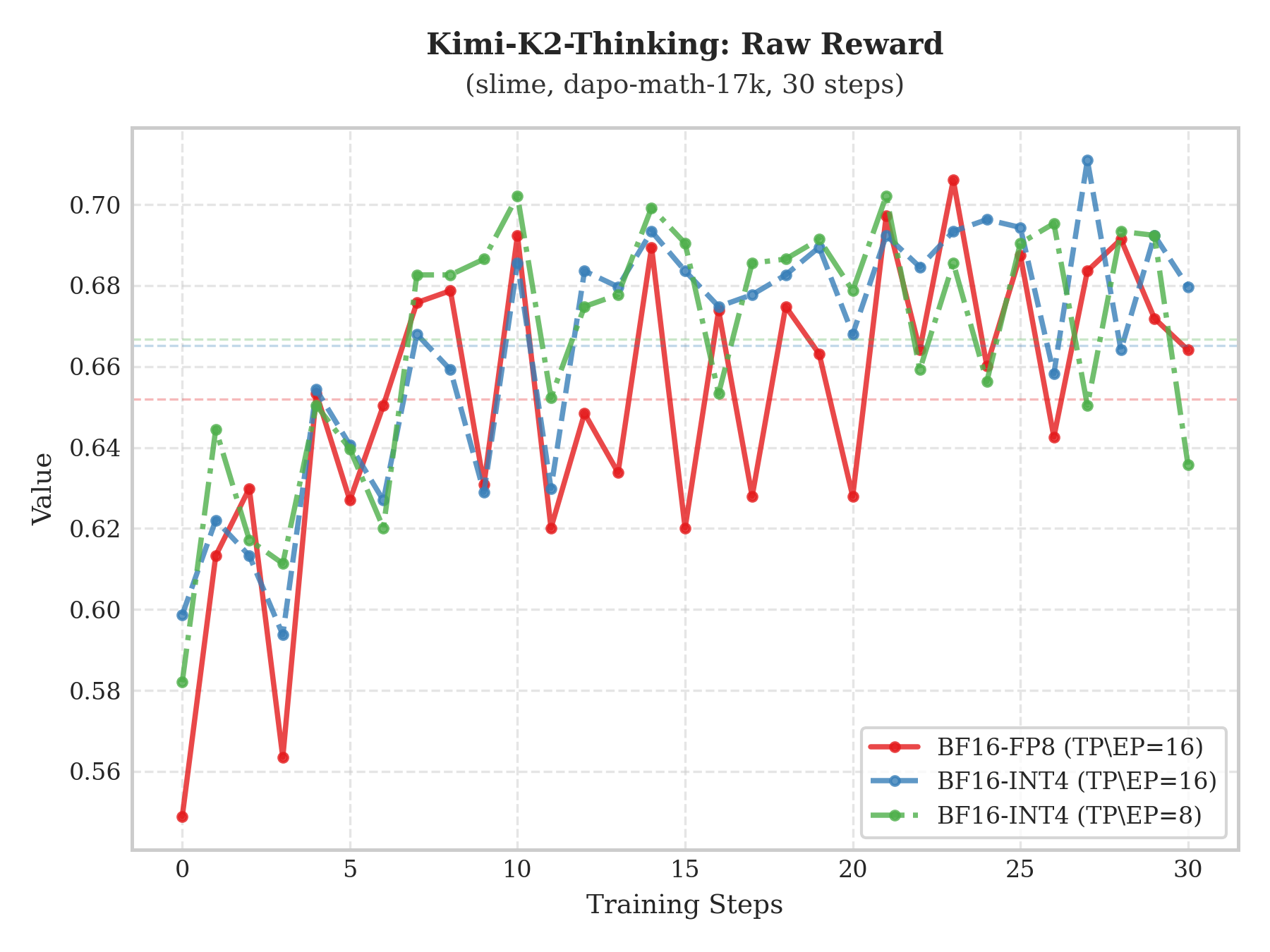
实验结果
多模型 Raw-Reward 及 AIME 评估对比显示,INT4 QAT 方案与 BF16 基线高度一致。
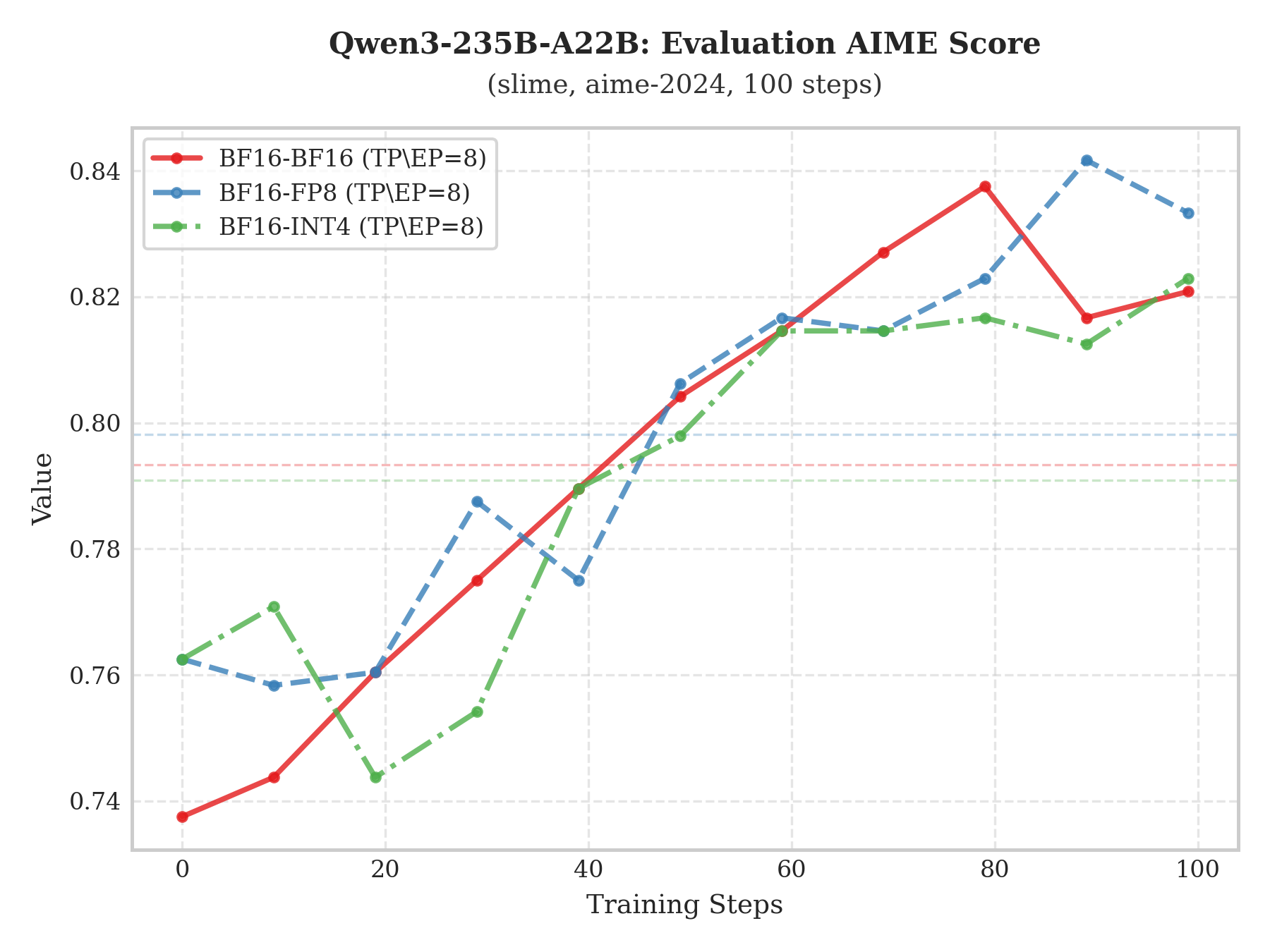
该项目由 SGLang RL 团队、InfiXAI 团队等联合完成,相关特性已同步至 slime 与 Miles 社区。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接