强化学习(RL)迅速成为现代基础模型开发的核心阶段。尽管大规模预训练仍然重要,但当今最强大的模型依赖于后训练技术来提高推理、工具使用和多轮交互能力。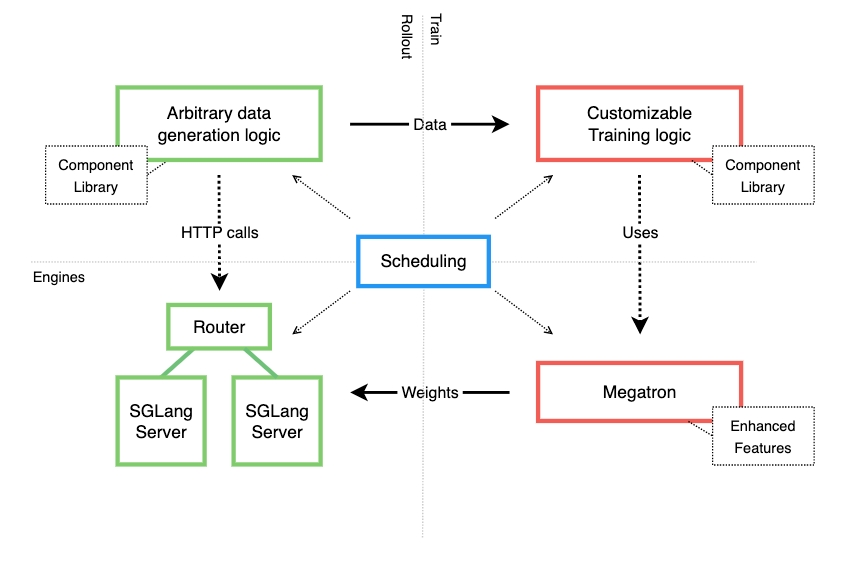
介绍Miles
Miles是一个开源RL框架,专为语言和多模态模型的大规模后训练设计。它构建在SGLang和Slime RL生态系统之上,目标是生产级RL管道。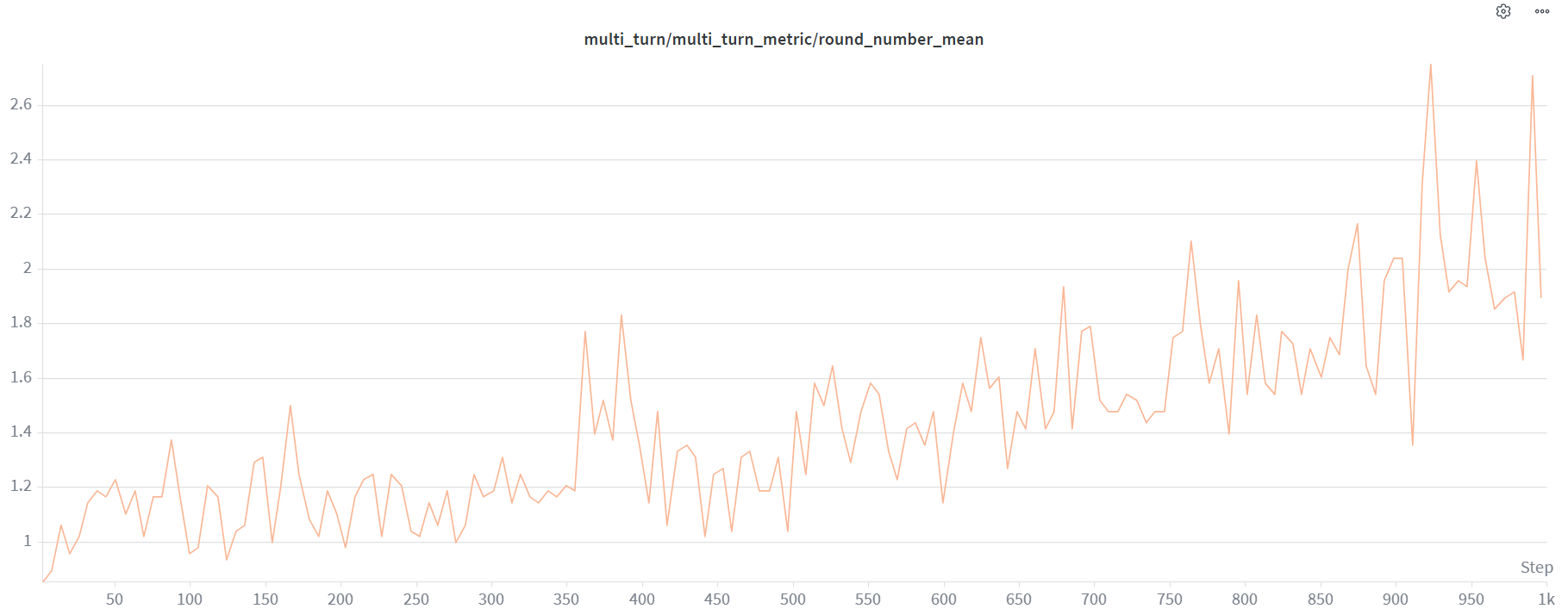
Miles提供的基础设施包括:
- 分布式rollout生成
- 策略优化(GRPO / PPO)
- 基于策略的RL训练循环
- 基于Ray的编排
- 与Megatron-LM和SGLang集成;支持其他后端如FSDP
为什么RL工作负载适合AMD Instinct GPU
RL工作负载与预训练的一个关键区别在于:rollout生成主导了计算。现代RL训练可能花费70-90%的GPU时间在数千个并行环境中生成长序列。这使得内存容量和带宽成为关键性能因素。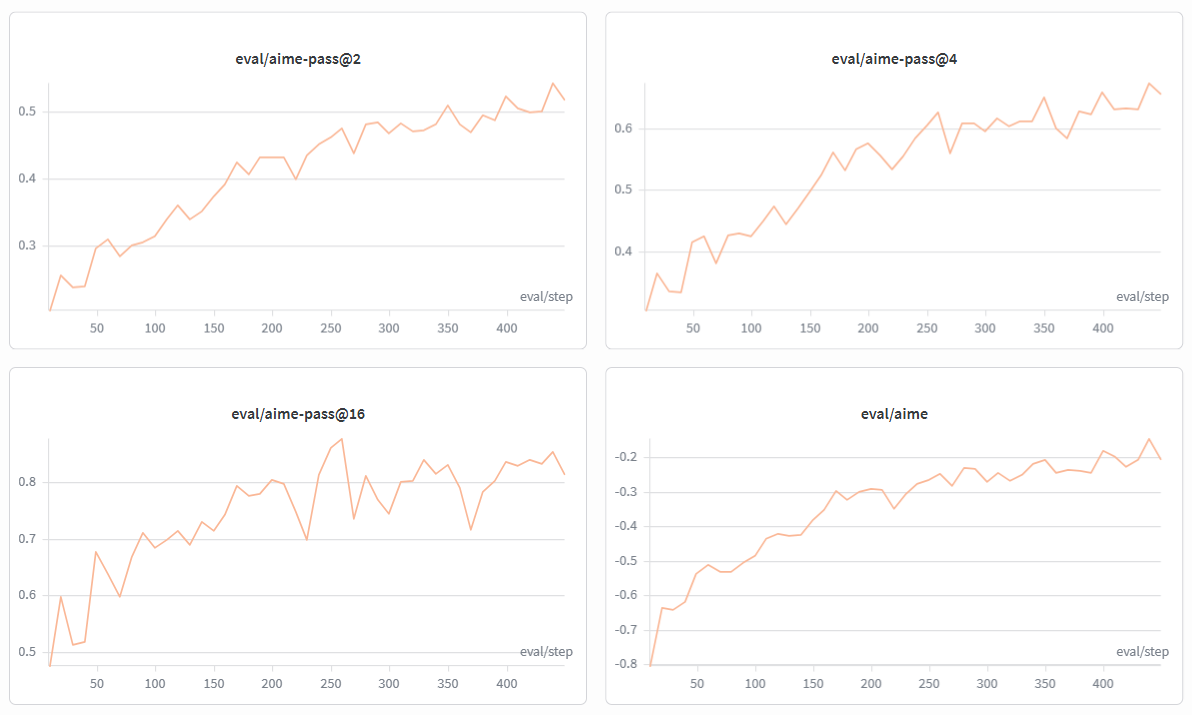
在ROCm上的Miles RL系统架构
Miles是一个解耦的RL训练架构,将rollout生成(SGLang)与模型优化(Megatron)分开,并通过调度器进行协调以实现可扩展的后训练。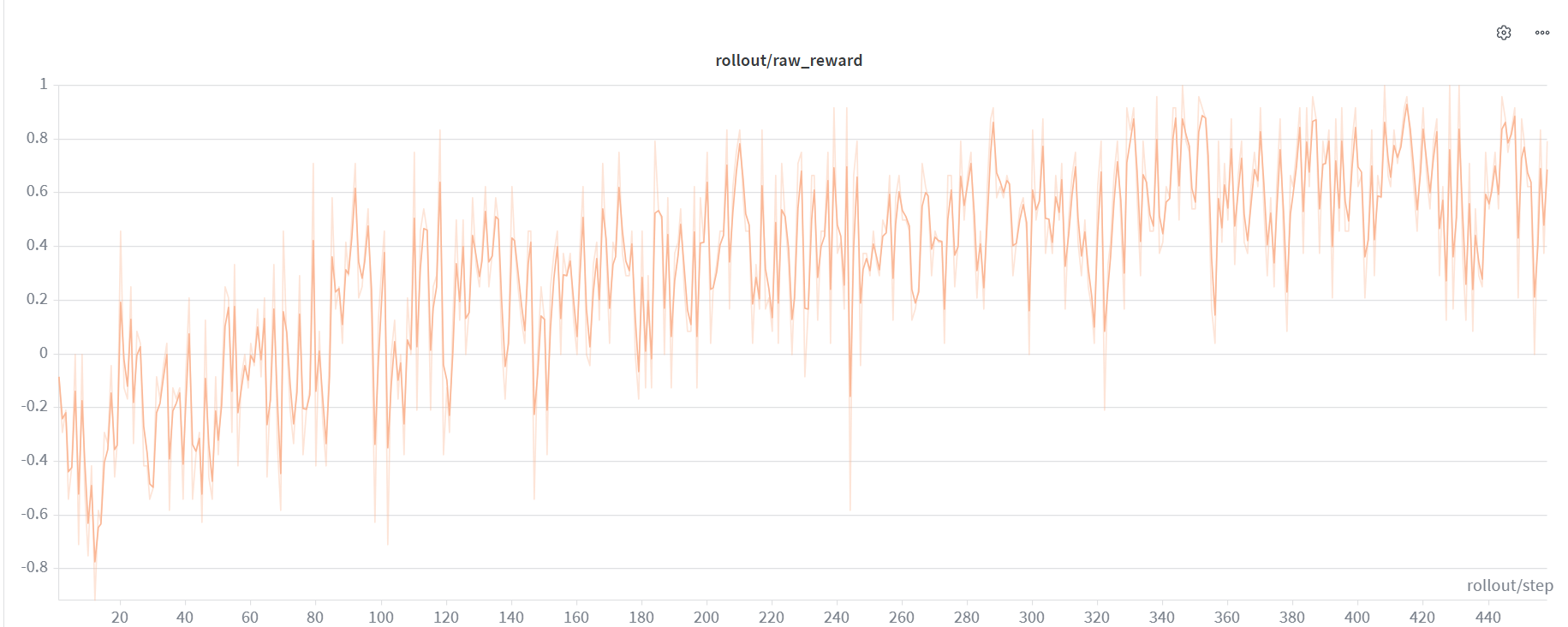
开始:在AMD GPU上运行Miles
Miles提供了一个ROCm就绪的工作流,包含预构建的容器,使您能够以最小的设置运行完整的RL管道。选择与您的GPU代相匹配的容器:
- MI300X:
rlsys/miles:rocm7-MI300-sglang0.5.9-latest - MI350X / MI355X:
rlsys/miles:rocm7-MI350-355-sglang0.5.9-latest
启动Miles ROCm容器
# MI350X / MI355X:
# export MILES_IMAGE=rlsys/miles:rocm7-MI350-355-sglang0.5.9-latest
# MI300X:
export MILES_IMAGE=rlsys/miles:rocm7-MI300-sglang0.5.9-latest
docker pull $MILES_IMAGE
docker run -it \
--device /dev/dri --device /dev/kfd \
--group-add video --cap-add SYS_PTRACE \
--security-opt seccomp=unconfined --privileged \
-v $HOME:$HOME --shm-size 128G \
--ulimit memlock=-1 --ulimit stack=67108864 \
-w $PWD $MILES_IMAGE /bin/bash安装Miles并下载资源
git clone https://github.com/radixark/miles.git
cd miles
git checkout 90b66b542b38c3b67537bb99a505bb707ebfcf6d
pip install -e .实验与性能
代理任务训练:多轮互动
多轮互动代理正迅速成为现实AI系统的默认接口。大多数实际任务需要多步骤推理,代码/工具帮助代理验证其工作/使用反馈在轨迹中途纠正错误。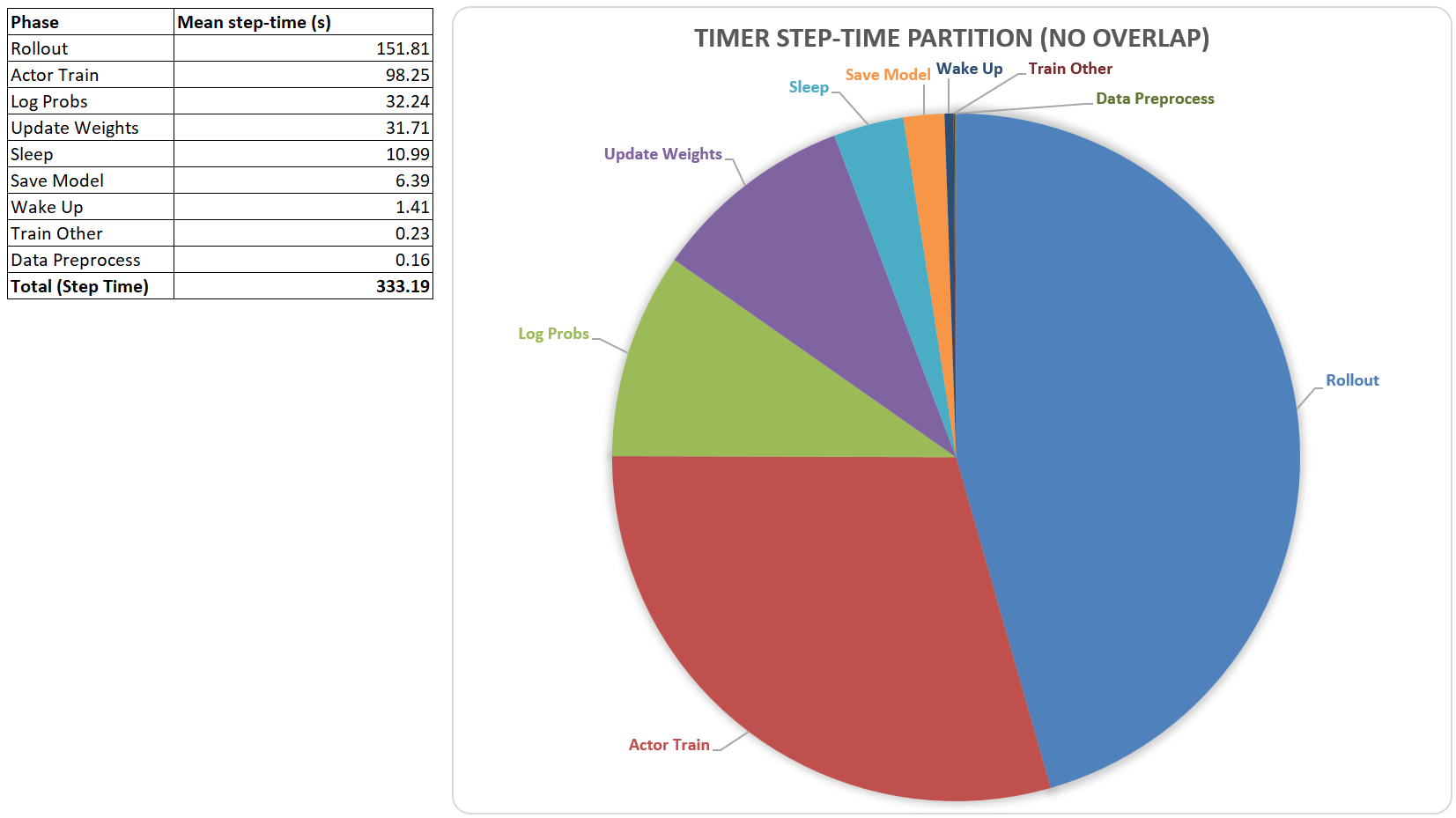
在本节中,我们展示了一个多轮示例,Qwen2.5-32B训练使用Python解释器处理高中数学风格问题。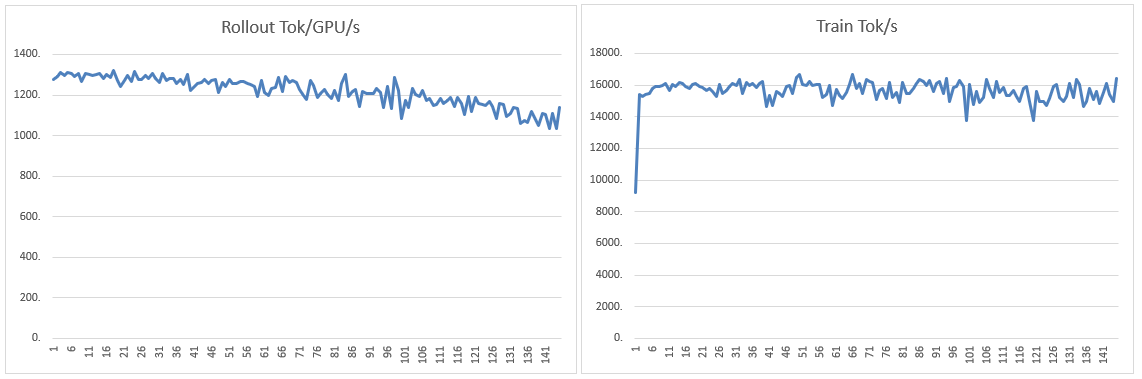
性能
在单个8-GPU AMD Instinct MI300X节点上,我们使用GRPO(32×8采样,8k响应上限,全局批次256)训练了Qwen3-30B-A3B,使用TP4/EP8序列并行Megatron设置,且无KL损失项。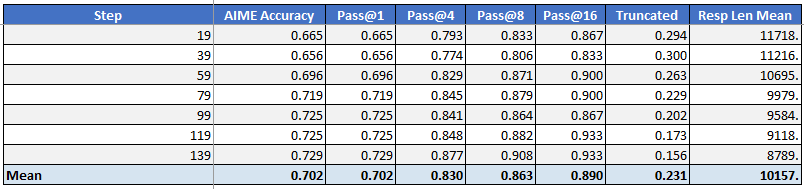
AMD上的功能支持路线图
今天,核心Miles功能已在AMD上全面支持,包括:
- GRPO训练
- 模型和数据并行性
- 动态批处理
- 同时支持Megatron和FSDP后端
- 部分rollout
- Miles路由器
我们的目标不仅是功能对等,还包括与Miles路线图演变一致的持续性能和能力改进。
总结
强化学习现在是基础模型开发的核心阶段。通过对Miles的ROCm支持,AMD GPU用户可以在MI300/350级集群上运行现代RL管道,包括分布式rollout和GRPO训练。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接