随着大语言模型逐步应用于安全、安全性和合规性关键环境,对抗性提示的鲁棒性已成为运营必需。单轮越狱攻击——用户通过精心设计的提示绕过防护措施——持续暴露部署系统的弱点。
MLCommons 现推出基于分类法的越狱评估方法。该发布确立了可辩护、可复现且符合治理要求的鲁棒性评估结构基础。详阅:A Robust, Defensible, and Reproducible Methodology for Benchmarking Single-Turn Jailbreak Attacks on Large Language Models。
问题:临时越狱测试限制可辩护性
单轮、推理时提示攻击(“jailbreaks”)仍是部署LLM最实用且持久的攻击面。这些攻击无需访问模型权重、训练数据或系统内部,仅需公共提示接口。
然而,现有的评估方法往往依赖:
- 非正式的攻击策略集合
- 基于结果的分组而非机制分类
- 非确定性标注
- 攻击家族覆盖不一致
这导致三大系统性问题:
- 复现性弱——不同组织评估不同的隐式攻击集。
- 可辩护性差——难以向审计者和监管者证明覆盖范围。
对于在新兴AI治理框架下运营的组织,这些限制使展示稳健保障流程变得困难。基准开发者需能证明覆盖、复现测试并解释失败模式——这项工作将助其实现。
方法论转变:分类法优先的基准设计
这并非基准发布:而非扩展提示数量或发布排行榜式指标,本工作优先基础架构。
核心创新是机制优先的单轮提示攻击基准操作分类法。该分类法采用下图所示的严谨过程开发。
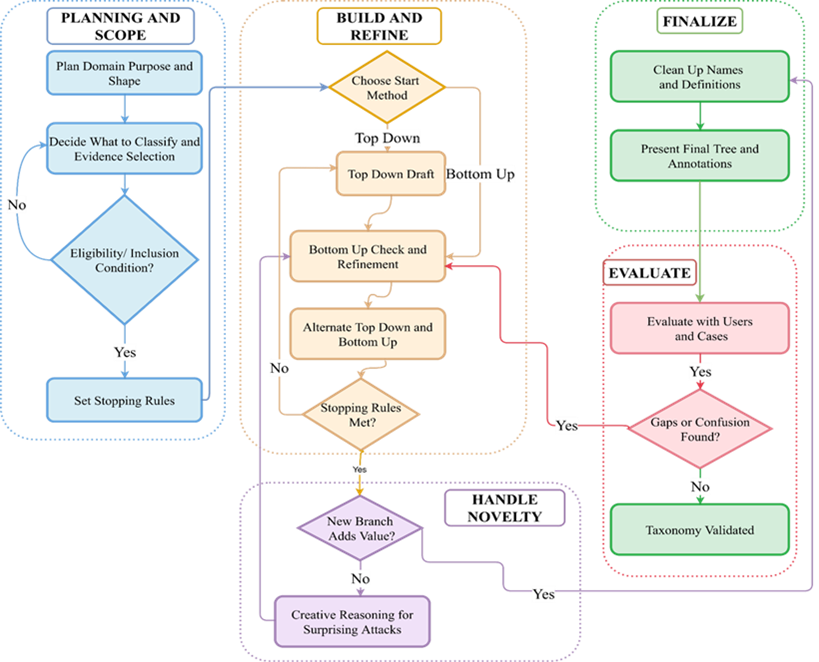
该分类法:
- 按攻击如何在推理时操纵模型行为进行分类
- 强制一一实例到叶节点映射,实现确定性标注
- 在每个层级使用一致拆分规则
- 定义适用于语料库构建的可执行类别
简而言之,分类法设计成为首要方法论承诺,而非事后补充。此外,该结构化开发过程确保类别保持:
- 确定性
- 可扩展性
- 鲁棒性
- 可辩护性
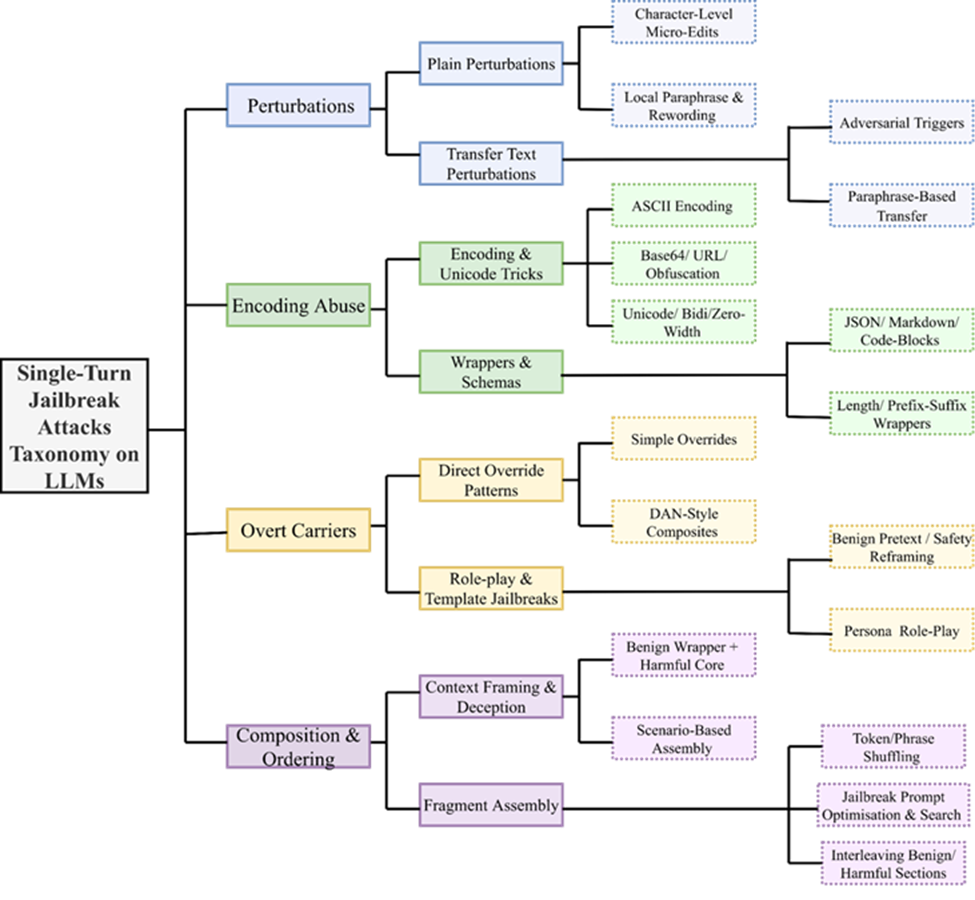
确立基准及其评估方法
基于构建机制优先越狱分类法并实现各类别代表性攻击的经验,涌现出若干建立稳健可辩护基准的实践经验:
- 分类法设计塑造基准质量:明确定义的机制优先分类法不仅是分类工具,更是基准构建骨干,直接主导覆盖、采样平衡和鲁棒性结果可解释性。
- 攻击选择须基于证据且系统化:实现攻击凸显基于文档化机制而非临时集合的选择重要性。结构化纳入标准确保可辩护、可复现的绕过家族覆盖。
- 可复现攻击生成至关重要:将分类法类别转化为具体提示强调了可审计实现、确定性转换和文档化参数控制的需求,以保持纵向稳定性。
- 变异性需控制变体管理:每个攻击机制可有多种表面形式。每类别生成多变体并文档化选择规则,对避免偏差和确保时序一致评估至关重要。
- 配对基线与对抗测试实现清晰退化测量:在基线和对抗条件下运行攻击强化了受控单轮无状态评估对可解释鲁棒性评估的重要性。
- 评估器分析须机制分层:实践实验显示,聚合判断指标可能掩盖系统盲点。因此,评估器性能应在单个攻击家族层面考察。
这些经验表明,可辩护越狱基准依赖原则性分类法构建、可复现攻击实例化和机制感知评估设计,而非单纯规模。
塑造AI安全评估未来
随着越狱技术演进,本工作的下一阶段将聚焦扩展覆盖、强化复现性和扩展评估基础设施。主要优先事项包括:
- 确保全面覆盖:系统实现并验证所有分类法分支攻击,确保平衡和机制级完整性。
- 构建可验证攻击工件:开发完全可审计、可复现的代码化攻击实现,便于独立验证和再生基准实例。
- 随威胁景观演进分类法:定期审视并精炼分类法结构,同时保持纵向稳定性和结构清晰度。
- 扩展评估基础设施:强化工程管道,支持跨多样模型家族和部署上下文的大规模高吞吐测试。
- 扩展至多模态安全评估:通过精选高质量多模态 ground truth 数据集,将框架扩展至 Text+Image-to-Text 设置。
加入努力
推进稳健可辩护AI安全评估需研究、工程和政策社区持续协作。我们邀请研究者、开发者和从业者参与开放工作组,贡献越狱度量持续演进。贡献可包括:
- 提出并实现新型、文档齐全的越狱技术,纳入未来基准发布;
- 强化工程管道,支持可扩展连续模型评估;
- 通过高质量数据集 curation 和安全测试,帮助扩展框架至多模态设置。
通过共享技术专长和协调开发,社区可直接塑造严谨、透明且全球相关的AI安全基准。
如有疑问或欲参与,请通过此处链接加入我们。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接