SGLang团队与NVIDIA在多代GPU上密切合作,为大规模Mixture of Expert (MoE)推理模型部署解锁阶跃式推理性能提升。继先前在SemiAnalysis InferenceMAXv1基准上Blackwell B200对比Hopper H200实现4倍加速后,我们现将势头延续至Blackwell Ultra。在GB300 NVL72上,SGLang在最新InferenceXv2基准中较H200实现高达25倍性能提升。此外,在不到4个月内,我们将SGLang在GB200 NVL72上的InferenceXv2性能提升高达8倍。这些性能飞跃得益于SGLang开发者和NVIDIA工程团队的紧密协作,直接转化为更低延迟、更高吞吐量以及显著降低的大规模MoE推理模型部署每token成本。
NVIDIA GB300 NVL72搭载Blackwell Ultra GPU
NVIDIA GB200 NVL72已确立为最强大的扩展式数据中心GPU平台,将72个Blackwell GPU连接成单一高带宽域,带宽达130 TB/s。这种架构特别适合MoE模型,后者依赖低延迟all-to-all通信实现Wide Expert Parallel执行,以及在prefill与decode GPU间的高速KV-cache迁移。
NVIDIA GB300 NVL72在此基础上引入Blackwell Ultra GPU,带来多项关键增强:
- 1.5倍峰值NVFP4吞吐量:更新后的Tensor Cores使每时钟FP4吞吐量较Blackwell提升1.5倍,加速MoE专家和稠密层的math-bound GEMM操作。
- 2倍注意力Softmax吞吐量:升级的特函数单元(SFU)使Softmax操作吞吐量翻倍,这是注意力层关键组件。
- 1.5倍更大HBM3e容量:Blackwell Ultra集成更高容量的12-Hi HBM3e栈(较8-Hi提升),支持更大模型和批次大小,无需CPU卸载。
结合72-GPU NVL72大规模域,这些能力提升MoE GEMM吞吐量、加速注意力Softmax,并支持disaggregated推理设置中的大decode批次。
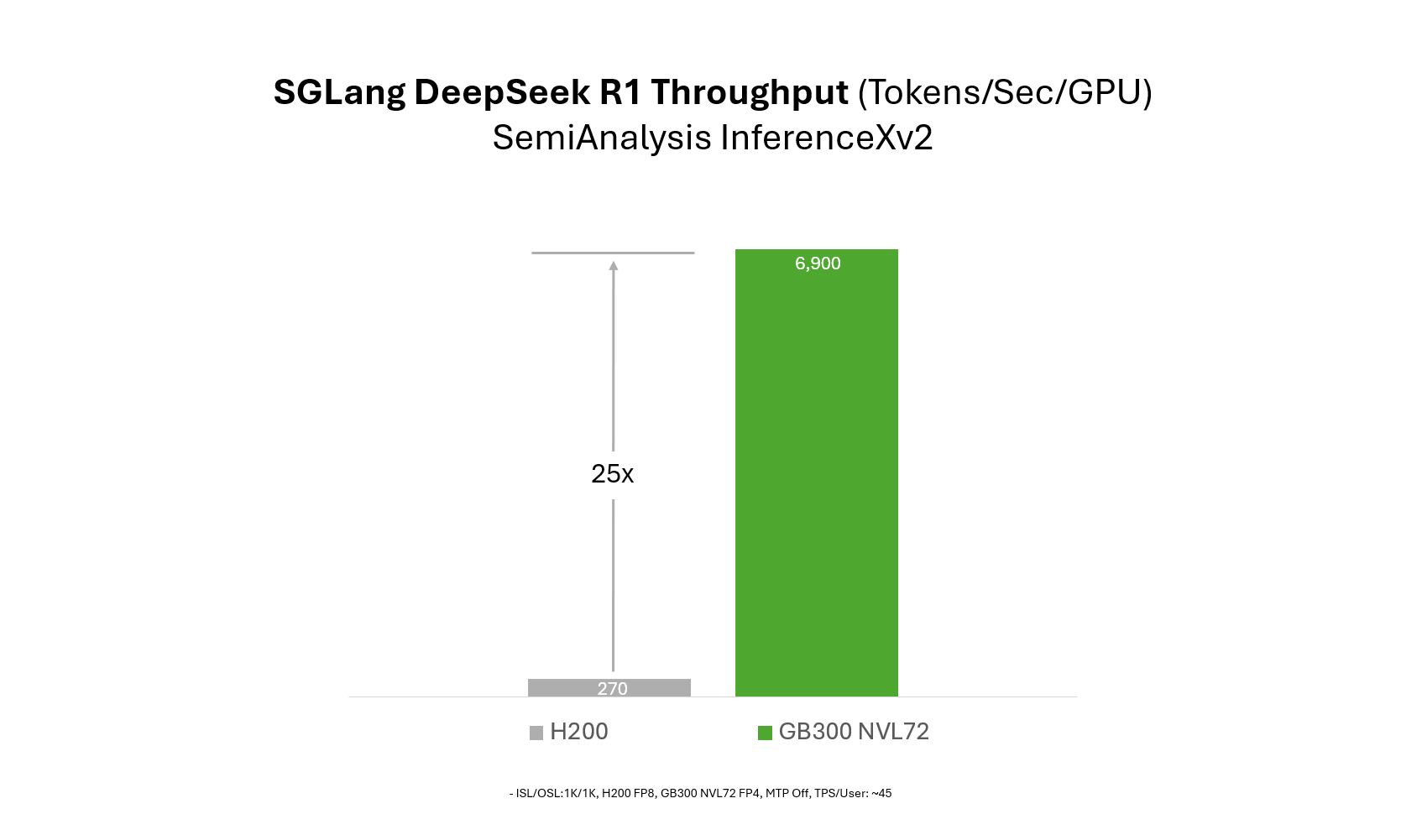
GB300 NVL72上SGLang性能提升25倍
SemiAnalysis InferenceX(前身为InferenceMAX)是一个持续运行的基准套件,在数百加速器上评估流行开源框架和模型的真实推理性能,实时结果见inferencemax.ai。InferenceMAXv1发布展示了SGLang在Blackwell对比Hopper上为DeepSeek R1提取高达4倍性能。
在最新InferenceXv2中,NVIDIA的GB300 NVL72机架级系统已加入基准矩阵。借助与NVIDIA的持续协作,SGLang在GB300 NVL72上运行DeepSeek R1的性能较H200提升高达25倍。这一提升结合Blackwell Ultra架构进步与SGLang在推理栈中的针对性软件和内核优化。
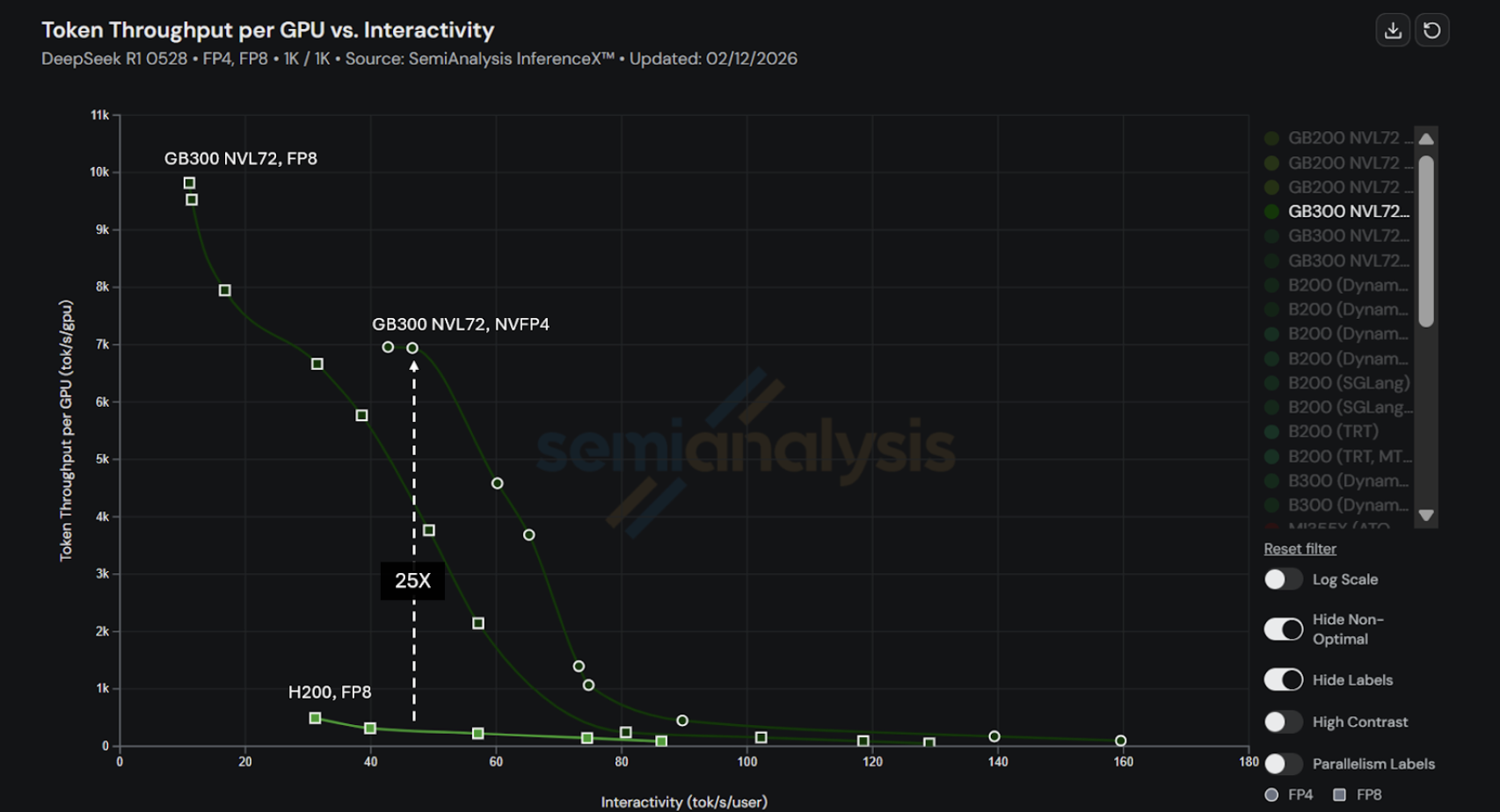
请注意,用于25倍提升的H200基线采用50 TPS/user交互性,反映低延迟用例。在无延迟约束下,H200可实现类似吞吐量(如先前博客所述)。本博客选用50 TPS/user作为比较点,以体现合理延迟场景。
针对Blackwell Ultra的推理优化
为充分利用GB300 NVL72上Blackwell Ultra的能力,SGLang引入多项优化,涵盖低精度数据格式、内核设计及disaggregated serving:
- MoE和稠密层的NVFP4 GEMM:采用NVFP4精度,降低内存带宽压力,利用Blackwell Ultra更高FP4 Tensor Core吞吐量,并将token分发通信流量减半。这缩小内存中权重占用,释放空间给更大KV cache,提升并发度。
- 计算-通信重叠:摒弃传统Two-Batch overlapping (TBO),采用针对NVL72更高互连带宽的单批次重叠策略。实际中,这允许以producer-consumer模式并发运行通信与down-GEMM计算,并在额外CUDA流上重叠共享专家计算,最小化空闲时间。
- NVIDIA Dynamo用于disaggregated推理:为prefill-decode分离,我们集成NVIDIA Dynamo,一个开源分布式推理serving引擎。其模块化设计允许深度耦合KV-aware路由器与SGLang的HiCache radix树,并暴露如NIXL和Mooncake等灵活KV cache传输后端,匹配不同部署场景。
这些优化使推理软件栈与Blackwell Ultra特性对齐,推动更高利用率,将硬件能力转化为实际吞吐量。
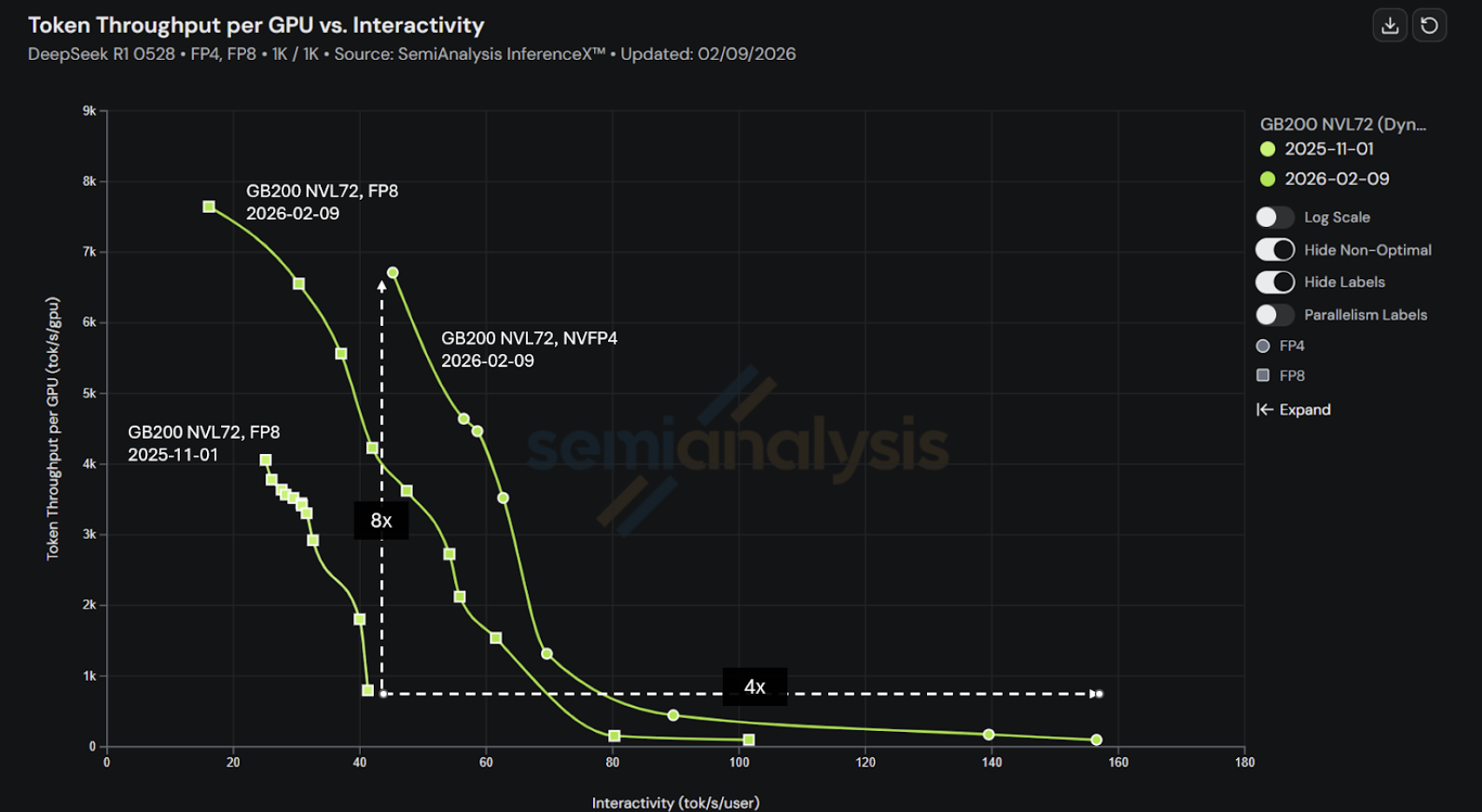
GB200 NVL72上性能提升8倍
虽然GB300 NVL72是我们新的性能旗舰,但我们持续优化SGLang在GB200 NVL72上。较4个月前的InferenceMAXv1提交,最新v2版本采用低精度NVFP4,在高吞吐模式下每GPU tokens提升高达8倍,在高交互模式下每用户tokens提升高达4倍,实现更好token经济性和终端用户体验。这些结果验证了NVIDIA与SGLang工程协作的力量。
展望未来
我们与NVIDIA的路线图不止于InferenceXv2的25倍里程碑。下一阶段聚焦:
- 在GB300 NVL72上启用MTP,进一步对比Hopper提升性能。
- 持续优化GB300 NVL72,针对延迟敏感和高吞吐部署。
- 为Qwen模型家族(包括最新Qwen 3.5)在Blackwell和Blackwell Ultra上调优SGLang。
- 将这些优化带至未来NVIDIA Vera Rubin NVL72系统。
通过持续与NVIDIA协作,SGLang旨在持续推动推理性能前沿,降低下一波前沿推理模型部署成本。
致谢
衷心感谢以下团队和合作者:
NVIDIA团队:Amr Elmeleegy, Cyrus Chang, Elvis Chen, Grace Ho, Hao Lu, Ishan Dhanani, Jinyan Chen, Julien Lin, Kaixi Hou, Kedar Potar, Kyle Liang, Lee Nau, Mathew Wicks, Nicolas Castet, Pen Chung Li, Po-Han Huang, Qixiang Lin, Shu Wang, Shu-Hao Yeh, Trevor Morris, Weiliang Liu, Xuting Zhou, Yangmin Li 等众多成员。
SGLang核心团队及社区贡献者:Baizhou Zhang, Jingyi Chen, Liangsheng Yin, Shangming Cai, Rain Jiang, Cheng Wan, Qiaolin Yu, Lianmin Zheng。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接