1. 问题:宽 EP 的必要性与脆弱性
为高效服务海量 Mixture-of-Experts (MoE) 模型,部署"宽" Expert Parallelism (EP) 策略——每个推理实例往往跨越 32 个或更多 GPU——已非可选,而是必需。这有两个关键原因:
- 最大化批次大小以降低成本:宽 EP 聚合巨量 VRAM,支持超大批次大小,这是生产环境中降低每 token 总体成本的核心驱动力。
- 最小化 TPOT 以提升速度:跨众多 GPU 扩展聚合内存带宽,直接降低 Time Per Output Token (TPOT),确保快速响应生成。
然而,EP 规模扩大引入严重可靠性瓶颈。传统 EP 架构中,"blast radius"(故障直径)与 EP 组大小成正比。由于专家严格绑定特定硬件,EP 越大,单一硬件故障或进程崩溃导致整个实例宕机的概率越高。原方案故障需全服务器重启,通常耗时数分钟,造成资源浪费、灾难性停机和用户体验中断。SGLang 先前 MoE 模式缺乏单实例内partial failure tolerance,亟需最小扰动解决方案。
2. 解决方案概述:Elastic EP 及其效果
为解决大规模 MoE 推理的脆弱性,我们将 Elastic EP 集成至 SGLang 框架。其核心是通过解耦专家与特定 GPU 的刚性映射,维护集群冗余专家,实现故障检测后即时重分布专家权重,并将 token 重路由至存活专家,确保部分故障容忍而不中断推理过程。(注:动态进程恢复也在 PR #15771 中积极开发中。)
效果
Elastic EP 大幅提升系统可靠性,同时不牺牲速度。
- 服务秒级恢复:在 4 节点(总 32 GPU,
ep_size=dp_size=32)上运行 DeepSeek V3.2,配置 256 个冗余专家,可容忍最多 16 个 rank 故障。模拟终止进程后,使用sglang.bench_serving基准测试,基于 EPLBManager 日志测量权重重分布与服务恢复时间。恢复后系统正确继续推理,虽资源减少导致吞吐降低,但中断时间均低于 10 秒——较传统 2-3 分钟重启减少 90%。
| 故障 rank 数量 | Elastic EP 中断时间 (秒) | 剩余 rank 吞吐 (tokens/sec) |
|---|---|---|
| 1 | 6.8 | 5552.41 |
| 2 | 6.5 | 5431.50 |
| 4 | 6.8 | 5265.12 |
| 8 | 6.4 | 4479.84 |
| 16 | 6.2 | 2825.44 |
- 零静态性能损失:在 4 节点(2 prefill 节点、2 decode 节点,各 8 GPU)评估 DeepSeek V3.2。Elastic EP(Mooncake EP)关键指标与标准 DeepEP 完全匹配。
| 系统 | 吞吐 (tokens/sec) | 平均 TTFT (ms) | 平均 TPOT (ms) |
|---|---|---|---|
| Elastic EP | 3560.21 | 19399.24 | 54.25 |
| Standard | 3626.38 | 21227.86 | 52.88 |
3. 详细结构修改
为实现此功能,SGLang 架构引入两大关键变更:
- Scheduler Layer(高层,调度导向):作为系统守门人,持续监控 Data Parallel (DP) rank 健康。若 rank 故障,立即过滤排除,确保新批次与请求仅分配至健康资源。从调度层面提供partial failure tolerance,零扰动。(对应 PR: #11657)
- Expert Parallel Layer(底层,执行导向):处理 EP 组内动态容错。实时调整专家到 GPU 映射,故障时即时跨存活成员重分布专家,确保 MoE 推理数学正确并匹配资源,避免执行中断。(对应 PRs: #10423, #10606, #17374, #12068)
这两层合力将脆弱 MoE 管道转化为高弹性引擎。
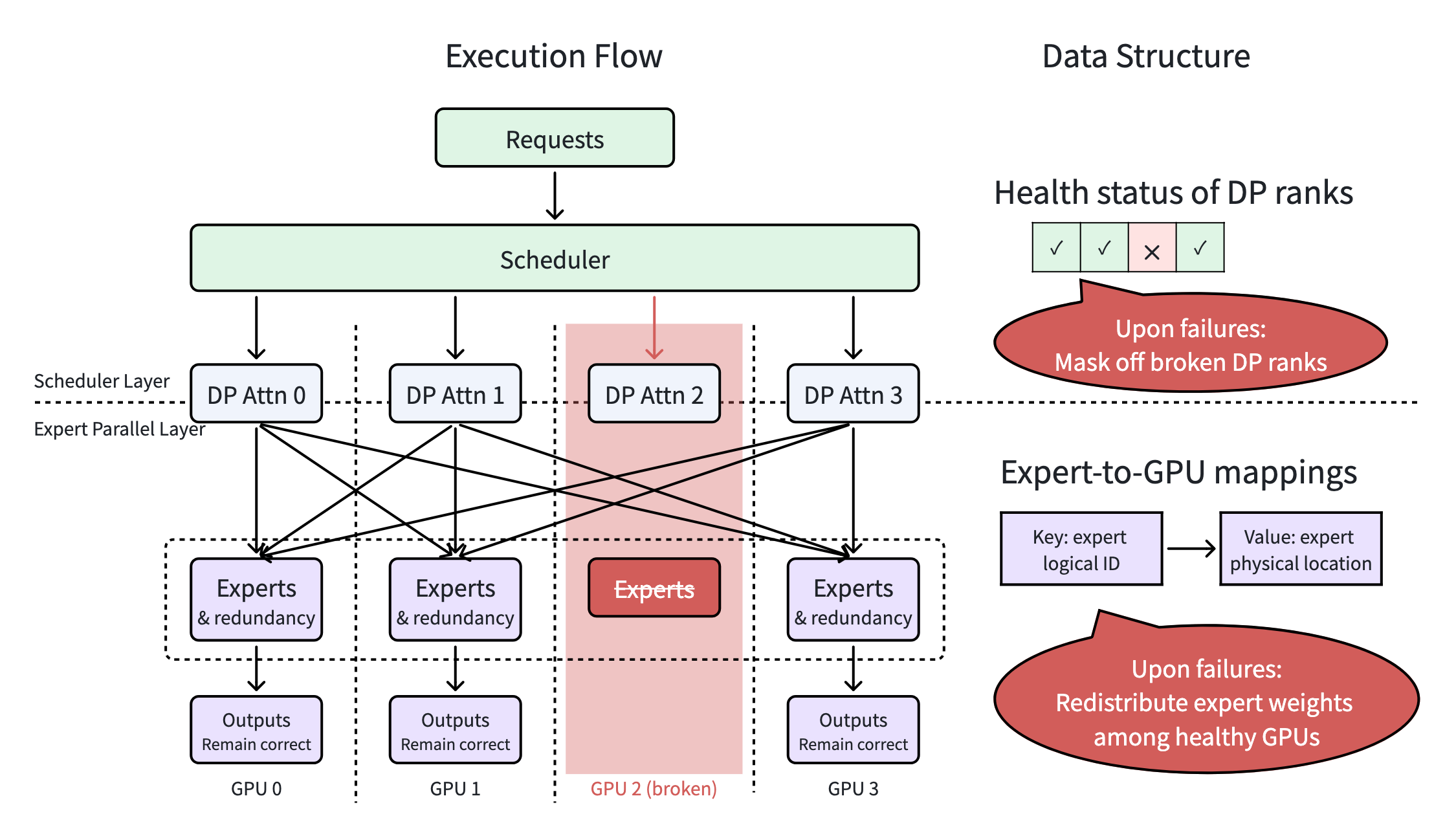
图:Elastic EP 系统图(4 GPU 案例)。
4. Mooncake 的作用:助力 Elastic EP
有效实现 Elastic EP 需高弹性通信库,支持动态拓扑变更并确保部分故障下 MoE 推理数学正确。Mooncake EP 正为此设计,作为容错后端与 EP 通信核心,在 PyTorch 生态广受认可。其关键能力包括:
- 弹性通用 Collective:确保 broadcast、allgather 等标准原语严格容错。
- 专用 EP 原语:针对 dispatch 和 combine 等 EP 必需原语提供容错,管理 MoE 稀疏激活。
- 高性能 RDMA 与快速故障检测:充分利用 GPU Direct RDMA,实现高吞吐低延迟 token 分发,并基于网络控制的超时机制快速检测故障。
- 无缝 SGLang 集成:虽底层网络复杂,但与 SGLang 执行流和调度逻辑即插即用,无需大规模重构即解锁部分故障容忍。
5. 启用 Elastic EP
启动 SGLang 服务器时,使用以下参数启用 Elastic EP:
--elastic-ep-backend mooncake:启用 Mooncake 作为容错 torch distributed 后端。--moe-a2a-backend mooncake:启用 Mooncake 作为 EP 通信后端。--mooncake-ib-device <comma-separated-ib-device-list>:指定 Mooncake 通信 IB 设备。--ep-num-redundant-experts <num>:设置冗余专家数,值越高容忍故障越多。--disable-custom-all-reduce:禁用默认自定义 all-reduce。--enable-elastic-expert-backup:启用内存中专家权重备份,支持故障场景快速恢复。
注:NIXL EP 是 NVIDIA Dynamo Team 在 Elastic EP 框架下的近期实现,可通过 --moe-a2a-backend nixl 试用。
致谢
感谢社区贡献者:SGLang 核心团队(Shangming Cai 等)、Mooncake 团队(Xun Sun 等)、Volcano Engine、Approaching AI、JD.com、Aliyun,以及 NVIDIA Dynamo Team。
链接
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接